 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Tactile-Visual Perception for Learning Multimodal Robot Manipulation
Dec 10, 2025Robotic manipulation requires both rich multimodal perception and effective learning frameworks to handle complex real-world tasks. See-through-skin (STS) sensors, which combine tactile and visual perception, offer promising sensing capabilities, while modern imitation learning provides powerful tools for policy acquisition. However, existing STS designs lack simultaneous multimodal perception and suffer from unreliable tactile tracking. Furthermore, integrating these rich multimodal signals into learning-based manipulation pipelines remains an open challenge. We introduce TacThru, an STS sensor enabling simultaneous visual perception and robust tactile signal extraction, and TacThru-UMI, an imitation learning framework that leverages these multimodal signals for manipulation. Our sensor features a fully transparent elastomer, persistent illumination, novel keyline markers, and efficient tracking, while our learning system integrates these signals through a Transformer-based Diffusion Policy. Experiments on five challenging real-world tasks show that TacThru-UMI achieves an average success rate of 85.5%, significantly outperforming the baselines of alternating tactile-visual (66.3%) and vision-only (55.4%). The system excels in critical scenarios, including contact detection with thin and soft objects and precision manipulation requiring multimodal coordination. This work demonstrates that combining simultaneous multimodal perception with modern learning frameworks enables more precise, adaptable robotic manipulation.
GWM: Towards Scalable Gaussian World Models for Robotic Manipulation
Aug 25, 2025



Training robot policies within a learned world model is trending due to the inefficiency of real-world interactions. The established image-based world models and policies have shown prior success, but lack robust geometric information that requires consistent spatial and physical understanding of the three-dimensional world, even pre-trained on internet-scale video sources. To this end, we propose a novel branch of world model named Gaussian World Model (GWM) for robotic manipulation, which reconstructs the future state by inferring the propagation of Gaussian primitives under the effect of robot actions. At its core is a latent Diffusion Transformer (DiT) combined with a 3D variational autoencoder, enabling fine-grained scene-level future state reconstruction with Gaussian Splatting. GWM can not only enhance the visual representation for imitation learning agent by self-supervised future prediction training, but can serve as a neural simulator that supports model-based reinforcement learning. Both simulated and real-world experiments depict that GWM can precisely predict future scenes conditioned on diverse robot actions, and can be further utilized to train policies that outperform the state-of-the-art by impressive margins, showcasing the initial data scaling potential of 3D world model.
MetaScenes: Towards Automated Replica Creation for Real-world 3D Scans
May 05, 2025Embodied AI (EAI) research requires high-quality, diverse 3D scenes to effectively support skill acquisition, sim-to-real transfer, and generalization. Achieving these quality standards, however, necessitates the precise replication of real-world object diversity. Existing datasets demonstrate that this process heavily relies on artist-driven designs, which demand substantial human effort and present significant scalability challenges. To scalably produce realistic and interactive 3D scenes, we first present MetaScenes, a large-scale, simulatable 3D scene dataset constructed from real-world scans, which includes 15366 objects spanning 831 fine-grained categories. Then, we introduce Scan2Sim, a robust multi-modal alignment model, which enables the automated, high-quality replacement of assets, thereby eliminating the reliance on artist-driven designs for scaling 3D scenes. We further propose two benchmarks to evaluate MetaScenes: a detailed scene synthesis task focused on small item layouts for robotic manipulation and a domain transfer task in vision-and-language navigation (VLN) to validate cross-domain transfer. Results confirm MetaScene's potential to enhance EAI by supporting more generalizable agent learning and sim-to-real applications, introducing new possibilities for EAI research. Project website: https://meta-scenes.github.io/.
Taccel: Scaling Up Vision-based Tactile Robotics via High-performance GPU Simulation
Apr 17, 2025Tactile sensing is crucial for achieving human-level robotic capabilities in manipulation tasks. VBTSs have emerged as a promising solution, offering high spatial resolution and cost-effectiveness by sensing contact through camera-captured deformation patterns of elastic gel pads. However, these sensors' complex physical characteristics and visual signal processing requirements present unique challenges for robotic applications. The lack of efficient and accurate simulation tools for VBTS has significantly limited the scale and scope of tactile robotics research. Here we present Taccel, a high-performance simulation platform that integrates IPC and ABD to model robots, tactile sensors, and objects with both accuracy and unprecedented speed, achieving an 18-fold acceleration over real-time across thousands of parallel environments. Unlike previous simulators that operate at sub-real-time speeds with limited parallelization, Taccel provides precise physics simulation and realistic tactile signals while supporting flexible robot-sensor configurations through user-friendly APIs. Through extensive validation in object recognition, robotic grasping, and articulated object manipulation, we demonstrate precise simulation and successful sim-to-real transfer. These capabilities position Taccel as a powerful tool for scaling up tactile robotics research and development. By enabling large-scale simulation and experimentation with tactile sensing, Taccel accelerates the development of more capable robotic systems, potentially transforming how robots interact with and understand their physical environment.
ManipTrans: Efficient Dexterous Bimanual Manipulation Transfer via Residual Learning
Mar 27, 2025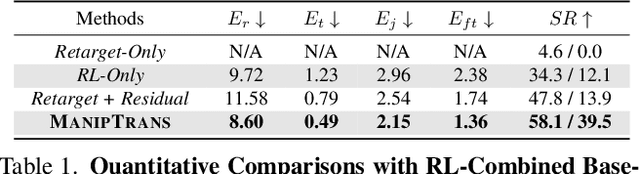
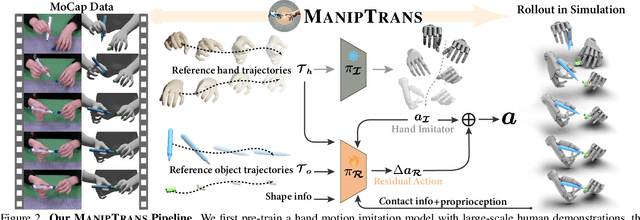

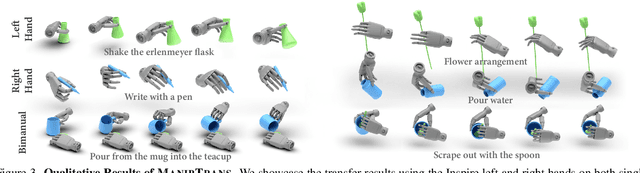
Human hands play a central role in interacting, motivating increasing research in dexterous robotic manipulation. Data-driven embodied AI algorithms demand precise, large-scale, human-like manipulation sequences, which are challenging to obtain with conventional reinforcement learning or real-world teleoperation. To address this, we introduce ManipTrans, a novel two-stage method for efficiently transferring human bimanual skills to dexterous robotic hands in simulation. ManipTrans first pre-trains a generalist trajectory imitator to mimic hand motion, then fine-tunes a specific residual module under interaction constraints, enabling efficient learning and accurate execution of complex bimanual tasks. Experiments show that ManipTrans surpasses state-of-the-art methods in success rate, fidelity, and efficiency. Leveraging ManipTrans, we transfer multiple hand-object datasets to robotic hands, creating DexManipNet, a large-scale dataset featuring previously unexplored tasks like pen capping and bottle unscrewing. DexManipNet comprises 3.3K episodes of robotic manipulation and is easily extensible, facilitating further policy training for dexterous hands and enabling real-world deployments.
PhysPart: Physically Plausible Part Completion for Interactable Objects
Aug 25, 2024



Interactable objects are ubiquitous in our daily lives. Recent advances in 3D generative models make it possible to automate the modeling of these objects, benefiting a range of applications from 3D printing to the creation of robot simulation environments. However, while significant progress has been made in modeling 3D shapes and appearances, modeling object physics, particularly for interactable objects, remains challenging due to the physical constraints imposed by inter-part motions. In this paper, we tackle the problem of physically plausible part completion for interactable objects, aiming to generate 3D parts that not only fit precisely into the object but also allow smooth part motions. To this end, we propose a diffusion-based part generation model that utilizes geometric conditioning through classifier-free guidance and formulates physical constraints as a set of stability and mobility losses to guide the sampling process. Additionally, we demonstrate the generation of dependent parts, paving the way toward sequential part generation for objects with complex part-whole hierarchies. Experimentally, we introduce a new metric for measuring physical plausibility based on motion success rates. Our model outperforms existing baselines over shape and physical metrics, especially those that do not adequately model physical constraints. We also demonstrate our applications in 3D printing, robot manipulation, and sequential part generation, showing our strength in realistic tasks with the demand for high physical plausibility.
Ag2Manip: Learning Novel Manipulation Skills with Agent-Agnostic Visual and Action Representations
Apr 26, 2024



Autonomous robotic systems capable of learning novel manipulation tasks are poised to transform industries from manufacturing to service automation. However, modern methods (e.g., VIP and R3M) still face significant hurdles, notably the domain gap among robotic embodiments and the sparsity of successful task executions within specific action spaces, resulting in misaligned and ambiguous task representations. We introduce Ag2Manip (Agent-Agnostic representations for Manipulation), a framework aimed at surmounting these challenges through two key innovations: a novel agent-agnostic visual representation derived from human manipulation videos, with the specifics of embodiments obscured to enhance generalizability; and an agent-agnostic action representation abstracting a robot's kinematics to a universal agent proxy, emphasizing crucial interactions between end-effector and object. Ag2Manip's empirical validation across simulated benchmarks like FrankaKitchen, ManiSkill, and PartManip shows a 325% increase in performance, achieved without domain-specific demonstrations. Ablation studies underline the essential contributions of the visual and action representations to this success. Extending our evaluations to the real world, Ag2Manip significantly improves imitation learning success rates from 50% to 77.5%, demonstrating its effectiveness and generalizability across both simulated and physical environments.
Move as You Say, Interact as You Can: Language-guided Human Motion Generation with Scene Affordance
Mar 26, 2024Despite significant advancements in text-to-motion synthesis, generating language-guided human motion within 3D environments poses substantial challenges. These challenges stem primarily from (i) the absence of powerful generative models capable of jointly modeling natural language, 3D scenes, and human motion, and (ii) the generative models' intensive data requirements contrasted with the scarcity of comprehensive, high-quality, language-scene-motion datasets. To tackle these issues, we introduce a novel two-stage framework that employs scene affordance as an intermediate representation, effectively linking 3D scene grounding and conditional motion generation. Our framework comprises an Affordance Diffusion Model (ADM) for predicting explicit affordance map and an Affordance-to-Motion Diffusion Model (AMDM) for generating plausible human motions. By leveraging scene affordance maps, our method overcomes the difficulty in generating human motion under multimodal condition signals, especially when training with limited data lacking extensive language-scene-motion pairs. Our extensive experiments demonstrate that our approach consistently outperforms all baselines on established benchmarks, including HumanML3D and HUMANISE. Additionally, we validate our model's exceptional generalization capabilities on a specially curated evaluation set featuring previously unseen descriptions and scenes.
An Embodied Generalist Agent in 3D World
Nov 18, 2023Leveraging massive knowledge and learning schemes from large language models (LLMs), recent machine learning models show notable successes in building generalist agents that exhibit the capability of general-purpose task solving in diverse domains, including natural language processing, computer vision, and robotics. However, a significant challenge remains as these models exhibit limited ability in understanding and interacting with the 3D world. We argue this limitation significantly hinders the current models from performing real-world tasks and further achieving general intelligence. To this end, we introduce an embodied multi-modal and multi-task generalist agent that excels in perceiving, grounding, reasoning, planning, and acting in the 3D world. Our proposed agent, referred to as LEO, is trained with shared LLM-based model architectures, objectives, and weights in two stages: (i) 3D vision-language alignment and (ii) 3D vision-language-action instruction tuning. To facilitate the training, we meticulously curate and generate an extensive dataset comprising object-level and scene-level multi-modal tasks with exceeding scale and complexity, necessitating a deep understanding of and interaction with the 3D world. Through rigorous experiments, we demonstrate LEO's remarkable proficiency across a wide spectrum of tasks, including 3D captioning, question answering, embodied reasoning, embodied navigation, and robotic manipulation. Our ablation results further provide valuable insights for the development of future embodied generalist agents.
Grasp Multiple Objects with One Hand
Oct 24, 2023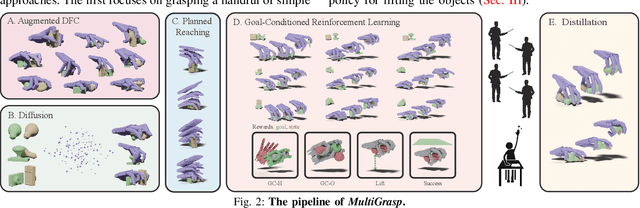

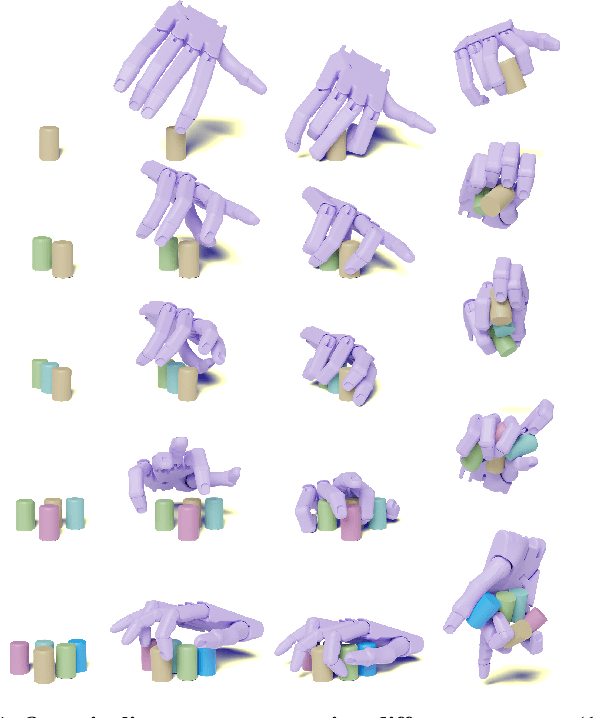

The human hand's complex kinematics allow for simultaneous grasping and manipulation of multiple objects, essential for tasks like object transfer and in-hand manipulation. Despite its importance, robotic multi-object grasping remains underexplored and presents challenges in kinematics, dynamics, and object configurations. This paper introduces MultiGrasp, a two-stage method for multi-object grasping on a tabletop with a multi-finger dexterous hand. It involves (i) generating pre-grasp proposals and (ii) executing the grasp and lifting the objects. Experimental results primarily focus on dual-object grasping and report a 44.13% success rate, showcasing adaptability to unseen object configurations and imprecise grasps. The framework also demonstrates the capability to grasp more than two objects, albeit at a reduced inference speed.