 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstant Acceleration Flow
Nov 01, 2024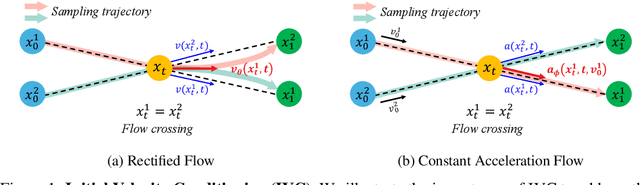
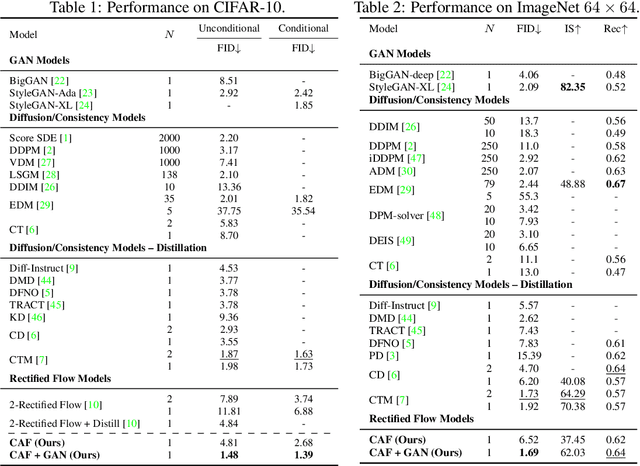
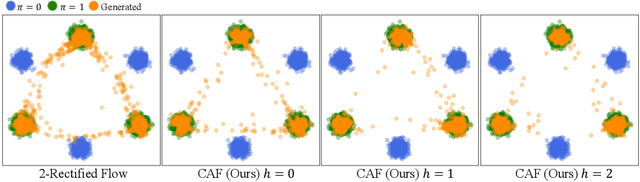
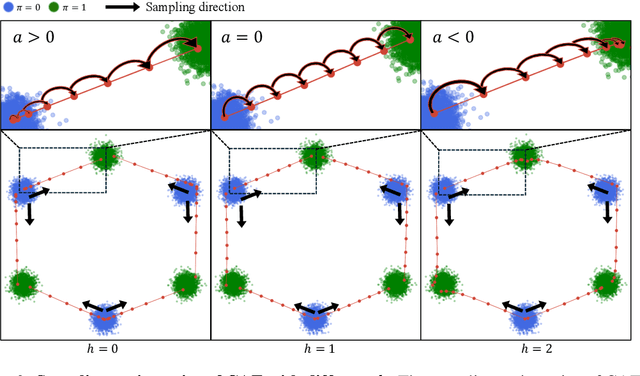
Rectified flow and reflow procedures have significantly advanced fast generation by progressively straightening ordinary differential equation (ODE) flows. They operate under the assumption that image and noise pairs, known as couplings, can be approximated by straight trajectories with constant velocity. However, we observe that modeling with constant velocity and using reflow procedures have limitations in accurately learning straight trajectories between pairs, resulting in suboptimal performance in few-step generation. To address these limitations, we introduce Constant Acceleration Flow (CAF), a novel framework based on a simple constant acceleration equation. CAF introduces acceleration as an additional learnable variable, allowing for more expressive and accurate estimation of the ODE flow. Moreover, we propose two techniques to further improve estimation accuracy: initial velocity conditioning for the acceleration model and a reflow process for the initial velocity. Our comprehensive studies on toy datasets, CIFAR-10, and ImageNet 64x64 demonstrate that CAF outperforms state-of-the-art baselines for one-step generation. We also show that CAF dramatically improves few-step coupling preservation and inversion over Rectified flow. Code is available at \href{https://github.com/mlvlab/CAF}{https://github.com/mlvlab/CAF}.
Diffusion Prior-Based Amortized Variational Inference for Noisy Inverse Problems
Jul 23, 2024
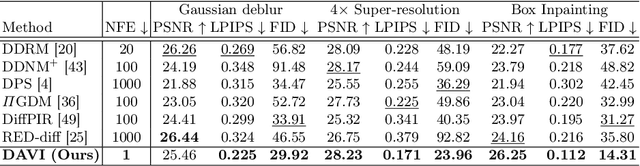
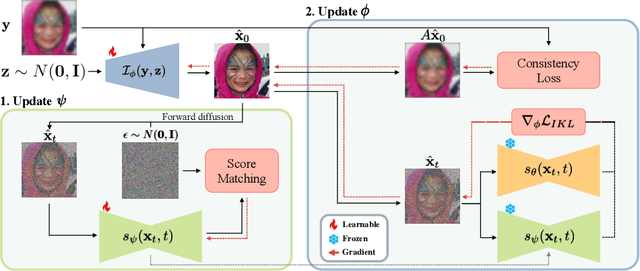
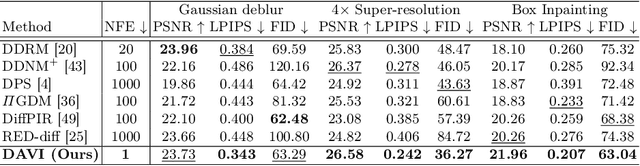
Recent studies on inverse problems have proposed posterior samplers that leverage the pre-trained diffusion models as powerful priors. These attempts have paved the way for using diffusion models in a wide range of inverse problems. However, the existing methods entail computationally demanding iterative sampling procedures and optimize a separate solution for each measurement, which leads to limited scalability and lack of generalization capability across unseen samples. To address these limitations, we propose a novel approach, Diffusion prior-based Amortized Variational Inference (DAVI) that solves inverse problems with a diffusion prior from an amortized variational inference perspective. Specifically, instead of separate measurement-wise optimization, our amortized inference learns a function that directly maps measurements to the implicit posterior distributions of corresponding clean data, enabling a single-step posterior sampling even for unseen measurements. Extensive experiments on image restoration tasks, e.g., Gaussian deblur, 4$\times$ super-resolution, and box inpainting with two benchmark datasets, demonstrate our approach's superior performance over strong baselines. Code is available at https://github.com/mlvlab/DAVI.
Stochastic Conditional Diffusion Models for Semantic Image Synthesis
Feb 27, 2024



Semantic image synthesis (SIS) is a task to generate realistic images corresponding to semantic maps (labels). It can be applied to diverse real-world practices such as photo editing or content creation. However, in real-world applications, SIS often encounters noisy user inputs. To address this, we propose Stochastic Conditional Diffusion Model (SCDM), which is a robust conditional diffusion model that features novel forward and generation processes tailored for SIS with noisy labels. It enhances robustness by stochastically perturbing the semantic label maps through Label Diffusion, which diffuses the labels with discrete diffusion. Through the diffusion of labels, the noisy and clean semantic maps become similar as the timestep increases, eventually becoming identical at $t=T$. This facilitates the generation of an image close to a clean image, enabling robust generation. Furthermore, we propose a class-wise noise schedule to differentially diffuse the labels depending on the class. We demonstrate that the proposed method generates high-quality samples through extensive experiments and analyses on benchmark datasets, including a novel experimental setup simulating human errors during real-world applications.
DDMI: Domain-Agnostic Latent Diffusion Models for Synthesizing High-Quality Implicit Neural Representations
Jan 23, 2024Recent studies have introduced a new class of generative models for synthesizing implicit neural representations (INRs) that capture arbitrary continuous signals in various domains. These models opened the door for domain-agnostic generative models, but they often fail to achieve high-quality generation. We observed that the existing methods generate the weights of neural networks to parameterize INRs and evaluate the network with fixed positional embeddings (PEs). Arguably, this architecture limits the expressive power of generative models and results in low-quality INR generation. To address this limitation, we propose Domain-agnostic Latent Diffusion Model for INRs (DDMI) that generates adaptive positional embeddings instead of neural networks' weights. Specifically, we develop a Discrete-to-continuous space Variational AutoEncoder (D2C-VAE), which seamlessly connects discrete data and the continuous signal functions in the shared latent space. Additionally, we introduce a novel conditioning mechanism for evaluating INRs with the hierarchically decomposed PEs to further enhance expressive power. Extensive experiments across four modalities, e.g., 2D images, 3D shapes, Neural Radiance Fields, and videos, with seven benchmark datasets, demonstrate the versatility of DDMI and its superior performance compared to the existing INR generative models.
Probabilistic Precision and Recall Towards Reliable Evaluation of Generative Models
Sep 04, 2023Assessing the fidelity and diversity of the generative model is a difficult but important issue for technological advancement. So, recent papers have introduced k-Nearest Neighbor ($k$NN) based precision-recall metrics to break down the statistical distance into fidelity and diversity. While they provide an intuitive method, we thoroughly analyze these metrics and identify oversimplified assumptions and undesirable properties of kNN that result in unreliable evaluation, such as susceptibility to outliers and insensitivity to distributional changes. Thus, we propose novel metrics, P-precision and P-recall (PP\&PR), based on a probabilistic approach that address the problems. Through extensive investigations on toy experiments and state-of-the-art generative models, we show that our PP\&PR provide more reliable estimates for comparing fidelity and diversity than the existing metrics. The codes are available at \url{https://github.com/kdst-team/Probablistic_precision_recall}.
NaturalInversion: Data-Free Image Synthesis Improving Real-World Consistency
Jun 29, 2023



We introduce NaturalInversion, a novel model inversion-based method to synthesize images that agrees well with the original data distribution without using real data. In NaturalInversion, we propose: (1) a Feature Transfer Pyramid which uses enhanced image prior of the original data by combining the multi-scale feature maps extracted from the pre-trained classifier, (2) a one-to-one approach generative model where only one batch of images are synthesized by one generator to bring the non-linearity to optimization and to ease the overall optimizing process, (3) learnable Adaptive Channel Scaling parameters which are end-to-end trained to scale the output image channel to utilize the original image prior further. With our NaturalInversion, we synthesize images from classifiers trained on CIFAR-10/100 and show that our images are more consistent with original data distribution than prior works by visualization and additional analysis. Furthermore, our synthesized images outperform prior works on various applications such as knowledge distillation and pruning, demonstrating the effectiveness of our proposed method.
* Published at AAAI 2022