 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeRF2Points: Large-Scale Point Cloud Generation From Street Views' Radiance Field Optimization
Apr 07, 2024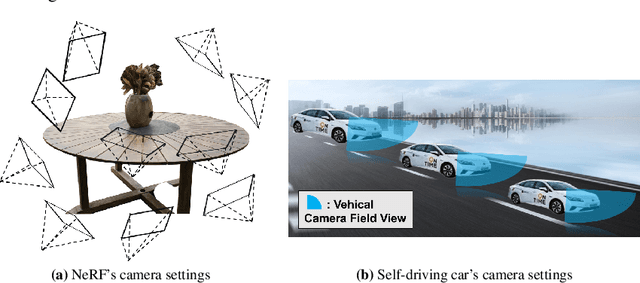
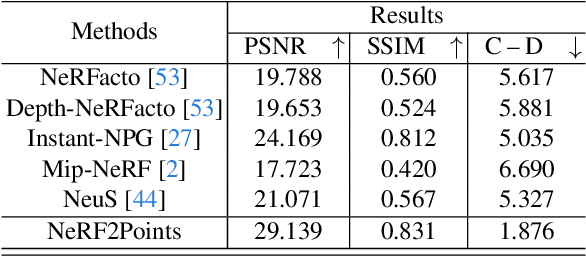

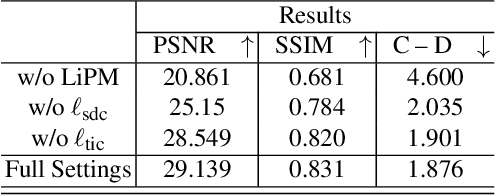
Neural Radiance Fields (NeRF) have emerged as a paradigm-shifting methodology for the photorealistic rendering of objects and environments, enabling the synthesis of novel viewpoints with remarkable fidelity. This is accomplished through the strategic utilization of object-centric camera poses characterized by significant inter-frame overlap. This paper explores a compelling, alternative utility of NeRF: the derivation of point clouds from aggregated urban landscape imagery. The transmutation of street-view data into point clouds is fraught with complexities, attributable to a nexus of interdependent variables. First, high-quality point cloud generation hinges on precise camera poses, yet many datasets suffer from inaccuracies in pose metadata. Also, the standard approach of NeRF is ill-suited for the distinct characteristics of street-view data from autonomous vehicles in vast, open settings. Autonomous vehicle cameras often record with limited overlap, leading to blurring, artifacts, and compromised pavement representation in NeRF-based point clouds. In this paper, we present NeRF2Points, a tailored NeRF variant for urban point cloud synthesis, notable for its high-quality output from RGB inputs alone. Our paper is supported by a bespoke, high-resolution 20-kilometer urban street dataset, designed for point cloud generation and evaluation. NeRF2Points adeptly navigates the inherent challenges of NeRF-based point cloud synthesis through the implementation of the following strategic innovations: (1) Integration of Weighted Iterative Geometric Optimization (WIGO) and Structure from Motion (SfM) for enhanced camera pose accuracy, elevating street-view data precision. (2) Layered Perception and Integrated Modeling (LPiM) is designed for distinct radiance field modeling in urban environments, resulting in coherent point cloud representations.
Learning Triangular Distribution in Visual World
Dec 04, 2023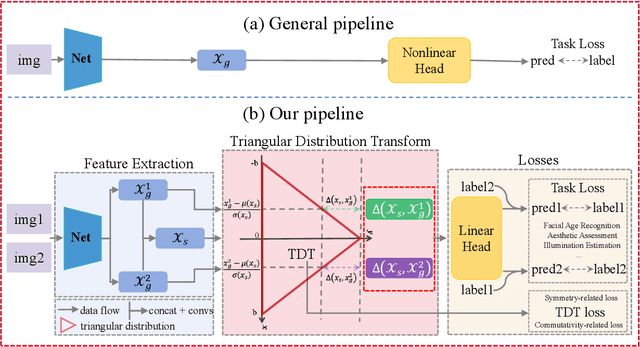

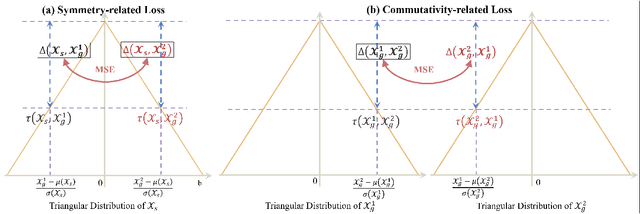
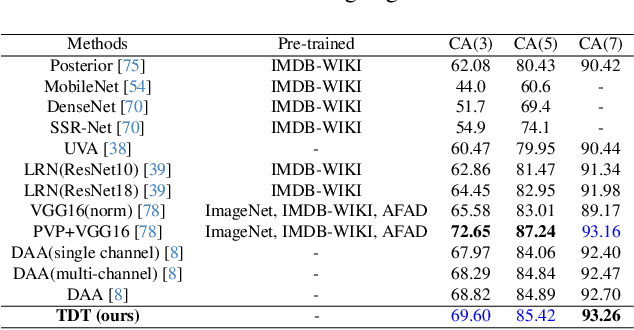
Convolution neural network is successful in pervasive vision tasks, including label distribution learning, which usually takes the form of learning an injection from the non-linear visual features to the well-defined labels. However, how the discrepancy between features is mapped to the label discrepancy is ambient, and its correctness is not guaranteed. To address these problems, we study the mathematical connection between feature and its label, presenting a general and simple framework for label distribution learning. We propose a so-called Triangular Distribution Transform (TDT) to build an injective function between feature and label, guaranteeing that any symmetric feature discrepancy linearly reflects the difference between labels. The proposed TDT can be used as a plug-in in mainstream backbone networks to address different label distribution learning tasks. Experiments on Facial Age Recognition, Illumination Chromaticity Estimation, and Aesthetics assessment show that TDT achieves on-par or better results than the prior arts.
FemtoDet: An Object Detection Baseline for Energy Versus Performance Tradeoffs
Jan 17, 2023Efficient detectors for edge devices are often optimized for metrics like parameters or speed counts, which remain weak correlation with the energy of detectors. However, among vision applications of convolutional neural networks (CNNs), some, such as always-on surveillance cameras, are critical for energy constraints. This paper aims to serve as a baseline by designing detectors to reach tradeoffs between energy and performance from two perspectives: 1) We extensively analyze various CNNs to identify low-energy architectures, including the selection of activation functions, convolutions operators, and feature fusion structures on necks. These underappreciated details in past works seriously affect the energy consumption of detectors; 2) To break through the dilemmatic energy-performance problem, we propose a balanced detector driven by energy using discovered low-energy components named \textit{FemtoDet}. In addition to the novel construction, we further improve FemtoDet by considering convolutions and training strategy optimizations. Specifically, we develop a new instance boundary enhancement (IBE) module for convolution optimization to overcome the contradiction between the limited capacity of CNNs and detection tasks in diverse spatial representations, and propose a recursive warm-restart (RecWR) for optimizing training strategy to escape the sub-optimization of light-weight detectors, considering the data shift produced in popular augmentations. As a result, FemtoDet with only 68.77k parameters achieves a competitive score of 46.3 AP50 on PASCAL VOC and power of 7.83W on RTX 3090. Extensive experiments on COCO and TJU-DHD datasets indicate that the proposed method achieves competitive results in diverse scenes.
GuidedMix-Net: Semi-supervised Semantic Segmentation by Using Labeled Images as Reference
Dec 28, 2021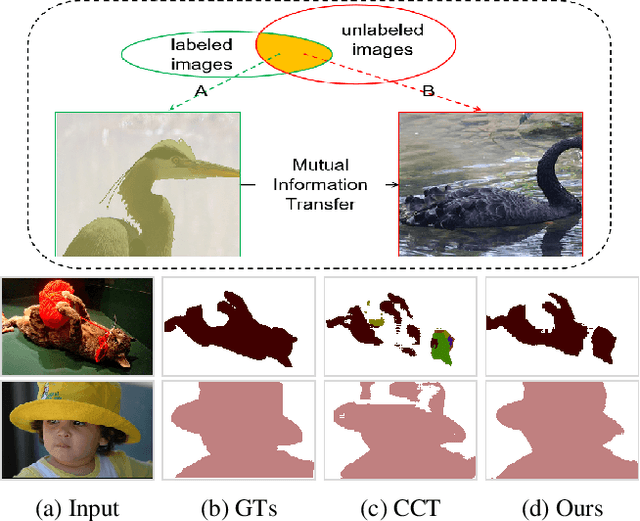

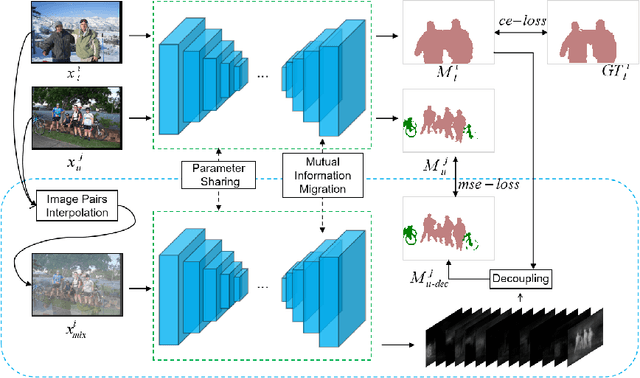

Semi-supervised learning is a challenging problem which aims to construct a model by learning from limited labeled examples. Numerous methods for this task focus on utilizing the predictions of unlabeled instances consistency alone to regularize networks. However, treating labeled and unlabeled data separately often leads to the discarding of mass prior knowledge learned from the labeled examples. %, and failure to mine the feature interaction between the labeled and unlabeled image pairs. In this paper, we propose a novel method for semi-supervised semantic segmentation named GuidedMix-Net, by leveraging labeled information to guide the learning of unlabeled instances. Specifically, GuidedMix-Net employs three operations: 1) interpolation of similar labeled-unlabeled image pairs; 2) transfer of mutual information; 3) generalization of pseudo masks. It enables segmentation models can learning the higher-quality pseudo masks of unlabeled data by transfer the knowledge from labeled samples to unlabeled data. Along with supervised learning for labeled data, the prediction of unlabeled data is jointly learned with the generated pseudo masks from the mixed data. Extensive experiments on PASCAL VOC 2012, and Cityscapes demonstrate the effectiveness of our GuidedMix-Net, which achieves competitive segmentation accuracy and significantly improves the mIoU by +7$\%$ compared to previous approaches.
GuidedMix-Net: Learning to Improve Pseudo Masks Using Labeled Images as Reference
Jun 30, 2021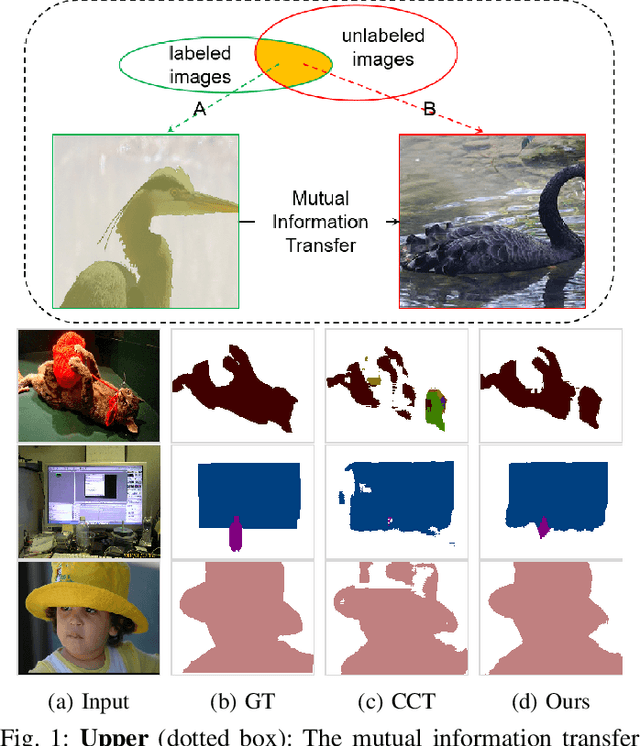


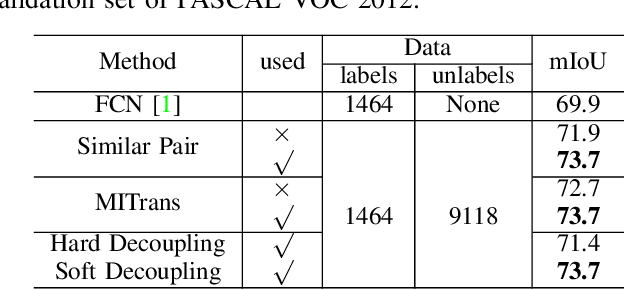
Semi-supervised learning is a challenging problem which aims to construct a model by learning from a limited number of labeled examples. Numerous methods have been proposed to tackle this problem, with most focusing on utilizing the predictions of unlabeled instances consistency alone to regularize networks. However, treating labeled and unlabeled data separately often leads to the discarding of mass prior knowledge learned from the labeled examples, and failure to mine the feature interaction between the labeled and unlabeled image pairs. In this paper, we propose a novel method for semi-supervised semantic segmentation named GuidedMix-Net, by leveraging labeled information to guide the learning of unlabeled instances. Specifically, we first introduce a feature alignment objective between labeled and unlabeled data to capture potentially similar image pairs and then generate mixed inputs from them. The proposed mutual information transfer (MITrans), based on the cluster assumption, is shown to be a powerful knowledge module for further progressive refining features of unlabeled data in the mixed data space. To take advantage of the labeled examples and guide unlabeled data learning, we further propose a mask generation module to generate high-quality pseudo masks for the unlabeled data. Along with supervised learning for labeled data, the prediction of unlabeled data is jointly learned with the generated pseudo masks from the mixed data. Extensive experiments on PASCAL VOC 2012, PASCAL-Context and Cityscapes demonstrate the effectiveness of our GuidedMix-Net, which achieves competitive segmentation accuracy and significantly improves the mIoU by +7$\%$ compared to previous state-of-the-art approaches.