 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLDX-1 Technical Report
May 05, 2026While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-Language Models, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, memory-aware decision making, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including synthesizing training data for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. $π_{0.5}$ and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while $π_{0.5}$ and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.
Unifying Uniform and Binary-coding Quantization for Accurate Compression of Large Language Models
Jun 04, 2025How can we quantize large language models while preserving accuracy? Quantization is essential for deploying large language models (LLMs) efficiently. Binary-coding quantization (BCQ) and uniform quantization (UQ) are promising quantization schemes that have strong expressiveness and optimizability, respectively. However, neither scheme leverages both advantages. In this paper, we propose UniQuanF (Unified Quantization with Flexible Mapping), an accurate quantization method for LLMs. UniQuanF harnesses both strong expressiveness and optimizability by unifying the flexible mapping technique in UQ and non-uniform quantization levels of BCQ. We propose unified initialization, and local and periodic mapping techniques to optimize the parameters in UniQuanF precisely. After optimization, our unification theorem removes computational and memory overhead, allowing us to utilize the superior accuracy of UniQuanF without extra deployment costs induced by the unification. Experimental results demonstrate that UniQuanF outperforms existing UQ and BCQ methods, achieving up to 4.60% higher accuracy on GSM8K benchmark.
A Comprehensive Survey of Compression Algorithms for Language Models
Jan 27, 2024How can we compress language models without sacrificing accuracy? The number of compression algorithms for language models is rapidly growing to benefit from remarkable advances of recent language models without side effects due to the gigantic size of language models, such as increased carbon emissions and expensive maintenance fees. While numerous compression algorithms have shown remarkable progress in compressing language models, it ironically becomes challenging to capture emerging trends and identify the fundamental concepts underlying them due to the excessive number of algorithms. In this paper, we survey and summarize diverse compression algorithms including pruning, quantization, knowledge distillation, low-rank approximation, parameter sharing, and efficient architecture design. We not only summarize the overall trend of diverse compression algorithms but also select representative algorithms and provide in-depth analyses of them. We discuss the value of each category of compression algorithms, and the desired properties of low-cost compression algorithms which have a significant impact due to the emergence of large language models. Finally, we introduce promising future research topics based on our survey results.
Knowledge-preserving Pruning for Pre-trained Language Models without Retraining
Aug 07, 2023



Given a pre-trained language model, how can we efficiently compress it without retraining? Retraining-free structured pruning algorithms are crucial in pre-trained language model compression due to their significantly reduced pruning cost and capability to prune large language models. However, existing retraining-free algorithms encounter severe accuracy degradation, as they fail to preserve the useful knowledge of pre-trained models. In this paper, we propose K-pruning (Knowledge-preserving pruning), an accurate retraining-free structured pruning algorithm for pre-trained language models. K-pruning identifies and prunes attention heads and neurons deemed to be superfluous, based on the amount of their inherent knowledge. K-pruning applies an iterative process of pruning followed by knowledge reconstruction for each sub-layer to preserve the knowledge of the pre-trained models. Consequently, K-pruning shows up to 58.02%p higher F1 score than existing retraining-free pruning algorithms under a high compression rate of 80% on the SQuAD benchmark.
How to Pick the Best Source Data? Measuring Transferability for Heterogeneous Domains
Dec 23, 2019

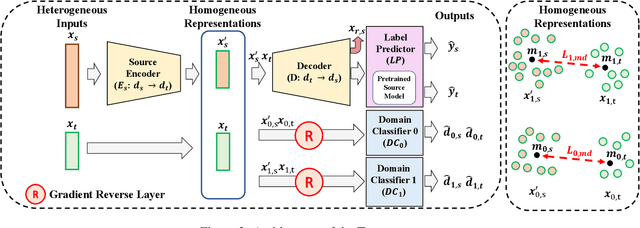

Given a set of source data with pre-trained classification models, how can we fast and accurately select the most useful source data to improve the performance of a target task? We address the problem of measuring transferability for heterogeneous domains, where the source and the target data have different feature spaces and distributions. We propose Transmeter, a novel method to efficiently and accurately measure transferability of two datasets. Transmeter utilizes a pre-trained source classifier and a reconstruction loss to increase its efficiency and performance. Furthermore, Transmeter uses feature transformation layers, label-wise discriminators, and a mean distance loss to learn common representations for source and target domains. As a result, Transmeter and its variant give the most accurate performance in measuring transferability, while giving comparable running times compared to those of competitors.