 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Round for Post-Training Quantization
Jul 07, 2022
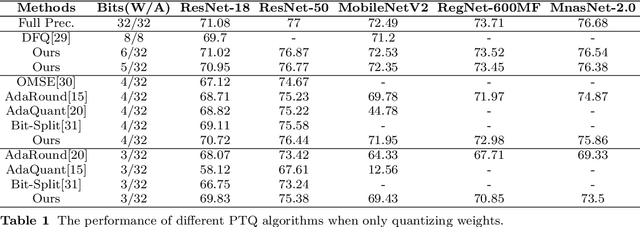
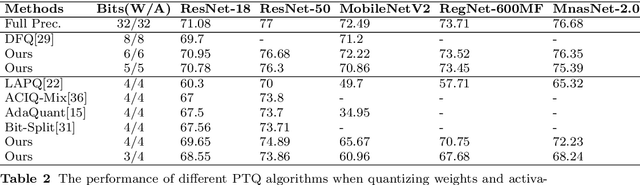
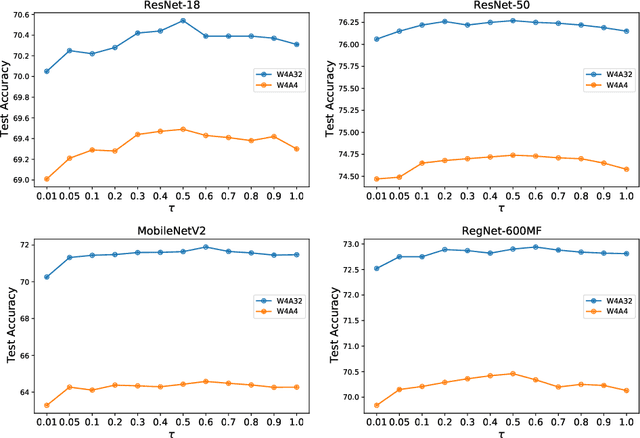
At present, the quantification methods of neural network models are mainly divided into post-training quantization (PTQ) and quantization aware training (QAT). Post-training quantization only need a small part of the data to complete the quantification process, but the performance of its quantitative model is not as good as the quantization aware training. This paper presents a novel quantification method called Attention Round. This method gives parameters w the opportunity to be mapped to all possible quantized values, rather than just the two quantized values nearby w in the process of quantization. The probability of being mapped to different quantified values is negatively correlated with the distance between the quantified values and w, and decay with a Gaussian function. In addition, this paper uses the lossy coding length as a measure to assign bit widths to the different layers of the model to solve the problem of mixed precision quantization, which effectively avoids to solve combinatorial optimization problem. This paper also performs quantitative experiments on different models, the results confirm the effectiveness of the proposed method. For ResNet18 and MobileNetV2, the post-training quantization proposed in this paper only require 1,024 training data and 10 minutes to complete the quantization process, which can achieve quantization performance on par with quantization aware training.