 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError as Signal: Stiffness-Aware Diffusion Sampling via Embedded Runge-Kutta Guidance
Mar 04, 2026Classifier-Free Guidance (CFG) has established the foundation for guidance mechanisms in diffusion models, showing that well-designed guidance proxies significantly improve conditional generation and sample quality. Autoguidance (AG) has extended this idea, but it relies on an auxiliary network and leaves solver-induced errors unaddressed. In stiff regions, the ODE trajectory changes sharply, where local truncation error (LTE) becomes a critical factor that deteriorates sample quality. Our key observation is that these errors align with the dominant eigenvector, motivating us to leverage the solver-induced error as a guidance signal. We propose Embedded Runge-Kutta Guidance (ERK-Guid), which exploits detected stiffness to reduce LTE and stabilize sampling. We theoretically and empirically analyze stiffness and eigenvector estimators with solver errors to motivate the design of ERK-Guid. Our experiments on both synthetic datasets and the popular benchmark dataset, ImageNet, demonstrate that ERK-Guid consistently outperforms state-of-the-art methods. Code is available at https://github.com/mlvlab/ERK-Guid.
Extreme Weather Nowcasting via Local Precipitation Pattern Prediction
Feb 05, 2026Accurate forecasting of extreme weather events such as heavy rainfall or storms is critical for risk management and disaster mitigation. Although high-resolution radar observations have spurred extensive research on nowcasting models, precipitation nowcasting remains particularly challenging due to pronounced spatial locality, intricate fine-scale rainfall structures, and variability in forecasting horizons. While recent diffusion-based generative ensembles show promising results, they are computationally expensive and unsuitable for real-time applications. In contrast, deterministic models are computationally efficient but remain biased toward normal rainfall. Furthermore, the benchmark datasets commonly used in prior studies are themselves skewed--either dominated by ordinary rainfall events or restricted to extreme rainfall episodes--thereby hindering general applicability in real-world settings. In this paper, we propose exPreCast, an efficient deterministic framework for generating finely detailed radar forecasts, and introduce a newly constructed balanced radar dataset from the Korea Meteorological Administration (KMA), which encompasses both ordinary precipitation and extreme events. Our model integrates local spatiotemporal attention, a texture-preserving cubic dual upsampling decoder, and a temporal extractor to flexibly adjust forecasting horizons. Experiments on established benchmarks (SEVIR and MeteoNet) as well as on the balanced KMA dataset demonstrate that our approach achieves state-of-the-art performance, delivering accurate and reliable nowcasts across both normal and extreme rainfall regimes.
Discontinuous Galerkin finite element operator network for solving non-smooth PDEs
Jan 07, 2026We introduce Discontinuous Galerkin Finite Element Operator Network (DG--FEONet), a data-free operator learning framework that combines the strengths of the discontinuous Galerkin (DG) method with neural networks to solve parametric partial differential equations (PDEs) with discontinuous coefficients and non-smooth solutions. Unlike traditional operator learning models such as DeepONet and Fourier Neural Operator, which require large paired datasets and often struggle near sharp features, our approach minimizes the residual of a DG-based weak formulation using the Symmetric Interior Penalty Galerkin (SIPG) scheme. DG-FEONet predicts element-wise solution coefficients via a neural network, enabling data-free training without the need for precomputed input-output pairs. We provide theoretical justification through convergence analysis and validate the model's performance on a series of one- and two-dimensional PDE problems, demonstrating accurate recovery of discontinuities, strong generalization across parameter space, and reliable convergence rates. Our results highlight the potential of combining local discretization schemes with machine learning to achieve robust, singularity-aware operator approximation in challenging PDE settings.
Sobolev Approximation of Deep ReLU Network in Log-weighted Barron Space
Jan 03, 2026Universal approximation theorems show that neural networks can approximate any continuous function; however, the number of parameters may grow exponentially with the ambient dimension, so these results do not fully explain the practical success of deep models on high-dimensional data. Barron space theory addresses this: if a target function belongs to a Barron space, a two-layer network with $n$ parameters achieves an $O(n^{-1/2})$ approximation error in $L^2$. Yet classical Barron spaces $\mathscr{B}^{s+1}$ still require stronger regularity than Sobolev spaces $H^s$, and existing depth-sensitive results often assume constraints such as $sL \le 1/2$. In this paper, we introduce a log-weighted Barron space $\mathscr{B}^{\log}$, which requires a strictly weaker assumption than $\mathscr{B}^s$ for any $s>0$. For this new function space, we first study embedding properties and carry out a statistical analysis via the Rademacher complexity. Then we prove that functions in $\mathscr{B}^{\log}$ can be approximated by deep ReLU networks with explicit depth dependence. We then define a family $\mathscr{B}^{s,\log}$, establish approximation bounds in the $H^1$ norm, and identify maximal depth scales under which these rates are preserved. Our results clarify how depth reduces regularity requirements for efficient representation, offering a more precise explanation for the performance of deep architectures beyond the classical Barron setting, and for their stable use in high-dimensional problems used today.
Toward a Robust and Generalizable Metamaterial Foundation Model
Jul 03, 2025Advances in material functionalities drive innovations across various fields, where metamaterials-defined by structure rather than composition-are leading the way. Despite the rise of artificial intelligence (AI)-driven design strategies, their impact is limited by task-specific retraining, poor out-of-distribution(OOD) generalization, and the need for separate models for forward and inverse design. To address these limitations, we introduce the Metamaterial Foundation Model (MetaFO), a Bayesian transformer-based foundation model inspired by large language models. MetaFO learns the underlying mechanics of metamaterials, enabling probabilistic, zero-shot predictions across diverse, unseen combinations of material properties and structural responses. It also excels in nonlinear inverse design, even under OOD conditions. By treating metamaterials as an operator that maps material properties to structural responses, MetaFO uncovers intricate structure-property relationships and significantly expands the design space. This scalable and generalizable framework marks a paradigm shift in AI-driven metamaterial discovery, paving the way for next-generation innovations.
PIG: Physics-Informed Gaussians as Adaptive Parametric Mesh Representations
Dec 08, 2024The approximation of Partial Differential Equations (PDEs) using neural networks has seen significant advancements through Physics-Informed Neural Networks (PINNs). Despite their straightforward optimization framework and flexibility in implementing various PDEs, PINNs often suffer from limited accuracy due to the spectral bias of Multi-Layer Perceptrons (MLPs), which struggle to effectively learn high-frequency and non-linear components. Recently, parametric mesh representations in combination with neural networks have been investigated as a promising approach to eliminate the inductive biases of neural networks. However, they usually require very high-resolution grids and a large number of collocation points to achieve high accuracy while avoiding overfitting issues. In addition, the fixed positions of the mesh parameters restrict their flexibility, making it challenging to accurately approximate complex PDEs. To overcome these limitations, we propose Physics-Informed Gaussians (PIGs), which combine feature embeddings using Gaussian functions with a lightweight neural network. Our approach uses trainable parameters for the mean and variance of each Gaussian, allowing for dynamic adjustment of their positions and shapes during training. This adaptability enables our model to optimally approximate PDE solutions, unlike models with fixed parameter positions. Furthermore, the proposed approach maintains the same optimization framework used in PINNs, allowing us to benefit from their excellent properties. Experimental results show the competitive performance of our model across various PDEs, demonstrating its potential as a robust tool for solving complex PDEs. Our project page is available at https://namgyukang.github.io/Physics-Informed-Gaussians/
Constant Acceleration Flow
Nov 01, 2024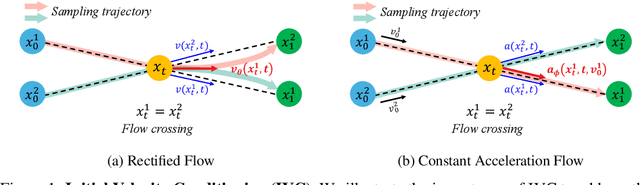
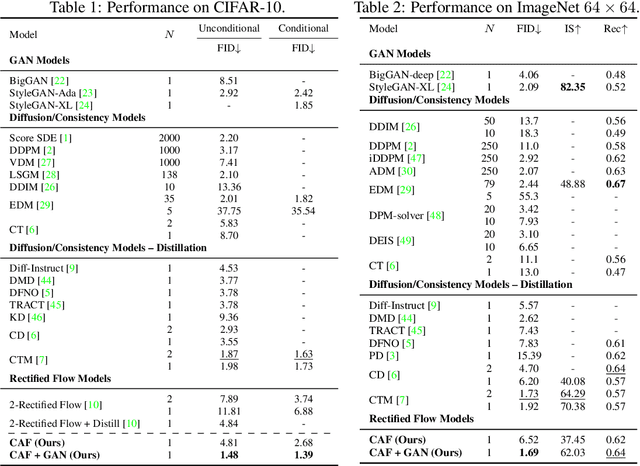
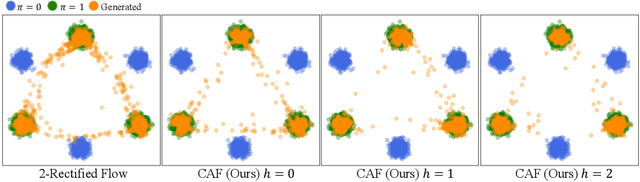
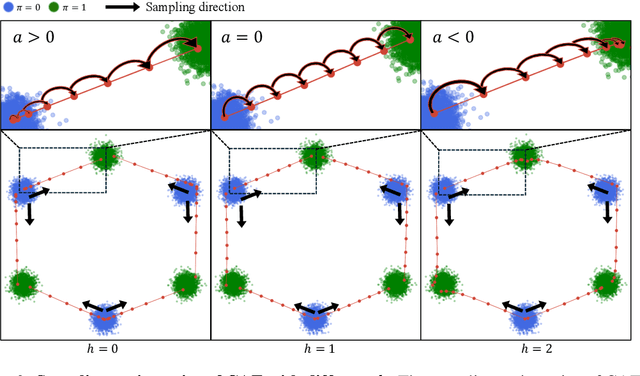
Rectified flow and reflow procedures have significantly advanced fast generation by progressively straightening ordinary differential equation (ODE) flows. They operate under the assumption that image and noise pairs, known as couplings, can be approximated by straight trajectories with constant velocity. However, we observe that modeling with constant velocity and using reflow procedures have limitations in accurately learning straight trajectories between pairs, resulting in suboptimal performance in few-step generation. To address these limitations, we introduce Constant Acceleration Flow (CAF), a novel framework based on a simple constant acceleration equation. CAF introduces acceleration as an additional learnable variable, allowing for more expressive and accurate estimation of the ODE flow. Moreover, we propose two techniques to further improve estimation accuracy: initial velocity conditioning for the acceleration model and a reflow process for the initial velocity. Our comprehensive studies on toy datasets, CIFAR-10, and ImageNet 64x64 demonstrate that CAF outperforms state-of-the-art baselines for one-step generation. We also show that CAF dramatically improves few-step coupling preservation and inversion over Rectified flow. Code is available at \href{https://github.com/mlvlab/CAF}{https://github.com/mlvlab/CAF}.
MaD-Scientist: AI-based Scientist solving Convection-Diffusion-Reaction Equations Using Massive PINN-Based Prior Data
Oct 09, 2024



Large language models (LLMs), like ChatGPT, have shown that even trained with noisy prior data, they can generalize effectively to new tasks through in-context learning (ICL) and pre-training techniques. Motivated by this, we explore whether a similar approach can be applied to scientific foundation models (SFMs). Our methodology is structured as follows: (i) we collect low-cost physics-informed neural network (PINN)-based approximated prior data in the form of solutions to partial differential equations (PDEs) constructed through an arbitrary linear combination of mathematical dictionaries; (ii) we utilize Transformer architectures with self and cross-attention mechanisms to predict PDE solutions without knowledge of the governing equations in a zero-shot setting; (iii) we provide experimental evidence on the one-dimensional convection-diffusion-reaction equation, which demonstrate that pre-training remains robust even with approximated prior data, with only marginal impacts on test accuracy. Notably, this finding opens the path to pre-training SFMs with realistic, low-cost data instead of (or in conjunction with) numerical high-cost data. These results support the conjecture that SFMs can improve in a manner similar to LLMs, where fully cleaning the vast set of sentences crawled from the Internet is nearly impossible.
Error analysis for finite element operator learning methods for solving parametric second-order elliptic PDEs
Apr 27, 2024In this paper, we provide a theoretical analysis of a type of operator learning method without data reliance based on the classical finite element approximation, which is called the finite element operator network (FEONet). We first establish the convergence of this method for general second-order linear elliptic PDEs with respect to the parameters for neural network approximation. In this regard, we address the role of the condition number of the finite element matrix in the convergence of the method. Secondly, we derive an explicit error estimate for the self-adjoint case. For this, we investigate some regularity properties of the solution in certain function classes for a neural network approximation, verifying the sufficient condition for the solution to have the desired regularity. Finally, we will also conduct some numerical experiments that support the theoretical findings, confirming the role of the condition number of the finite element matrix in the overall convergence.
Separable Physics-informed Neural Networks for Solving the BGK Model of the Boltzmann Equation
Mar 10, 2024



In this study, we introduce a method based on Separable Physics-Informed Neural Networks (SPINNs) for effectively solving the BGK model of the Boltzmann equation. While the mesh-free nature of PINNs offers significant advantages in handling high-dimensional partial differential equations (PDEs), challenges arise when applying quadrature rules for accurate integral evaluation in the BGK operator, which can compromise the mesh-free benefit and increase computational costs. To address this, we leverage the canonical polyadic decomposition structure of SPINNs and the linear nature of moment calculation, achieving a substantial reduction in computational expense for quadrature rule application. The multi-scale nature of the particle density function poses difficulties in precisely approximating macroscopic moments using neural networks. To improve SPINN training, we introduce the integration of Gaussian functions into SPINNs, coupled with a relative loss approach. This modification enables SPINNs to decay as rapidly as Maxwellian distributions, thereby enhancing the accuracy of macroscopic moment approximations. The relative loss design further ensures that both large and small-scale features are effectively captured by the SPINNs. The efficacy of our approach is demonstrated through a series of five numerical experiments, including the solution to a challenging 3D Riemann problem. These results highlight the potential of our novel method in efficiently and accurately addressing complex challenges in computational physics.