 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC2P: Multi-Agent Path Finding via Personalized-Enhanced Communication and Crowd Perception
Jan 06, 2026Distributed Multi-Agent Path Finding (MAPF) integrated with Multi-Agent Reinforcement Learning (MARL) has emerged as a prominent research focus, enabling real-time cooperative decision-making in partially observable environments through inter-agent communication. However, due to insufficient collaborative and perceptual capabilities, existing methods are inadequate for scaling across diverse environmental conditions. To address these challenges, we propose PC2P, a novel distributed MAPF method derived from a Q-learning-based MARL framework. Initially, we introduce a personalized-enhanced communication mechanism based on dynamic graph topology, which ascertains the core aspects of ``who" and ``what" in interactive process through three-stage operations: selection, generation, and aggregation. Concurrently, we incorporate local crowd perception to enrich agents' heuristic observation, thereby strengthening the model's guidance for effective actions via the integration of static spatial constraints and dynamic occupancy changes. To resolve extreme deadlock issues, we propose a region-based deadlock-breaking strategy that leverages expert guidance to implement efficient coordination within confined areas. Experimental results demonstrate that PC2P achieves superior performance compared to state-of-the-art distributed MAPF methods in varied environments. Ablation studies further confirm the effectiveness of each module for overall performance.
Attention Round for Post-Training Quantization
Jul 07, 2022
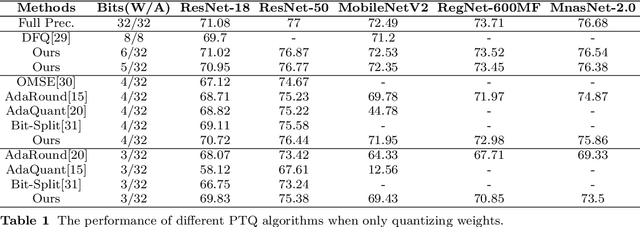
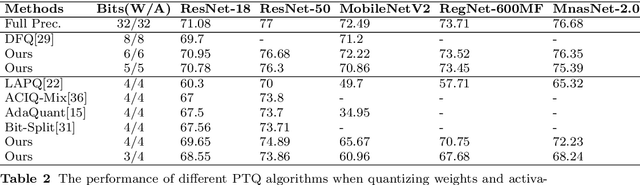
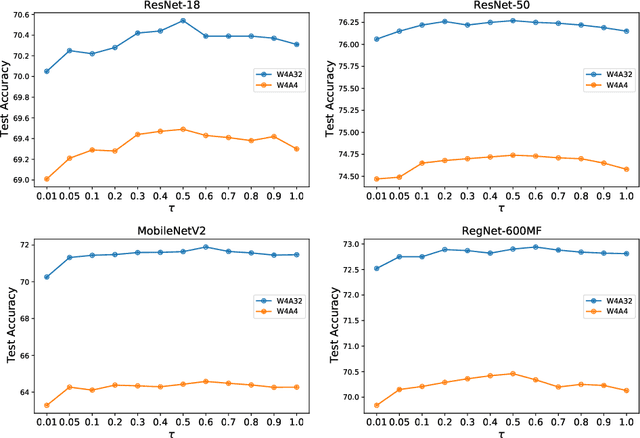
At present, the quantification methods of neural network models are mainly divided into post-training quantization (PTQ) and quantization aware training (QAT). Post-training quantization only need a small part of the data to complete the quantification process, but the performance of its quantitative model is not as good as the quantization aware training. This paper presents a novel quantification method called Attention Round. This method gives parameters w the opportunity to be mapped to all possible quantized values, rather than just the two quantized values nearby w in the process of quantization. The probability of being mapped to different quantified values is negatively correlated with the distance between the quantified values and w, and decay with a Gaussian function. In addition, this paper uses the lossy coding length as a measure to assign bit widths to the different layers of the model to solve the problem of mixed precision quantization, which effectively avoids to solve combinatorial optimization problem. This paper also performs quantitative experiments on different models, the results confirm the effectiveness of the proposed method. For ResNet18 and MobileNetV2, the post-training quantization proposed in this paper only require 1,024 training data and 10 minutes to complete the quantization process, which can achieve quantization performance on par with quantization aware training.
Memory-Based Label-Text Tuning for Few-Shot Class-Incremental Learning
Jul 03, 2022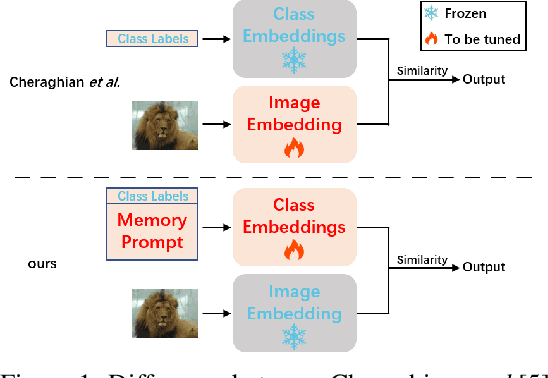
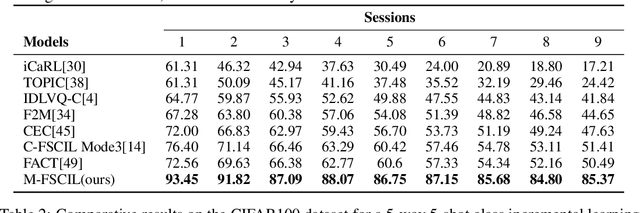
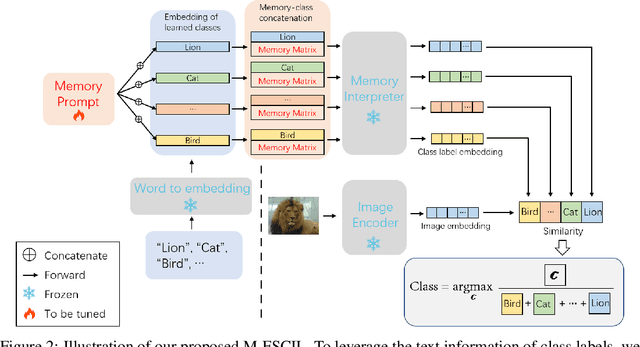
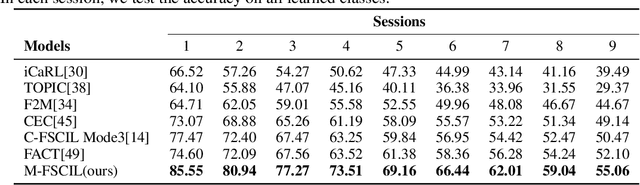
Few-shot class-incremental learning(FSCIL) focuses on designing learning algorithms that can continually learn a sequence of new tasks from a few samples without forgetting old ones. The difficulties are that training on a sequence of limited data from new tasks leads to severe overfitting issues and causes the well-known catastrophic forgetting problem. Existing researches mainly utilize the image information, such as storing the image knowledge of previous tasks or limiting classifiers updating. However, they ignore analyzing the informative and less noisy text information of class labels. In this work, we propose leveraging the label-text information by adopting the memory prompt. The memory prompt can learn new data sequentially, and meanwhile store the previous knowledge. Furthermore, to optimize the memory prompt without undermining the stored knowledge, we propose a stimulation-based training strategy. It optimizes the memory prompt depending on the image embedding stimulation, which is the distribution of the image embedding elements. Experiments show that our proposed method outperforms all prior state-of-the-art approaches, significantly mitigating the catastrophic forgetting and overfitting problems.
Fastidious Attention Network for Navel Orange Segmentation
Mar 26, 2020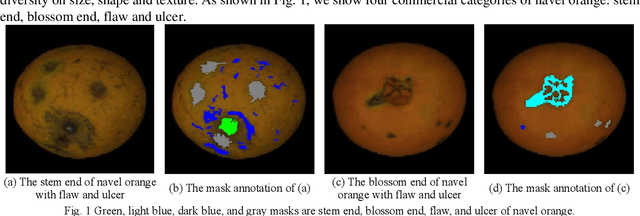


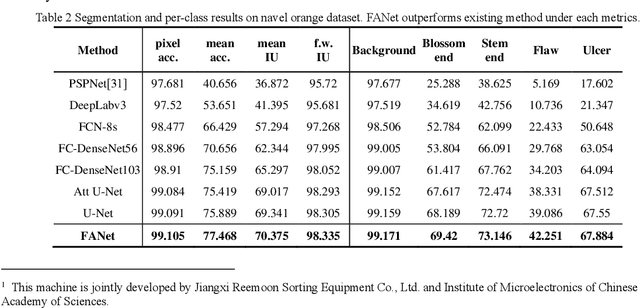
Deep learning achieves excellent performance in many domains, so we not only apply it to the navel orange semantic segmentation task to solve the two problems of distinguishing defect categories and identifying the stem end and blossom end, but also propose a fastidious attention mechanism to further improve model performance. This lightweight attention mechanism includes two learnable parameters, activations and thresholds, to capture long-range dependence. Specifically, the threshold picks out part of the spatial feature map and the activation excite this area. Based on activations and thresholds training from different types of feature maps, we design fastidious self-attention module (FSAM) and fastidious inter-attention module (FIAM). And then construct the Fastidious Attention Network (FANet), which uses U-Net as the backbone and embeds these two modules, to solve the problems with semantic segmentation for stem end, blossom end, flaw and ulcer. Compared with some state-of-the-art deep-learning-based networks under our navel orange dataset, experiments show that our network is the best performance with pixel accuracy 99.105%, mean accuracy 77.468%, mean IU 70.375% and frequency weighted IU 98.335%. And embedded modules show better discrimination of 5 categories including background, especially the IU of flaw is increased by 3.165%.
A Real-Time Tiny Detection Model for Stem End and Blossom End of Navel Orange
May 24, 2019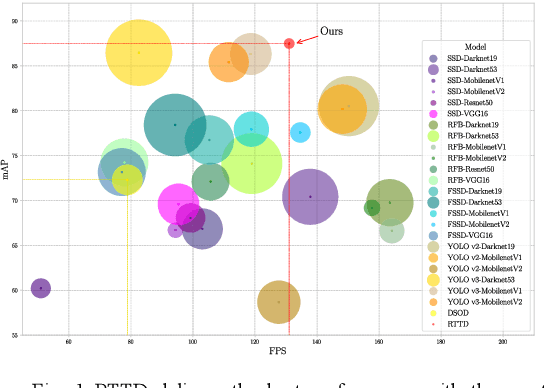
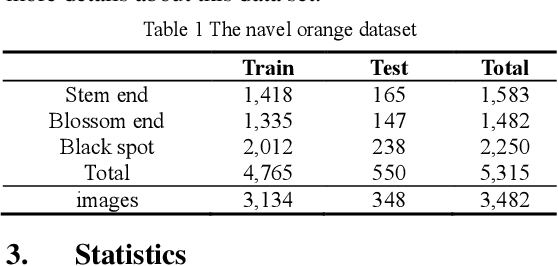
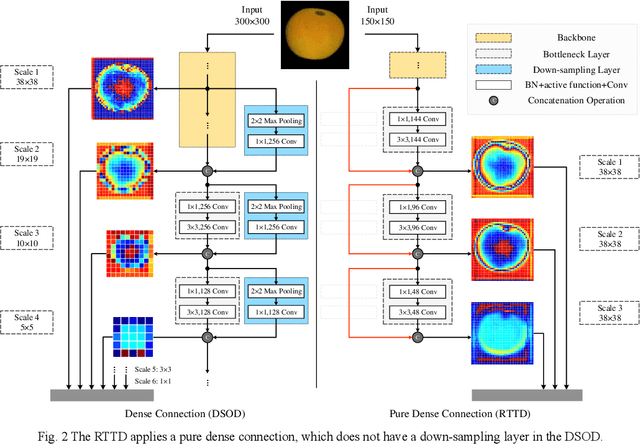
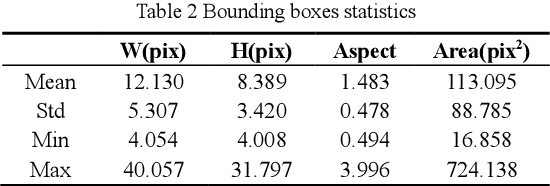
To distinguish the stem end and blossom end of navel orange from its black spot, we propose a real-time tiny detection model (RTTD) with low computational cost, compact architecture and high detection accuracy. In particular, based on the characteristics of the data, we apply pure dense connectivity to limit and simplify the design of the model architecture and use k-means clustering to set the size and aspect ratios of the default boxes. The architecture of model is based on deeply supervised object detectors (DSOD), and which reduces some components like dense block and prediction layers for efficient and adds some auxiliary structure like Squeeze-and-Excitation layer and Swish for accuracy. And we create a dataset in Pascal VOC format annotated the three types of detection targets stem end, blossom end and black spot. Experimental results on our orange data set confirm that RTTD has competitive results to the state-of-the-art one stage detectors like SSD, DSOD, YOLOv2, YOLOv3, RFB and FSSD, and it achieves 87.479%mAP at 131 FPS with only 5.812M parameters.