 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Matters: Harnessing Video Models in Super-Resolution
Dec 16, 20243D super-resolution aims to reconstruct high-fidelity 3D models from low-resolution (LR) multi-view images. Early studies primarily focused on single-image super-resolution (SISR) models to upsample LR images into high-resolution images. However, these methods often lack view consistency because they operate independently on each image. Although various post-processing techniques have been extensively explored to mitigate these inconsistencies, they have yet to fully resolve the issues. In this paper, we perform a comprehensive study of 3D super-resolution by leveraging video super-resolution (VSR) models. By utilizing VSR models, we ensure a higher degree of spatial consistency and can reference surrounding spatial information, leading to more accurate and detailed reconstructions. Our findings reveal that VSR models can perform remarkably well even on sequences that lack precise spatial alignment. Given this observation, we propose a simple yet practical approach to align LR images without involving fine-tuning or generating 'smooth' trajectory from the trained 3D models over LR images. The experimental results show that the surprisingly simple algorithms can achieve the state-of-the-art results of 3D super-resolution tasks on standard benchmark datasets, such as the NeRF-synthetic and MipNeRF-360 datasets. Project page: https://ko-lani.github.io/Sequence-Matters
Freq-Mip-AA : Frequency Mip Representation for Anti-Aliasing Neural Radiance Fields
Jun 19, 2024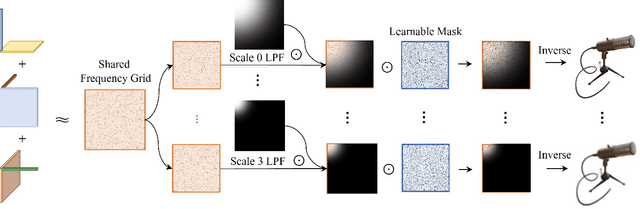
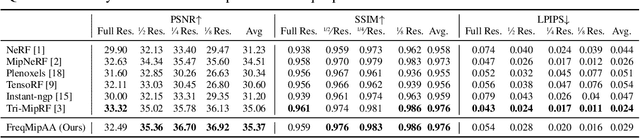


Neural Radiance Fields (NeRF) have shown remarkable success in representing 3D scenes and generating novel views. However, they often struggle with aliasing artifacts, especially when rendering images from different camera distances from the training views. To address the issue, Mip-NeRF proposed using volumetric frustums to render a pixel and suggested integrated positional encoding (IPE). While effective, this approach requires long training times due to its reliance on MLP architecture. In this work, we propose a novel anti-aliasing technique that utilizes grid-based representations, usually showing significantly faster training time. In addition, we exploit frequency-domain representation to handle the aliasing problem inspired by the sampling theorem. The proposed method, FreqMipAA, utilizes scale-specific low-pass filtering (LPF) and learnable frequency masks. Scale-specific low-pass filters (LPF) prevent aliasing and prioritize important image details, and learnable masks effectively remove problematic high-frequency elements while retaining essential information. By employing a scale-specific LPF and trainable masks, FreqMipAA can effectively eliminate the aliasing factor while retaining important details. We validated the proposed technique by incorporating it into a widely used grid-based method. The experimental results have shown that the FreqMipAA effectively resolved the aliasing issues and achieved state-of-the-art results in the multi-scale Blender dataset. Our code is available at https://github.com/yi0109/FreqMipAA .