 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuning-Free Long Video Generation via Global-Local Collaborative Diffusion
Jan 08, 2025



Creating high-fidelity, coherent long videos is a sought-after aspiration. While recent video diffusion models have shown promising potential, they still grapple with spatiotemporal inconsistencies and high computational resource demands. We propose GLC-Diffusion, a tuning-free method for long video generation. It models the long video denoising process by establishing denoising trajectories through Global-Local Collaborative Denoising to ensure overall content consistency and temporal coherence between frames. Additionally, we introduce a Noise Reinitialization strategy which combines local noise shuffling with frequency fusion to improve global content consistency and visual diversity. Further, we propose a Video Motion Consistency Refinement (VMCR) module that computes the gradient of pixel-wise and frequency-wise losses to enhance visual consistency and temporal smoothness. Extensive experiments, including quantitative and qualitative evaluations on videos of varying lengths (\textit{e.g.}, 3\times and 6\times longer), demonstrate that our method effectively integrates with existing video diffusion models, producing coherent, high-fidelity long videos superior to previous approaches.
GRPose: Learning Graph Relations for Human Image Generation with Pose Priors
Aug 29, 2024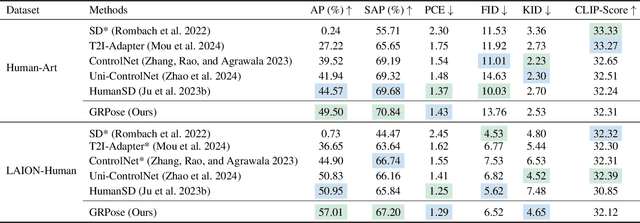



Recent methods using diffusion models have made significant progress in human image generation with various additional controls such as pose priors. However, existing approaches still struggle to generate high-quality images with consistent pose alignment, resulting in unsatisfactory outputs. In this paper, we propose a framework delving into the graph relations of pose priors to provide control information for human image generation. The main idea is to establish a graph topological structure between the pose priors and latent representation of diffusion models to capture the intrinsic associations between different pose parts. A Progressive Graph Integrator (PGI) is designed to learn the spatial relationships of the pose priors with the graph structure, adopting a hierarchical strategy within an Adapter to gradually propagate information across different pose parts. A pose perception loss is further introduced based on a pretrained pose estimation network to minimize the pose differences. Extensive qualitative and quantitative experiments conducted on the Human-Art and LAION-Human datasets demonstrate that our model achieves superior performance, with a 9.98% increase in pose average precision compared to the latest benchmark model. The code is released on *******.