 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Sequence Semi-Supervised Learning for Multi-Parametric MRI-Based Visual Pathway Delineation
May 26, 2025Accurately delineating the visual pathway (VP) is crucial for understanding the human visual system and diagnosing related disorders. Exploring multi-parametric MR imaging data has been identified as an important way to delineate VP. However, due to the complex cross-sequence relationships, existing methods cannot effectively model the complementary information from different MRI sequences. In addition, these existing methods heavily rely on large training data with labels, which is labor-intensive and time-consuming to obtain. In this work, we propose a novel semi-supervised multi-parametric feature decomposition framework for VP delineation. Specifically, a correlation-constrained feature decomposition (CFD) is designed to handle the complex cross-sequence relationships by capturing the unique characteristics of each MRI sequence and easing the multi-parametric information fusion process. Furthermore, a consistency-based sample enhancement (CSE) module is developed to address the limited labeled data issue, by generating and promoting meaningful edge information from unlabeled data. We validate our framework using two public datasets, and one in-house Multi-Shell Diffusion MRI (MDM) dataset. Experimental results demonstrate the superiority of our approach in terms of delineation performance when compared to seven state-of-the-art approaches.
An Arbitrary-Modal Fusion Network for Volumetric Cranial Nerves Tract Segmentation
May 05, 2025The segmentation of cranial nerves (CNs) tract provides a valuable quantitative tool for the analysis of the morphology and trajectory of individual CNs. Multimodal CNs tract segmentation networks, e.g., CNTSeg, which combine structural Magnetic Resonance Imaging (MRI) and diffusion MRI, have achieved promising segmentation performance. However, it is laborious or even infeasible to collect complete multimodal data in clinical practice due to limitations in equipment, user privacy, and working conditions. In this work, we propose a novel arbitrary-modal fusion network for volumetric CNs tract segmentation, called CNTSeg-v2, which trains one model to handle different combinations of available modalities. Instead of directly combining all the modalities, we select T1-weighted (T1w) images as the primary modality due to its simplicity in data acquisition and contribution most to the results, which supervises the information selection of other auxiliary modalities. Our model encompasses an Arbitrary-Modal Collaboration Module (ACM) designed to effectively extract informative features from other auxiliary modalities, guided by the supervision of T1w images. Meanwhile, we construct a Deep Distance-guided Multi-stage (DDM) decoder to correct small errors and discontinuities through signed distance maps to improve segmentation accuracy. We evaluate our CNTSeg-v2 on the Human Connectome Project (HCP) dataset and the clinical Multi-shell Diffusion MRI (MDM) dataset. Extensive experimental results show that our CNTSeg-v2 achieves state-of-the-art segmentation performance, outperforming all competing methods.
Diff5T: Benchmarking Human Brain Diffusion MRI with an Extensive 5.0 Tesla K-Space and Spatial Dataset
Dec 09, 2024

Diffusion magnetic resonance imaging (dMRI) provides critical insights into the microstructural and connectional organization of the human brain. However, the availability of high-field, open-access datasets that include raw k-space data for advanced research remains limited. To address this gap, we introduce Diff5T, a first comprehensive 5.0 Tesla diffusion MRI dataset focusing on the human brain. This dataset includes raw k-space data and reconstructed diffusion images, acquired using a variety of imaging protocols. Diff5T is designed to support the development and benchmarking of innovative methods in artifact correction, image reconstruction, image preprocessing, diffusion modelling and tractography. The dataset features a wide range of diffusion parameters, including multiple b-values and gradient directions, allowing extensive research applications in studying human brain microstructure and connectivity. With its emphasis on open accessibility and detailed benchmarks, Diff5T serves as a valuable resource for advancing human brain mapping research using diffusion MRI, fostering reproducibility, and enabling collaboration across the neuroscience and medical imaging communities.
Bundle-specific Tractogram Distribution Estimation Using Higher-order Streamline Differential Equation
Jul 06, 2023Tractography traces the peak directions extracted from fiber orientation distribution (FOD) suffering from ambiguous spatial correspondences between diffusion directions and fiber geometry, which is prone to producing erroneous tracks while missing true positive connections. The peaks-based tractography methods 'locally' reconstructed streamlines in 'single to single' manner, thus lacking of global information about the trend of the whole fiber bundle. In this work, we propose a novel tractography method based on a bundle-specific tractogram distribution function by using a higher-order streamline differential equation, which reconstructs the streamline bundles in 'cluster to cluster' manner. A unified framework for any higher-order streamline differential equation is presented to describe the fiber bundles with disjoint streamlines defined based on the diffusion tensor vector field. At the global level, the tractography process is simplified as the estimation of bundle-specific tractogram distribution (BTD) coefficients by minimizing the energy optimization model, and is used to characterize the relations between BTD and diffusion tensor vector under the prior guidance by introducing the tractogram bundle information to provide anatomic priors. Experiments are performed on simulated Hough, Sine, Circle data, ISMRM 2015 Tractography Challenge data, FiberCup data, and in vivo data from the Human Connectome Project (HCP) data for qualitative and quantitative evaluation. The results demonstrate that our approach can reconstruct the complex global fiber bundles directly. BTD reduces the error deviation and accumulation at the local level and shows better results in reconstructing long-range, twisting, and large fanning tracts.
Reconstructing the somatotopic organization of the corticospinal tract remains a challenge for modern tractography methods
Jun 15, 2023The corticospinal tract (CST) is a critically important white matter fiber tract in the human brain that enables control of voluntary movements of the body. Diffusion MRI tractography is the only method that enables the study of the anatomy and variability of the CST pathway in human health. In this work, we explored the performance of six widely used tractography methods for reconstructing the CST and its somatotopic organization. We perform experiments using diffusion MRI data from the Human Connectome Project. Four quantitative measurements including reconstruction rate, the WM-GM interface coverage, anatomical distribution of streamlines, and correlation with cortical volumes to assess the advantages and limitations of each method. Overall, we conclude that while current tractography methods have made progress toward the well-known challenge of improving the reconstruction of the lateral projections of the CST, the overall problem of performing a comprehensive CST reconstruction, including clinically important projections in the lateral (hand and face area) and medial portions (leg area), remains an important challenge for diffusion MRI tractography.
DeepRGVP: A Novel Microstructure-Informed Supervised Contrastive Learning Framework for Automated Identification Of The Retinogeniculate Pathway Using dMRI Tractography
Nov 15, 2022



The retinogeniculate pathway (RGVP) is responsible for carrying visual information from the retina to the lateral geniculate nucleus. Identification and visualization of the RGVP are important in studying the anatomy of the visual system and can inform treatment of related brain diseases. Diffusion MRI (dMRI) tractography is an advanced imaging method that uniquely enables in vivo mapping of the 3D trajectory of the RGVP. Currently, identification of the RGVP from tractography data relies on expert (manual) selection of tractography streamlines, which is time-consuming, has high clinical and expert labor costs, and affected by inter-observer variability. In this paper, we present what we believe is the first deep learning framework, namely DeepRGVP, to enable fast and accurate identification of the RGVP from dMRI tractography data. We design a novel microstructure-informed supervised contrastive learning method that leverages both streamline label and tissue microstructure information to determine positive and negative pairs. We propose a simple and successful streamline-level data augmentation method to address highly imbalanced training data, where the number of RGVP streamlines is much lower than that of non-RGVP streamlines. We perform comparisons with several state-of-the-art deep learning methods that were designed for tractography parcellation, and we show superior RGVP identification results using DeepRGVP.
White Matter Tracts are Point Clouds: Neuropsychological Score Prediction and Critical Region Localization via Geometric Deep Learning
Jul 06, 2022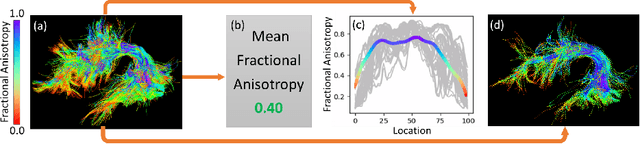
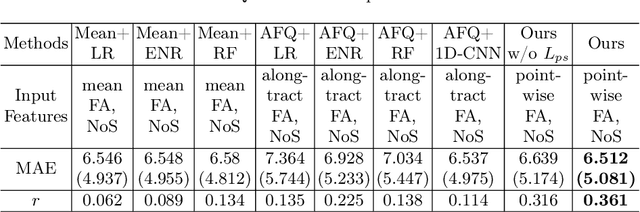
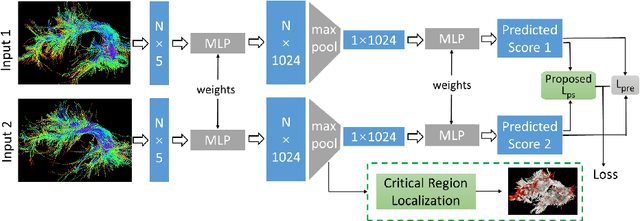
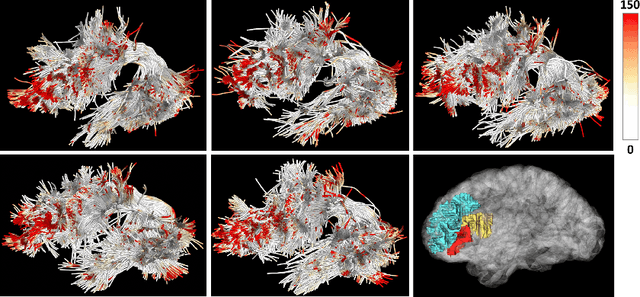
White matter tract microstructure has been shown to influence neuropsychological scores of cognitive performance. However, prediction of these scores from white matter tract data has not been attempted. In this paper, we propose a deep-learning-based framework for neuropsychological score prediction using microstructure measurements estimated from diffusion magnetic resonance imaging (dMRI) tractography, focusing on predicting performance on a receptive vocabulary assessment task based on a critical fiber tract for language, the arcuate fasciculus (AF). We directly utilize information from all points in a fiber tract, without the need to average data along the fiber as is traditionally required by diffusion MRI tractometry methods. Specifically, we represent the AF as a point cloud with microstructure measurements at each point, enabling adoption of point-based neural networks. We improve prediction performance with the proposed Paired-Siamese Loss that utilizes information about differences between continuous neuropsychological scores. Finally, we propose a Critical Region Localization (CRL) algorithm to localize informative anatomical regions containing points with strong contributions to the prediction results. Our method is evaluated on data from 806 subjects from the Human Connectome Project dataset. Results demonstrate superior neuropsychological score prediction performance compared to baseline methods. We discover that critical regions in the AF are strikingly consistent across subjects, with the highest number of strongly contributing points located in frontal cortical regions (i.e., the rostral middle frontal, pars opercularis, and pars triangularis), which are strongly implicated as critical areas for language processes.
Memory-Based Label-Text Tuning for Few-Shot Class-Incremental Learning
Jul 03, 2022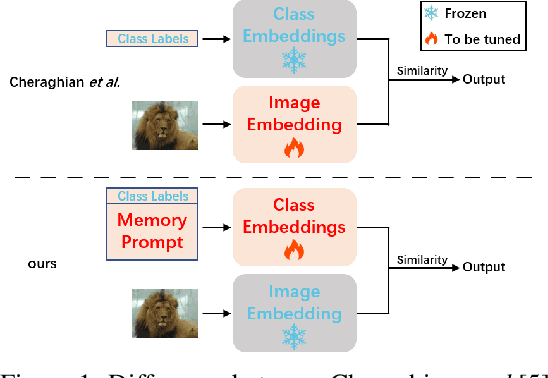
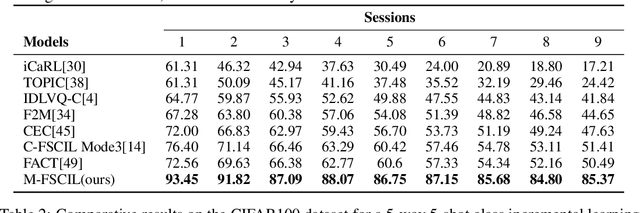
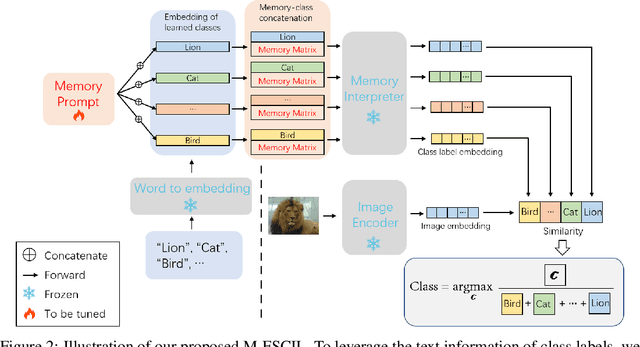
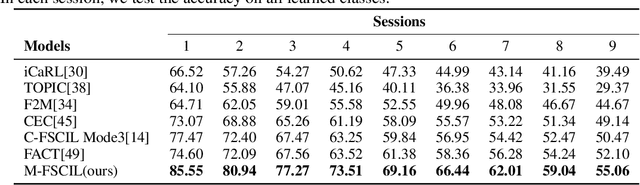
Few-shot class-incremental learning(FSCIL) focuses on designing learning algorithms that can continually learn a sequence of new tasks from a few samples without forgetting old ones. The difficulties are that training on a sequence of limited data from new tasks leads to severe overfitting issues and causes the well-known catastrophic forgetting problem. Existing researches mainly utilize the image information, such as storing the image knowledge of previous tasks or limiting classifiers updating. However, they ignore analyzing the informative and less noisy text information of class labels. In this work, we propose leveraging the label-text information by adopting the memory prompt. The memory prompt can learn new data sequentially, and meanwhile store the previous knowledge. Furthermore, to optimize the memory prompt without undermining the stored knowledge, we propose a stimulation-based training strategy. It optimizes the memory prompt depending on the image embedding stimulation, which is the distribution of the image embedding elements. Experiments show that our proposed method outperforms all prior state-of-the-art approaches, significantly mitigating the catastrophic forgetting and overfitting problems.
Switchable Representation Learning Framework with Self-compatibility
Jun 16, 2022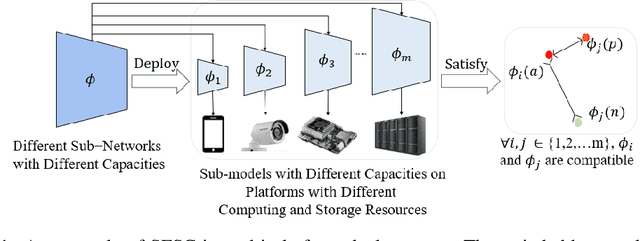

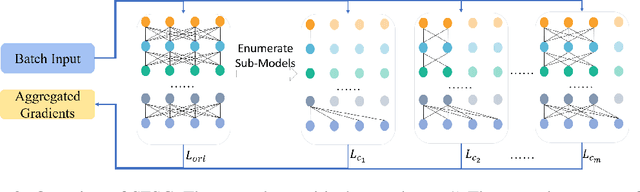
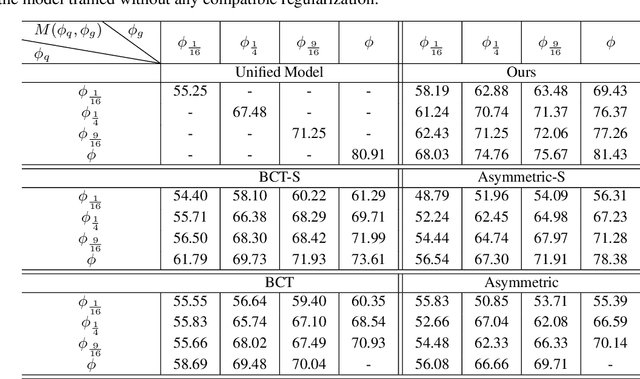
Real-world visual search systems involve deployments on multiple platforms with different computing and storage resources. Deploying a unified model that suits the minimal-constrain platforms leads to limited accuracy. It is expected to deploy models with different capacities adapting to the resource constraints, which requires features extracted by these models to be aligned in the metric space. The method to achieve feature alignments is called "compatible learning". Existing research mainly focuses on the one-to-one compatible paradigm, which is limited in learning compatibility among multiple models. We propose a Switchable representation learning Framework with Self-Compatibility (SFSC). SFSC generates a series of compatible sub-models with different capacities through one training process. The optimization of sub-models faces gradients conflict, and we mitigate it from the perspective of the magnitude and direction. We adjust the priorities of sub-models dynamically through uncertainty estimation to co-optimize sub-models properly. Besides, the gradients with conflicting directions are projected to avoid mutual interference. SFSC achieves state-of-art performance on the evaluated dataset.
T-SVDNet: Exploring High-Order Prototypical Correlations for Multi-Source Domain Adaptation
Jul 30, 2021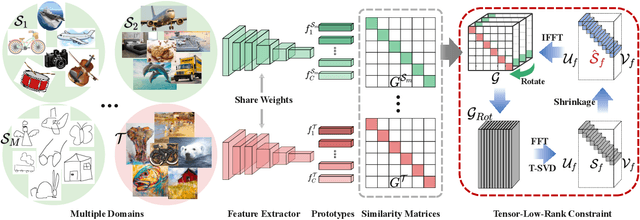
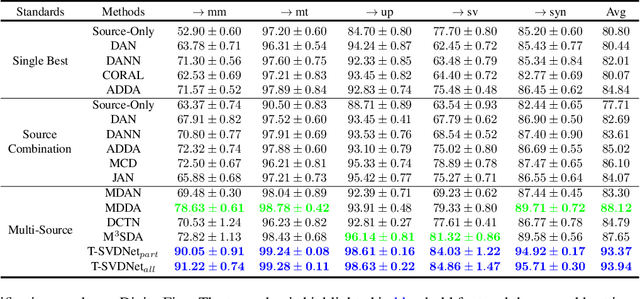
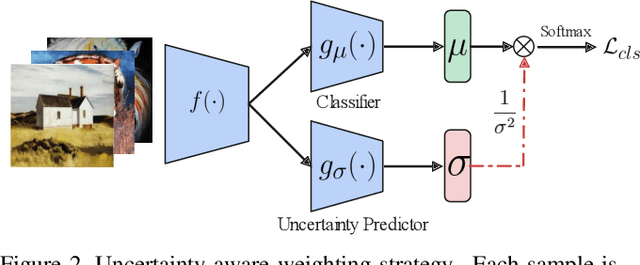
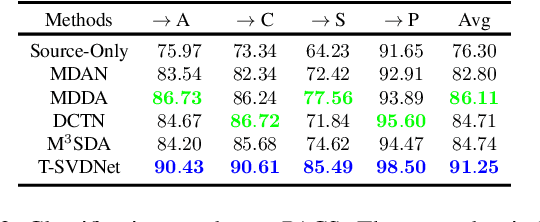
Most existing domain adaptation methods focus on adaptation from only one source domain, however, in practice there are a number of relevant sources that could be leveraged to help improve performance on target domain. We propose a novel approach named T-SVDNet to address the task of Multi-source Domain Adaptation (MDA), which is featured by incorporating Tensor Singular Value Decomposition (T-SVD) into a neural network's training pipeline. Overall, high-order correlations among multiple domains and categories are fully explored so as to better bridge the domain gap. Specifically, we impose Tensor-Low-Rank (TLR) constraint on a tensor obtained by stacking up a group of prototypical similarity matrices, aiming at capturing consistent data structure across different domains. Furthermore, to avoid negative transfer brought by noisy source data, we propose a novel uncertainty-aware weighting strategy to adaptively assign weights to different source domains and samples based on the result of uncertainty estimation. Extensive experiments conducted on public benchmarks demonstrate the superiority of our model in addressing the task of MDA compared to state-of-the-art methods.