 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-RFT: Reinforcement Fine-Tuning for Video-based 3D Scene Understanding
Mar 05, 2026Reinforcement Learning with Verifiable Rewards ( RLVR ) has emerged as a transformative paradigm for enhancing the reasoning capabilities of Large Language Models ( LLMs), yet its potential in 3D scene understanding remains under-explored. Existing approaches largely rely on Supervised Fine-Tuning ( SFT), where the token-level cross-entropy loss acts as an indirect proxy for optimization, leading to a misalignment between training objectives and task performances. To bridge this gap, we present Reinforcement Fine-Tuning for Video-based 3D Scene Understanding (3D-RFT ), the first framework to extend RLVR to video-based 3D perception and reasoning. 3D-RFT shifts the paradigm by directly optimizing the model towards evaluation metrics. 3D-RFT first activates 3D-aware Multi-modal Large Language Models ( MLLM s) via SFT, followed by reinforcement fine-tuning using Group Relative Policy Optimization ( GRPO) with strictly verifiable reward functions. We design task-specific reward functions directly from metrics like 3D IoU and F1-Score to provide more effective signals to guide model training. Extensive experiments demonstrate that 3D-RFT-4B achieves state-of-the-art performance on various video-based 3D scene understanding tasks. Notably, 3D-RFT-4B significantly outperforms larger models (e.g., VG LLM-8B) on 3D video detection, 3D visual grounding, and spatial reasoning benchmarks. We further reveal good properties of 3D-RFT such as robust efficacy, and valuable insights into training strategies and data impact. We hope 3D-RFT can serve as a robust and promising paradigm for future development of 3D scene understanding.
LEO-VL: Towards 3D Vision-Language Generalists via Data Scaling with Efficient Representation
Jun 11, 2025



Developing 3D-VL generalists capable of understanding 3D scenes and following natural language instructions to perform a wide range of tasks has been a long-standing goal in the 3D-VL community. Despite recent progress, 3D-VL models still lag behind their 2D counterparts in capability and robustness, falling short of the generalist standard. A key obstacle to developing 3D-VL generalists lies in data scalability, hindered by the lack of an efficient scene representation. We propose LEO-VL, a 3D-VL model built upon condensed feature grid (CFG), an efficient scene representation that bridges 2D perception and 3D spatial structure while significantly reducing token overhead. This efficiency unlocks large-scale training towards 3D-VL generalist, for which we curate over 700k high-quality 3D-VL data spanning four domains of real-world indoor scenes and five tasks such as captioning and dialogue. LEO-VL achieves state-of-the-art performance on a variety of 3D QA benchmarks, including SQA3D, MSQA, and Beacon3D. Ablation studies confirm the efficiency of our representation, the importance of task and scene diversity, and the validity of our data curation principle. Furthermore, we introduce SceneDPO, a novel post-training objective that enhances the robustness of 3D-VL models. We hope our findings contribute to the advancement of scalable and robust 3D-VL generalists.
Unveiling the Mist over 3D Vision-Language Understanding: Object-centric Evaluation with Chain-of-Analysis
Apr 01, 2025Existing 3D vision-language (3D-VL) benchmarks fall short in evaluating 3D-VL models, creating a "mist" that obscures rigorous insights into model capabilities and 3D-VL tasks. This mist persists due to three key limitations. First, flawed test data, like ambiguous referential text in the grounding task, can yield incorrect and unreliable test results. Second, oversimplified metrics such as simply averaging accuracy per question answering (QA) pair, cannot reveal true model capability due to their vulnerability to language variations. Third, existing benchmarks isolate the grounding and QA tasks, disregarding the underlying coherence that QA should be based on solid grounding capabilities. To unveil the "mist", we propose Beacon3D, a benchmark for 3D-VL grounding and QA tasks, delivering a perspective shift in the evaluation of 3D-VL understanding. Beacon3D features (i) high-quality test data with precise and natural language, (ii) object-centric evaluation with multiple tests per object to ensure robustness, and (iii) a novel chain-of-analysis paradigm to address language robustness and model performance coherence across grounding and QA. Our evaluation of state-of-the-art 3D-VL models on Beacon3D reveals that (i) object-centric evaluation elicits true model performance and particularly weak generalization in QA; (ii) grounding-QA coherence remains fragile in current 3D-VL models, and (iii) incorporating large language models (LLMs) to 3D-VL models, though as a prevalent practice, hinders grounding capabilities and has yet to elevate QA capabilities. We hope Beacon3D and our comprehensive analysis could benefit the 3D-VL community towards faithful developments.
Multi-modal Situated Reasoning in 3D Scenes
Sep 04, 2024



Situation awareness is essential for understanding and reasoning about 3D scenes in embodied AI agents. However, existing datasets and benchmarks for situated understanding are limited in data modality, diversity, scale, and task scope. To address these limitations, we propose Multi-modal Situated Question Answering (MSQA), a large-scale multi-modal situated reasoning dataset, scalably collected leveraging 3D scene graphs and vision-language models (VLMs) across a diverse range of real-world 3D scenes. MSQA includes 251K situated question-answering pairs across 9 distinct question categories, covering complex scenarios within 3D scenes. We introduce a novel interleaved multi-modal input setting in our benchmark to provide text, image, and point cloud for situation and question description, resolving ambiguity in previous single-modality convention (e.g., text). Additionally, we devise the Multi-modal Situated Next-step Navigation (MSNN) benchmark to evaluate models' situated reasoning for navigation. Comprehensive evaluations on MSQA and MSNN highlight the limitations of existing vision-language models and underscore the importance of handling multi-modal interleaved inputs and situation modeling. Experiments on data scaling and cross-domain transfer further demonstrate the efficacy of leveraging MSQA as a pre-training dataset for developing more powerful situated reasoning models.
An Embodied Generalist Agent in 3D World
Nov 18, 2023Leveraging massive knowledge and learning schemes from large language models (LLMs), recent machine learning models show notable successes in building generalist agents that exhibit the capability of general-purpose task solving in diverse domains, including natural language processing, computer vision, and robotics. However, a significant challenge remains as these models exhibit limited ability in understanding and interacting with the 3D world. We argue this limitation significantly hinders the current models from performing real-world tasks and further achieving general intelligence. To this end, we introduce an embodied multi-modal and multi-task generalist agent that excels in perceiving, grounding, reasoning, planning, and acting in the 3D world. Our proposed agent, referred to as LEO, is trained with shared LLM-based model architectures, objectives, and weights in two stages: (i) 3D vision-language alignment and (ii) 3D vision-language-action instruction tuning. To facilitate the training, we meticulously curate and generate an extensive dataset comprising object-level and scene-level multi-modal tasks with exceeding scale and complexity, necessitating a deep understanding of and interaction with the 3D world. Through rigorous experiments, we demonstrate LEO's remarkable proficiency across a wide spectrum of tasks, including 3D captioning, question answering, embodied reasoning, embodied navigation, and robotic manipulation. Our ablation results further provide valuable insights for the development of future embodied generalist agents.
Memory-Based Label-Text Tuning for Few-Shot Class-Incremental Learning
Jul 03, 2022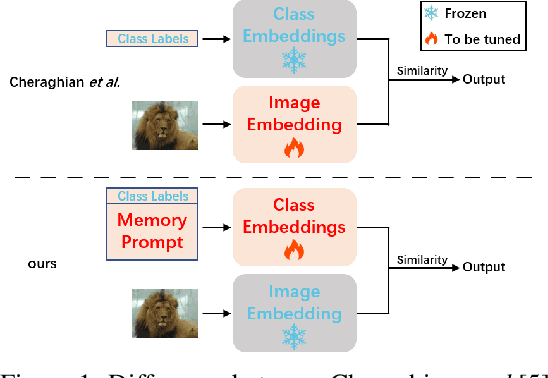
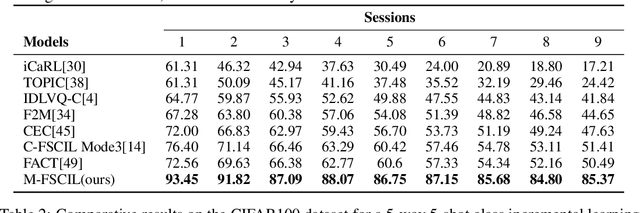
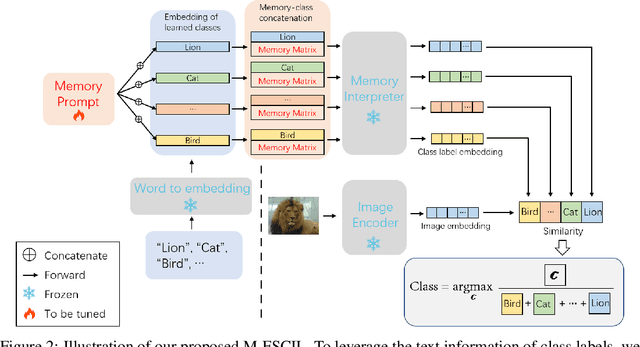
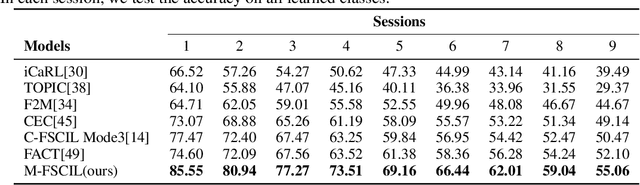
Few-shot class-incremental learning(FSCIL) focuses on designing learning algorithms that can continually learn a sequence of new tasks from a few samples without forgetting old ones. The difficulties are that training on a sequence of limited data from new tasks leads to severe overfitting issues and causes the well-known catastrophic forgetting problem. Existing researches mainly utilize the image information, such as storing the image knowledge of previous tasks or limiting classifiers updating. However, they ignore analyzing the informative and less noisy text information of class labels. In this work, we propose leveraging the label-text information by adopting the memory prompt. The memory prompt can learn new data sequentially, and meanwhile store the previous knowledge. Furthermore, to optimize the memory prompt without undermining the stored knowledge, we propose a stimulation-based training strategy. It optimizes the memory prompt depending on the image embedding stimulation, which is the distribution of the image embedding elements. Experiments show that our proposed method outperforms all prior state-of-the-art approaches, significantly mitigating the catastrophic forgetting and overfitting problems.
Switchable Representation Learning Framework with Self-compatibility
Jun 16, 2022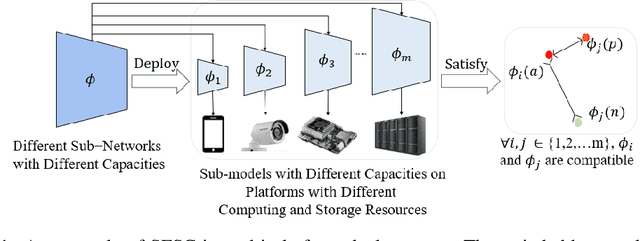

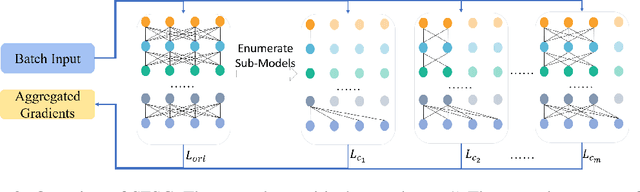
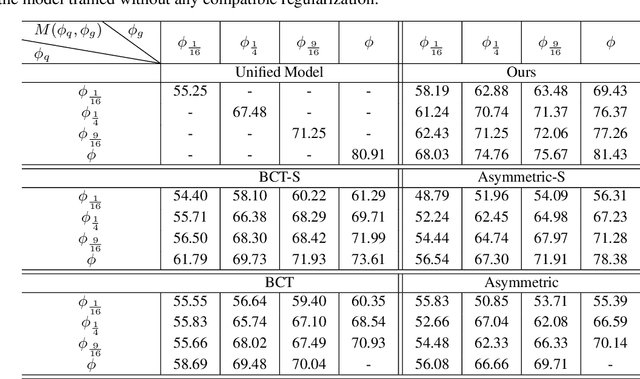
Real-world visual search systems involve deployments on multiple platforms with different computing and storage resources. Deploying a unified model that suits the minimal-constrain platforms leads to limited accuracy. It is expected to deploy models with different capacities adapting to the resource constraints, which requires features extracted by these models to be aligned in the metric space. The method to achieve feature alignments is called "compatible learning". Existing research mainly focuses on the one-to-one compatible paradigm, which is limited in learning compatibility among multiple models. We propose a Switchable representation learning Framework with Self-Compatibility (SFSC). SFSC generates a series of compatible sub-models with different capacities through one training process. The optimization of sub-models faces gradients conflict, and we mitigate it from the perspective of the magnitude and direction. We adjust the priorities of sub-models dynamically through uncertainty estimation to co-optimize sub-models properly. Besides, the gradients with conflicting directions are projected to avoid mutual interference. SFSC achieves state-of-art performance on the evaluated dataset.