 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError as Signal: Stiffness-Aware Diffusion Sampling via Embedded Runge-Kutta Guidance
Mar 04, 2026Classifier-Free Guidance (CFG) has established the foundation for guidance mechanisms in diffusion models, showing that well-designed guidance proxies significantly improve conditional generation and sample quality. Autoguidance (AG) has extended this idea, but it relies on an auxiliary network and leaves solver-induced errors unaddressed. In stiff regions, the ODE trajectory changes sharply, where local truncation error (LTE) becomes a critical factor that deteriorates sample quality. Our key observation is that these errors align with the dominant eigenvector, motivating us to leverage the solver-induced error as a guidance signal. We propose Embedded Runge-Kutta Guidance (ERK-Guid), which exploits detected stiffness to reduce LTE and stabilize sampling. We theoretically and empirically analyze stiffness and eigenvector estimators with solver errors to motivate the design of ERK-Guid. Our experiments on both synthetic datasets and the popular benchmark dataset, ImageNet, demonstrate that ERK-Guid consistently outperforms state-of-the-art methods. Code is available at https://github.com/mlvlab/ERK-Guid.
Constant Acceleration Flow
Nov 01, 2024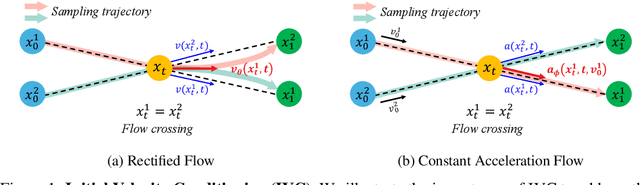
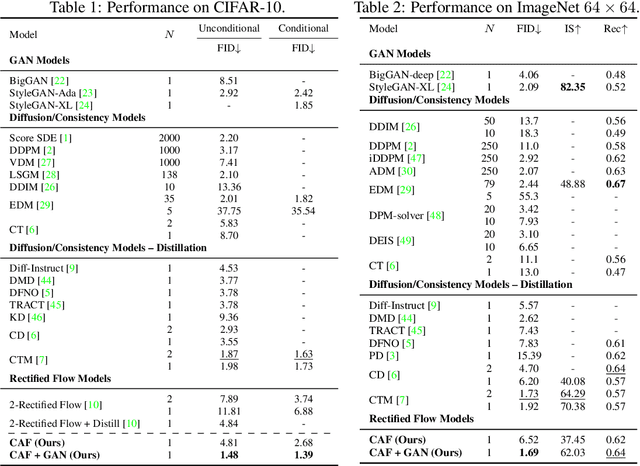
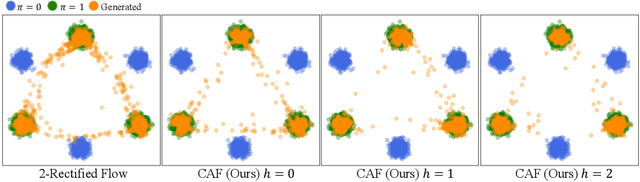
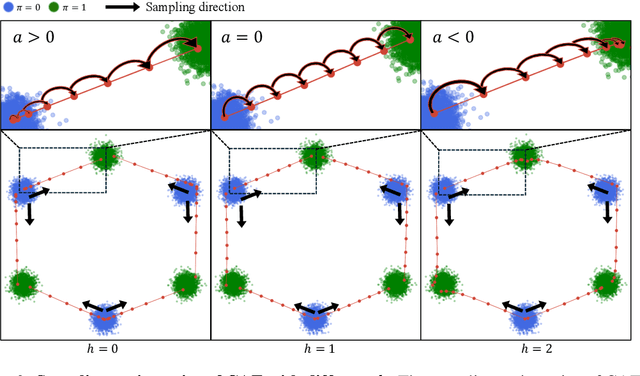
Rectified flow and reflow procedures have significantly advanced fast generation by progressively straightening ordinary differential equation (ODE) flows. They operate under the assumption that image and noise pairs, known as couplings, can be approximated by straight trajectories with constant velocity. However, we observe that modeling with constant velocity and using reflow procedures have limitations in accurately learning straight trajectories between pairs, resulting in suboptimal performance in few-step generation. To address these limitations, we introduce Constant Acceleration Flow (CAF), a novel framework based on a simple constant acceleration equation. CAF introduces acceleration as an additional learnable variable, allowing for more expressive and accurate estimation of the ODE flow. Moreover, we propose two techniques to further improve estimation accuracy: initial velocity conditioning for the acceleration model and a reflow process for the initial velocity. Our comprehensive studies on toy datasets, CIFAR-10, and ImageNet 64x64 demonstrate that CAF outperforms state-of-the-art baselines for one-step generation. We also show that CAF dramatically improves few-step coupling preservation and inversion over Rectified flow. Code is available at \href{https://github.com/mlvlab/CAF}{https://github.com/mlvlab/CAF}.
Diffusion Prior-Based Amortized Variational Inference for Noisy Inverse Problems
Jul 23, 2024
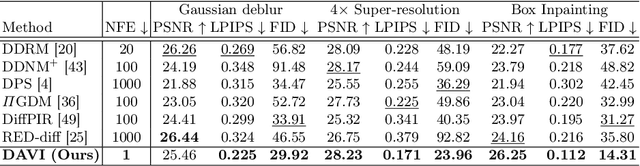
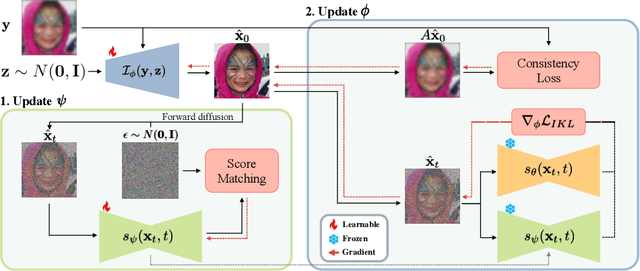
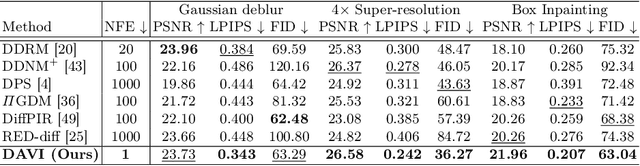
Recent studies on inverse problems have proposed posterior samplers that leverage the pre-trained diffusion models as powerful priors. These attempts have paved the way for using diffusion models in a wide range of inverse problems. However, the existing methods entail computationally demanding iterative sampling procedures and optimize a separate solution for each measurement, which leads to limited scalability and lack of generalization capability across unseen samples. To address these limitations, we propose a novel approach, Diffusion prior-based Amortized Variational Inference (DAVI) that solves inverse problems with a diffusion prior from an amortized variational inference perspective. Specifically, instead of separate measurement-wise optimization, our amortized inference learns a function that directly maps measurements to the implicit posterior distributions of corresponding clean data, enabling a single-step posterior sampling even for unseen measurements. Extensive experiments on image restoration tasks, e.g., Gaussian deblur, 4$\times$ super-resolution, and box inpainting with two benchmark datasets, demonstrate our approach's superior performance over strong baselines. Code is available at https://github.com/mlvlab/DAVI.
A Comprehensive Survey of Compression Algorithms for Language Models
Jan 27, 2024How can we compress language models without sacrificing accuracy? The number of compression algorithms for language models is rapidly growing to benefit from remarkable advances of recent language models without side effects due to the gigantic size of language models, such as increased carbon emissions and expensive maintenance fees. While numerous compression algorithms have shown remarkable progress in compressing language models, it ironically becomes challenging to capture emerging trends and identify the fundamental concepts underlying them due to the excessive number of algorithms. In this paper, we survey and summarize diverse compression algorithms including pruning, quantization, knowledge distillation, low-rank approximation, parameter sharing, and efficient architecture design. We not only summarize the overall trend of diverse compression algorithms but also select representative algorithms and provide in-depth analyses of them. We discuss the value of each category of compression algorithms, and the desired properties of low-cost compression algorithms which have a significant impact due to the emergence of large language models. Finally, we introduce promising future research topics based on our survey results.
DDMI: Domain-Agnostic Latent Diffusion Models for Synthesizing High-Quality Implicit Neural Representations
Jan 23, 2024Recent studies have introduced a new class of generative models for synthesizing implicit neural representations (INRs) that capture arbitrary continuous signals in various domains. These models opened the door for domain-agnostic generative models, but they often fail to achieve high-quality generation. We observed that the existing methods generate the weights of neural networks to parameterize INRs and evaluate the network with fixed positional embeddings (PEs). Arguably, this architecture limits the expressive power of generative models and results in low-quality INR generation. To address this limitation, we propose Domain-agnostic Latent Diffusion Model for INRs (DDMI) that generates adaptive positional embeddings instead of neural networks' weights. Specifically, we develop a Discrete-to-continuous space Variational AutoEncoder (D2C-VAE), which seamlessly connects discrete data and the continuous signal functions in the shared latent space. Additionally, we introduce a novel conditioning mechanism for evaluating INRs with the hierarchically decomposed PEs to further enhance expressive power. Extensive experiments across four modalities, e.g., 2D images, 3D shapes, Neural Radiance Fields, and videos, with seven benchmark datasets, demonstrate the versatility of DDMI and its superior performance compared to the existing INR generative models.