 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Prior-Based Amortized Variational Inference for Noisy Inverse Problems
Jul 23, 2024
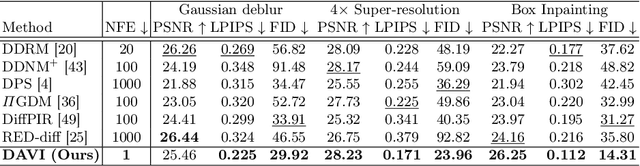
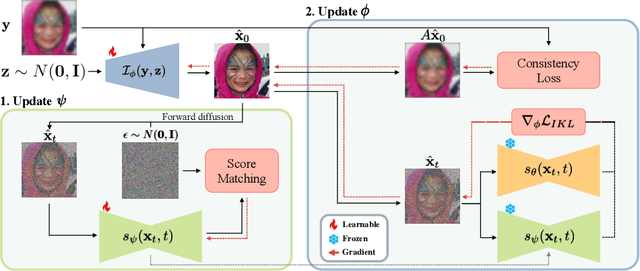
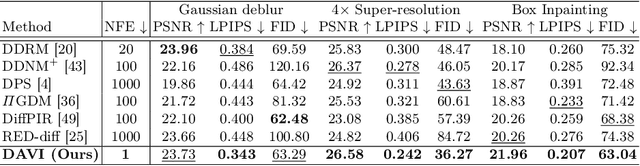
Recent studies on inverse problems have proposed posterior samplers that leverage the pre-trained diffusion models as powerful priors. These attempts have paved the way for using diffusion models in a wide range of inverse problems. However, the existing methods entail computationally demanding iterative sampling procedures and optimize a separate solution for each measurement, which leads to limited scalability and lack of generalization capability across unseen samples. To address these limitations, we propose a novel approach, Diffusion prior-based Amortized Variational Inference (DAVI) that solves inverse problems with a diffusion prior from an amortized variational inference perspective. Specifically, instead of separate measurement-wise optimization, our amortized inference learns a function that directly maps measurements to the implicit posterior distributions of corresponding clean data, enabling a single-step posterior sampling even for unseen measurements. Extensive experiments on image restoration tasks, e.g., Gaussian deblur, 4$\times$ super-resolution, and box inpainting with two benchmark datasets, demonstrate our approach's superior performance over strong baselines. Code is available at https://github.com/mlvlab/DAVI.
Stochastic Conditional Diffusion Models for Semantic Image Synthesis
Feb 27, 2024



Semantic image synthesis (SIS) is a task to generate realistic images corresponding to semantic maps (labels). It can be applied to diverse real-world practices such as photo editing or content creation. However, in real-world applications, SIS often encounters noisy user inputs. To address this, we propose Stochastic Conditional Diffusion Model (SCDM), which is a robust conditional diffusion model that features novel forward and generation processes tailored for SIS with noisy labels. It enhances robustness by stochastically perturbing the semantic label maps through Label Diffusion, which diffuses the labels with discrete diffusion. Through the diffusion of labels, the noisy and clean semantic maps become similar as the timestep increases, eventually becoming identical at $t=T$. This facilitates the generation of an image close to a clean image, enabling robust generation. Furthermore, we propose a class-wise noise schedule to differentially diffuse the labels depending on the class. We demonstrate that the proposed method generates high-quality samples through extensive experiments and analyses on benchmark datasets, including a novel experimental setup simulating human errors during real-world applications.