 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCo-VAE: Learning Compact Latents for Video Reconstruction via Decoupled Representation
Nov 18, 2025Existing video Variational Autoencoders (VAEs) generally overlook the similarity between frame contents, leading to redundant latent modeling. In this paper, we propose decoupled VAE (DeCo-VAE) to achieve compact latent representation. Instead of encoding RGB pixels directly, we decompose video content into distinct components via explicit decoupling: keyframe, motion and residual, and learn dedicated latent representation for each. To avoid cross-component interference, we design dedicated encoders for each decoupled component and adopt a shared 3D decoder to maintain spatiotemporal consistency during reconstruction. We further utilize a decoupled adaptation strategy that freezes partial encoders while training the others sequentially, ensuring stable training and accurate learning of both static and dynamic features. Extensive quantitative and qualitative experiments demonstrate that DeCo-VAE achieves superior video reconstruction performance.
Structure-guided Diffusion Transformer for Low-Light Image Enhancement
Apr 21, 2025While the diffusion transformer (DiT) has become a focal point of interest in recent years, its application in low-light image enhancement remains a blank area for exploration. Current methods recover the details from low-light images while inevitably amplifying the noise in images, resulting in poor visual quality. In this paper, we firstly introduce DiT into the low-light enhancement task and design a novel Structure-guided Diffusion Transformer based Low-light image enhancement (SDTL) framework. We compress the feature through wavelet transform to improve the inference efficiency of the model and capture the multi-directional frequency band. Then we propose a Structure Enhancement Module (SEM) that uses structural prior to enhance the texture and leverages an adaptive fusion strategy to achieve more accurate enhancement effect. In Addition, we propose a Structure-guided Attention Block (SAB) to pay more attention to texture-riched tokens and avoid interference from noisy areas in noise prediction. Extensive qualitative and quantitative experiments demonstrate that our method achieves SOTA performance on several popular datasets, validating the effectiveness of SDTL in improving image quality and the potential of DiT in low-light enhancement tasks.
GRPose: Learning Graph Relations for Human Image Generation with Pose Priors
Aug 29, 2024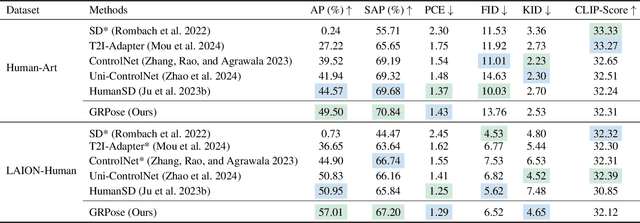



Recent methods using diffusion models have made significant progress in human image generation with various additional controls such as pose priors. However, existing approaches still struggle to generate high-quality images with consistent pose alignment, resulting in unsatisfactory outputs. In this paper, we propose a framework delving into the graph relations of pose priors to provide control information for human image generation. The main idea is to establish a graph topological structure between the pose priors and latent representation of diffusion models to capture the intrinsic associations between different pose parts. A Progressive Graph Integrator (PGI) is designed to learn the spatial relationships of the pose priors with the graph structure, adopting a hierarchical strategy within an Adapter to gradually propagate information across different pose parts. A pose perception loss is further introduced based on a pretrained pose estimation network to minimize the pose differences. Extensive qualitative and quantitative experiments conducted on the Human-Art and LAION-Human datasets demonstrate that our model achieves superior performance, with a 9.98% increase in pose average precision compared to the latest benchmark model. The code is released on *******.
DEFormer: DCT-driven Enhancement Transformer for Low-light Image and Dark Vision
Sep 13, 2023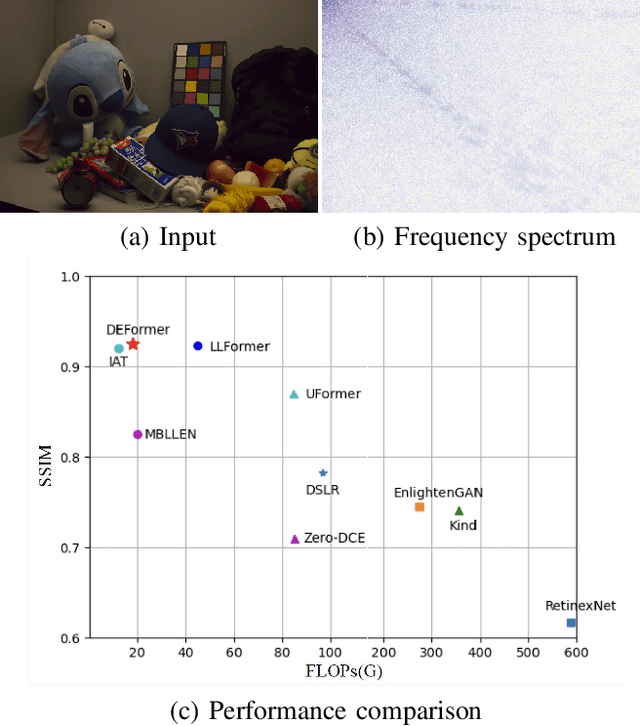

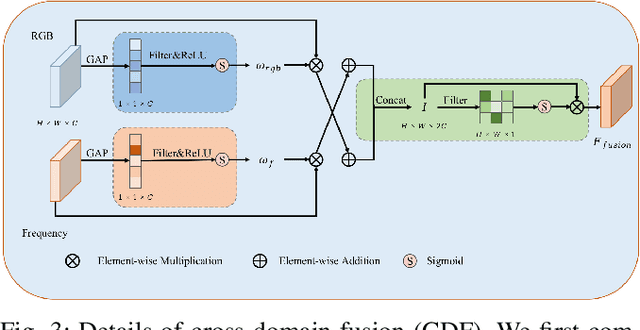

The goal of low-light image enhancement is to restore the color and details of the image and is of great significance for high-level visual tasks in autonomous driving. However, it is difficult to restore the lost details in the dark area by relying only on the RGB domain. In this paper we introduce frequency as a new clue into the network and propose a novel DCT-driven enhancement transformer (DEFormer). First, we propose a learnable frequency branch (LFB) for frequency enhancement contains DCT processing and curvature-based frequency enhancement (CFE). CFE calculates the curvature of each channel to represent the detail richness of different frequency bands, then we divides the frequency features, which focuses on frequency bands with richer textures. In addition, we propose a cross domain fusion (CDF) for reducing the differences between the RGB domain and the frequency domain. We also adopt DEFormer as a preprocessing in dark detection, DEFormer effectively improves the performance of the detector, bringing 2.1% and 3.4% improvement in ExDark and DARK FACE datasets on mAP respectively.
PE-YOLO: Pyramid Enhancement Network for Dark Object Detection
Jul 20, 2023Current object detection models have achieved good results on many benchmark datasets, detecting objects in dark conditions remains a large challenge. To address this issue, we propose a pyramid enhanced network (PENet) and joint it with YOLOv3 to build a dark object detection framework named PE-YOLO. Firstly, PENet decomposes the image into four components of different resolutions using the Laplacian pyramid. Specifically we propose a detail processing module (DPM) to enhance the detail of images, which consists of context branch and edge branch. In addition, we propose a low-frequency enhancement filter (LEF) to capture low-frequency semantics and prevent high-frequency noise. PE-YOLO adopts an end-to-end joint training approach and only uses normal detection loss to simplify the training process. We conduct experiments on the low-light object detection dataset ExDark to demonstrate the effectiveness of ours. The results indicate that compared with other dark detectors and low-light enhancement models, PE-YOLO achieves the advanced results, achieving 78.0% in mAP and 53.6 in FPS, respectively, which can adapt to object detection under different low-light conditions. The code is available at https://github.com/XiangchenYin/PE-YOLO.