 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFVO: Learning Darkness-free Visible and Infrared Image Disentanglement and Fusion All at Once
May 07, 2025Visible and infrared image fusion is one of the most crucial tasks in the field of image fusion, aiming to generate fused images with clear structural information and high-quality texture features for high-level vision tasks. However, when faced with severe illumination degradation in visible images, the fusion results of existing image fusion methods often exhibit blurry and dim visual effects, posing major challenges for autonomous driving. To this end, a Darkness-Free network is proposed to handle Visible and infrared image disentanglement and fusion all at Once (DFVO), which employs a cascaded multi-task approach to replace the traditional two-stage cascaded training (enhancement and fusion), addressing the issue of information entropy loss caused by hierarchical data transmission. Specifically, we construct a latent-common feature extractor (LCFE) to obtain latent features for the cascaded tasks strategy. Firstly, a details-extraction module (DEM) is devised to acquire high-frequency semantic information. Secondly, we design a hyper cross-attention module (HCAM) to extract low-frequency information and preserve texture features from source images. Finally, a relevant loss function is designed to guide the holistic network learning, thereby achieving better image fusion. Extensive experiments demonstrate that our proposed approach outperforms state-of-the-art alternatives in terms of qualitative and quantitative evaluations. Particularly, DFVO can generate clearer, more informative, and more evenly illuminated fusion results in the dark environments, achieving best performance on the LLVIP dataset with 63.258 dB PSNR and 0.724 CC, providing more effective information for high-level vision tasks. Our code is publicly accessible at https://github.com/DaVin-Qi530/DFVO.
RGB-Only Gaussian Splatting SLAM for Unbounded Outdoor Scenes
Feb 21, 2025



3D Gaussian Splatting (3DGS) has become a popular solution in SLAM, as it can produce high-fidelity novel views. However, previous GS-based methods primarily target indoor scenes and rely on RGB-D sensors or pre-trained depth estimation models, hence underperforming in outdoor scenarios. To address this issue, we propose a RGB-only gaussian splatting SLAM method for unbounded outdoor scenes--OpenGS-SLAM. Technically, we first employ a pointmap regression network to generate consistent pointmaps between frames for pose estimation. Compared to commonly used depth maps, pointmaps include spatial relationships and scene geometry across multiple views, enabling robust camera pose estimation. Then, we propose integrating the estimated camera poses with 3DGS rendering as an end-to-end differentiable pipeline. Our method achieves simultaneous optimization of camera poses and 3DGS scene parameters, significantly enhancing system tracking accuracy. Specifically, we also design an adaptive scale mapper for the pointmap regression network, which provides more accurate pointmap mapping to the 3DGS map representation. Our experiments on the Waymo dataset demonstrate that OpenGS-SLAM reduces tracking error to 9.8\% of previous 3DGS methods, and achieves state-of-the-art results in novel view synthesis. Project Page: https://3dagentworld.github.io/opengs-slam/
PrevPredMap: Exploring Temporal Modeling with Previous Predictions for Online Vectorized HD Map Construction
Jul 24, 2024
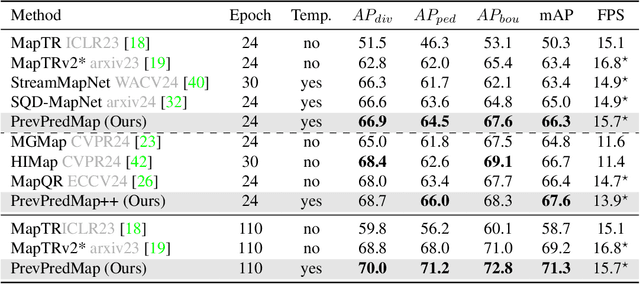


Temporal information is crucial for detecting occluded instances. Existing temporal representations have progressed from BEV or PV features to more compact query features. Compared to these aforementioned features, predictions offer the highest level of abstraction, providing explicit information. In the context of online vectorized HD map construction, this unique characteristic of predictions is potentially advantageous for long-term temporal modeling and the integration of map priors. This paper introduces PrevPredMap, a pioneering temporal modeling framework that leverages previous predictions for constructing online vectorized HD maps. We have meticulously crafted two essential modules for PrevPredMap: the previous-predictions-based query generator and the dynamic-position-query decoder. Specifically, the previous-predictions-based query generator is designed to separately encode different types of information from previous predictions, which are then effectively utilized by the dynamic-position-query decoder to generate current predictions. Furthermore, we have developed a dual-mode strategy to ensure PrevPredMap's robust performance across both single-frame and temporal modes. Extensive experiments demonstrate that PrevPredMap achieves state-of-the-art performance on the nuScenes and Argoverse2 datasets. Code will be available at https://github.com/pnnnnnnn/PrevPredMap.
CrossDehaze: Scaling Up Image Dehazing with Cross-Data Vision Alignment and Augmentation
Jul 20, 2024



In recent years, as computer vision tasks have increasingly relied on high-quality image inputs, the task of image dehazing has received significant attention. Previously, many methods based on priors and deep learning have been proposed to address the task of image dehazing. Ignoring the domain gap between different data, former de-hazing methods usually adopt multiple datasets for explicit training, which often makes the methods themselves be violated. To address this problem, we propose a novel method of internal and external data augmentation to improve the existing dehazing methodology. By using cross-data external augmentor. The dataset inherits samples from different domains that are firmly aligned, making the model learn more robust and generalizable features. By using the internal data augmentation method, the model can fully exploit local information within the images, thereby obtaining more image details. To demonstrate the effectiveness of our proposed method, we conduct training on both the Natural Image Dataset (NID) and the Remote Sensing Image Dataset (RSID). Experimental results show that our method clearly resolves the domain gap in different dehazing datasets and presents a new pipeline for joint training in the dehazing task. Our approach significantly outperforms other advanced methods in dehazing and produces dehazed images that are closest to real haze-free images. The code will be available at: https://github.com/wengzp1/ScaleUpDehazing
NeRF2Points: Large-Scale Point Cloud Generation From Street Views' Radiance Field Optimization
Apr 07, 2024
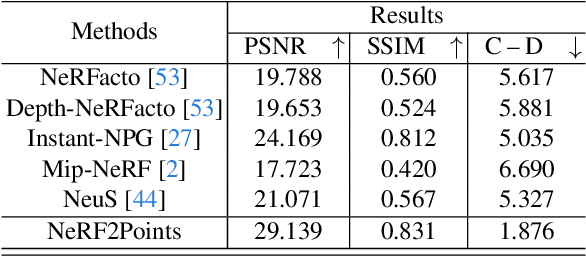

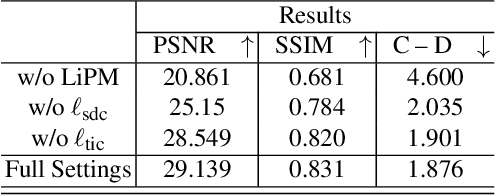
Neural Radiance Fields (NeRF) have emerged as a paradigm-shifting methodology for the photorealistic rendering of objects and environments, enabling the synthesis of novel viewpoints with remarkable fidelity. This is accomplished through the strategic utilization of object-centric camera poses characterized by significant inter-frame overlap. This paper explores a compelling, alternative utility of NeRF: the derivation of point clouds from aggregated urban landscape imagery. The transmutation of street-view data into point clouds is fraught with complexities, attributable to a nexus of interdependent variables. First, high-quality point cloud generation hinges on precise camera poses, yet many datasets suffer from inaccuracies in pose metadata. Also, the standard approach of NeRF is ill-suited for the distinct characteristics of street-view data from autonomous vehicles in vast, open settings. Autonomous vehicle cameras often record with limited overlap, leading to blurring, artifacts, and compromised pavement representation in NeRF-based point clouds. In this paper, we present NeRF2Points, a tailored NeRF variant for urban point cloud synthesis, notable for its high-quality output from RGB inputs alone. Our paper is supported by a bespoke, high-resolution 20-kilometer urban street dataset, designed for point cloud generation and evaluation. NeRF2Points adeptly navigates the inherent challenges of NeRF-based point cloud synthesis through the implementation of the following strategic innovations: (1) Integration of Weighted Iterative Geometric Optimization (WIGO) and Structure from Motion (SfM) for enhanced camera pose accuracy, elevating street-view data precision. (2) Layered Perception and Integrated Modeling (LPiM) is designed for distinct radiance field modeling in urban environments, resulting in coherent point cloud representations.
ReGeneration Learning of Diffusion Models with Rich Prompts for Zero-Shot Image Translation
May 08, 2023Large-scale text-to-image models have demonstrated amazing ability to synthesize diverse and high-fidelity images. However, these models are often violated by several limitations. Firstly, they require the user to provide precise and contextually relevant descriptions for the desired image modifications. Secondly, current models can impose significant changes to the original image content during the editing process. In this paper, we explore ReGeneration learning in an image-to-image Diffusion model (ReDiffuser), that preserves the content of the original image without human prompting and the requisite editing direction is automatically discovered within the text embedding space. To ensure consistent preservation of the shape during image editing, we propose cross-attention guidance based on regeneration learning. This novel approach allows for enhanced expression of the target domain features while preserving the original shape of the image. In addition, we introduce a cooperative update strategy, which allows for efficient preservation of the original shape of an image, thereby improving the quality and consistency of shape preservation throughout the editing process. Our proposed method leverages an existing pre-trained text-image diffusion model without any additional training. Extensive experiments show that the proposed method outperforms existing work in both real and synthetic image editing.
Conformal Loss-Controlling Prediction
Jan 06, 2023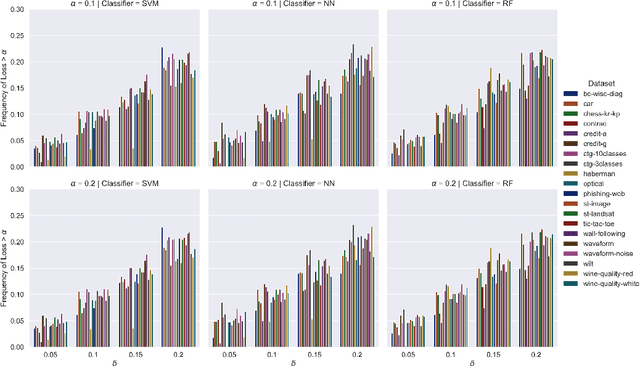
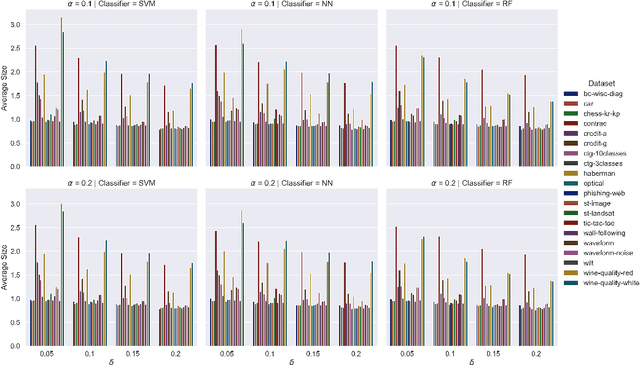

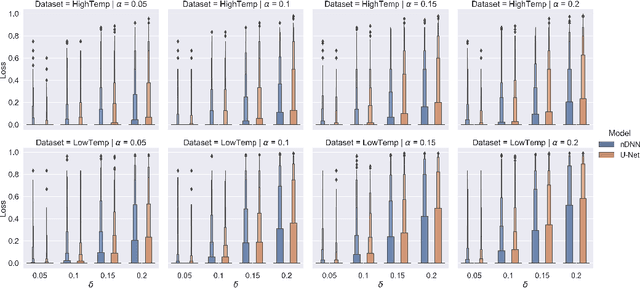
Conformal prediction is a learning framework controlling prediction coverage of prediction sets, which can be built on any learning algorithm for point prediction. This work proposes a learning framework named conformal loss-controlling prediction, which extends conformal prediction to the situation where the value of a loss function needs to be controlled. Different from existing works about risk-controlling prediction sets and conformal risk control with the purpose of controlling the expected values of loss functions, the proposed approach in this paper focuses on the loss for any test object, which is an extension of conformal prediction from miscoverage loss to some general loss. The controlling guarantee is proved under the assumption of exchangeability of data in finite-sample cases and the framework is tested empirically for classification with a class-varying loss and statistical postprocessing of numerical weather forecasting applications, which are introduced as point-wise classification and point-wise regression problems. All theoretical analysis and experimental results confirm the effectiveness of our loss-controlling approach.
BEKG: A Built Environment Knowledge Graph
Nov 05, 2022Practices in the built environment have become more digitalized with the rapid development of modern design and construction technologies. However, the requirement of practitioners or scholars to gather complicated professional knowledge in the built environment has not been satisfied yet. In this paper, more than 80,000 paper abstracts in the built environment field were obtained to build a knowledge graph, a knowledge base storing entities and their connective relations in a graph-structured data model. To ensure the retrieval accuracy of the entities and relations in the knowledge graph, two well-annotated datasets have been created, containing 2,000 instances and 1,450 instances each in 29 relations for the named entity recognition task and relation extraction task respectively. These two tasks were solved by two BERT-based models trained on the proposed dataset. Both models attained an accuracy above 85% on these two tasks. More than 200,000 high-quality relations and entities were obtained using these models to extract all abstract data. Finally, this knowledge graph is presented as a self-developed visualization system to reveal relations between various entities in the domain. Both the source code and the annotated dataset can be found here: https://github.com/HKUST-KnowComp/BEKG.
GTAE: Graph-Transformer based Auto-Encoders for Linguistic-Constrained Text Style Transfer
Feb 01, 2021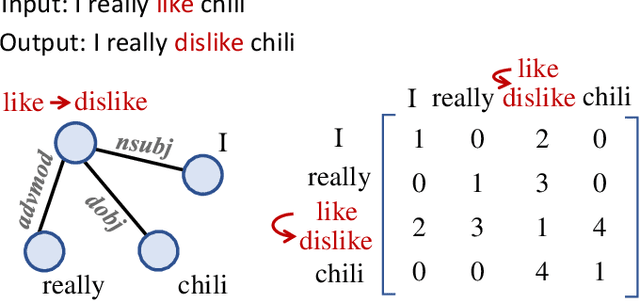
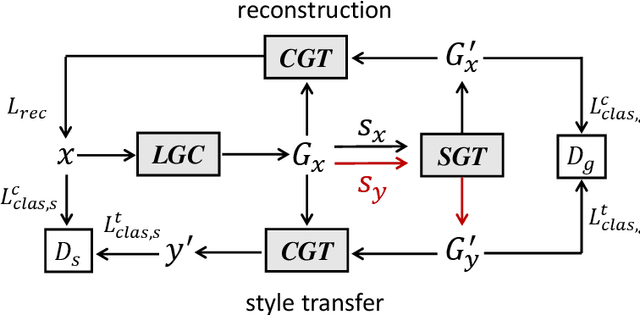
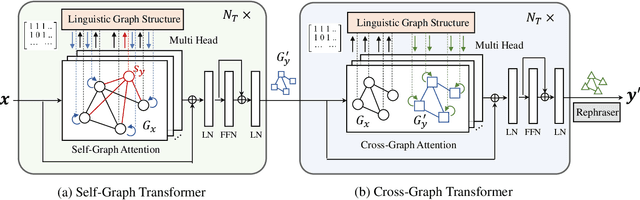
Non-parallel text style transfer has attracted increasing research interests in recent years. Despite successes in transferring the style based on the encoder-decoder framework, current approaches still lack the ability to preserve the content and even logic of original sentences, mainly due to the large unconstrained model space or too simplified assumptions on latent embedding space. Since language itself is an intelligent product of humans with certain grammars and has a limited rule-based model space by its nature, relieving this problem requires reconciling the model capacity of deep neural networks with the intrinsic model constraints from human linguistic rules. To this end, we propose a method called Graph Transformer based Auto Encoder (GTAE), which models a sentence as a linguistic graph and performs feature extraction and style transfer at the graph level, to maximally retain the content and the linguistic structure of original sentences. Quantitative experiment results on three non-parallel text style transfer tasks show that our model outperforms state-of-the-art methods in content preservation, while achieving comparable performance on transfer accuracy and sentence naturalness.
AIM 2020 Challenge on Real Image Super-Resolution: Methods and Results
Sep 25, 2020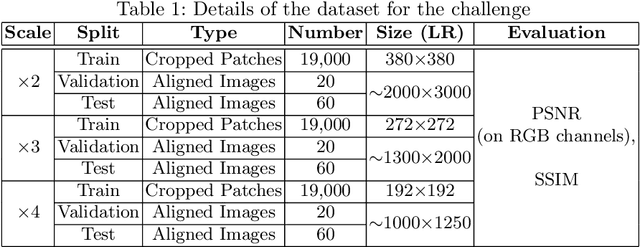
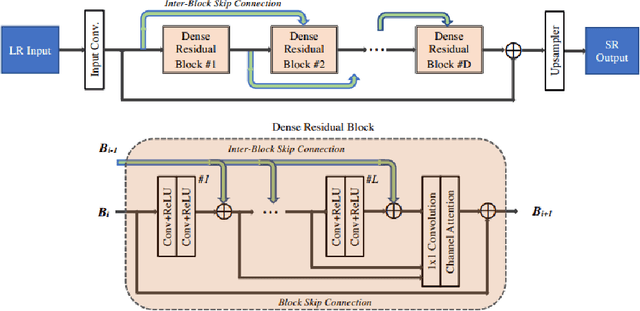
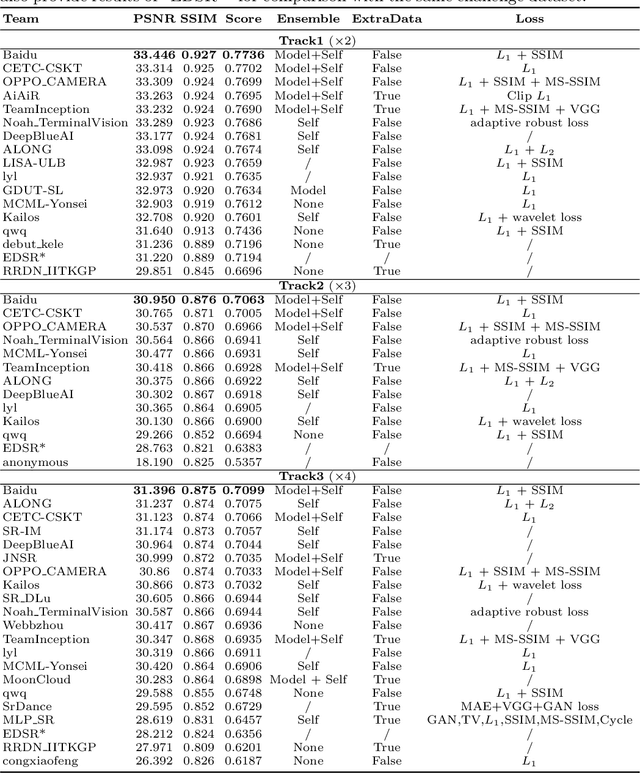
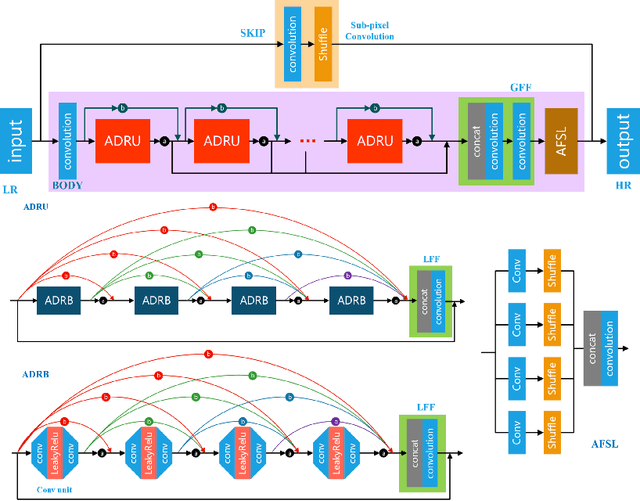
This paper introduces the real image Super-Resolution (SR) challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ECCV 2020. This challenge involves three tracks to super-resolve an input image for $\times$2, $\times$3 and $\times$4 scaling factors, respectively. The goal is to attract more attention to realistic image degradation for the SR task, which is much more complicated and challenging, and contributes to real-world image super-resolution applications. 452 participants were registered for three tracks in total, and 24 teams submitted their results. They gauge the state-of-the-art approaches for real image SR in terms of PSNR and SSIM.