 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLampQ: Towards Accurate Layer-wise Mixed Precision Quantization for Vision Transformers
Nov 14, 2025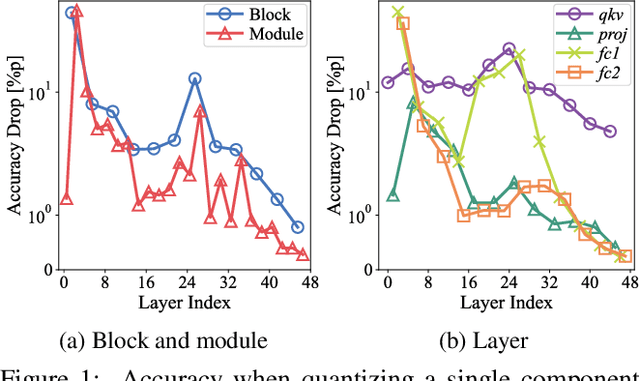

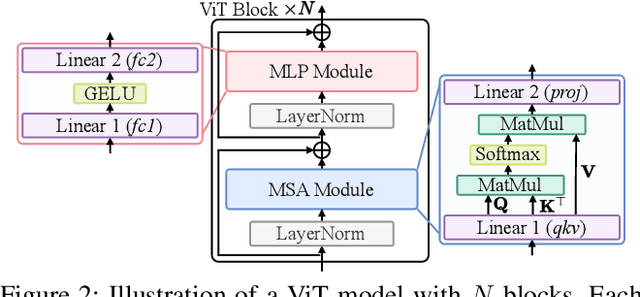

How can we accurately quantize a pre-trained Vision Transformer model? Quantization algorithms compress Vision Transformers (ViTs) into low-bit formats, reducing memory and computation demands with minimal accuracy degradation. However, existing methods rely on uniform precision, ignoring the diverse sensitivity of ViT components to quantization. Metric-based Mixed Precision Quantization (MPQ) is a promising alternative, but previous MPQ methods for ViTs suffer from three major limitations: 1) coarse granularity, 2) mismatch in metric scale across component types, and 3) quantization-unaware bit allocation. In this paper, we propose LampQ (Layer-wise Mixed Precision Quantization for Vision Transformers), an accurate metric-based MPQ method for ViTs to overcome these limitations. LampQ performs layer-wise quantization to achieve both fine-grained control and efficient acceleration, incorporating a type-aware Fisher-based metric to measure sensitivity. Then, LampQ assigns bit-widths optimally through integer linear programming and further updates them iteratively. Extensive experiments show that LampQ provides the state-of-the-art performance in quantizing ViTs pre-trained on various tasks such as image classification, object detection, and zero-shot quantization.
Unifying Uniform and Binary-coding Quantization for Accurate Compression of Large Language Models
Jun 04, 2025How can we quantize large language models while preserving accuracy? Quantization is essential for deploying large language models (LLMs) efficiently. Binary-coding quantization (BCQ) and uniform quantization (UQ) are promising quantization schemes that have strong expressiveness and optimizability, respectively. However, neither scheme leverages both advantages. In this paper, we propose UniQuanF (Unified Quantization with Flexible Mapping), an accurate quantization method for LLMs. UniQuanF harnesses both strong expressiveness and optimizability by unifying the flexible mapping technique in UQ and non-uniform quantization levels of BCQ. We propose unified initialization, and local and periodic mapping techniques to optimize the parameters in UniQuanF precisely. After optimization, our unification theorem removes computational and memory overhead, allowing us to utilize the superior accuracy of UniQuanF without extra deployment costs induced by the unification. Experimental results demonstrate that UniQuanF outperforms existing UQ and BCQ methods, achieving up to 4.60% higher accuracy on GSM8K benchmark.
Zero-shot Quantization: A Comprehensive Survey
May 14, 2025Network quantization has proven to be a powerful approach to reduce the memory and computational demands of deep learning models for deployment on resource-constrained devices. However, traditional quantization methods often rely on access to training data, which is impractical in many real-world scenarios due to privacy, security, or regulatory constraints. Zero-shot Quantization (ZSQ) emerges as a promising solution, achieving quantization without requiring any real data. In this paper, we provide a comprehensive overview of ZSQ methods and their recent advancements. First, we provide a formal definition of the ZSQ problem and highlight the key challenges. Then, we categorize the existing ZSQ methods into classes based on data generation strategies, and analyze their motivations, core ideas, and key takeaways. Lastly, we suggest future research directions to address the remaining limitations and advance the field of ZSQ. To the best of our knowledge, this paper is the first in-depth survey on ZSQ.
AugWard: Augmentation-Aware Representation Learning for Accurate Graph Classification
Mar 27, 2025How can we accurately classify graphs? Graph classification is a pivotal task in data mining with applications in social network analysis, web analysis, drug discovery, molecular property prediction, etc. Graph neural networks have achieved the state-of-the-art performance in graph classification, but they consistently struggle with overfitting. To mitigate overfitting, researchers have introduced various representation learning methods utilizing graph augmentation. However, existing methods rely on simplistic use of graph augmentation, which loses augmentation-induced differences and limits the expressiveness of representations. In this paper, we propose AugWard (Augmentation-Aware Training with Graph Distance and Consistency Regularization), a novel graph representation learning framework that carefully considers the diversity introduced by graph augmentation. AugWard applies augmentation-aware training to predict the graph distance between the augmented graph and its original one, aligning the representation difference directly with graph distance at both feature and structure levels. Furthermore, AugWard employs consistency regularization to encourage the classifier to handle richer representations. Experimental results show that AugWard gives the state-of-the-art performance in supervised, semi-supervised graph classification, and transfer learning.
PULL: PU-Learning-based Accurate Link Prediction
May 20, 2024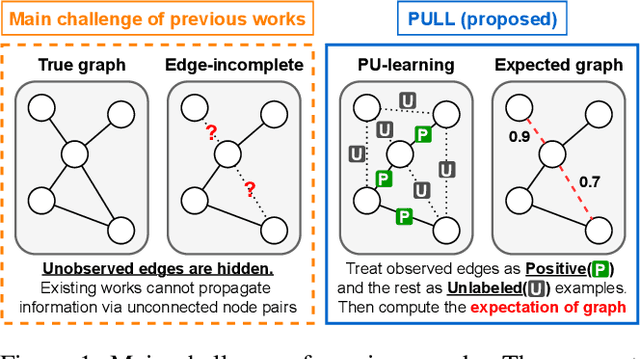
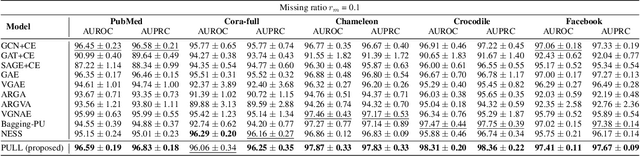
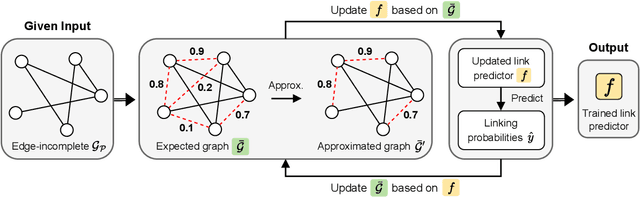

Given an edge-incomplete graph, how can we accurately find the missing links? The link prediction in edge-incomplete graphs aims to discover the missing relations between entities when their relationships are represented as a graph. Edge-incomplete graphs are prevalent in real-world due to practical limitations, such as not checking all users when adding friends in a social network. Addressing the problem is crucial for various tasks, including recommending friends in social networks and finding references in citation networks. However, previous approaches rely heavily on the given edge-incomplete (observed) graph, making it challenging to consider the missing (unobserved) links during training. In this paper, we propose PULL (PU-Learning-based Link predictor), an accurate link prediction method based on the positive-unlabeled (PU) learning. PULL treats the observed edges in the training graph as positive examples, and the unconnected node pairs as unlabeled ones. PULL effectively prevents the link predictor from overfitting to the observed graph by proposing latent variables for every edge, and leveraging the expected graph structure with respect to the variables. Extensive experiments on five real-world datasets show that PULL consistently outperforms the baselines for predicting links in edge-incomplete graphs.
A Comprehensive Survey of Compression Algorithms for Language Models
Jan 27, 2024How can we compress language models without sacrificing accuracy? The number of compression algorithms for language models is rapidly growing to benefit from remarkable advances of recent language models without side effects due to the gigantic size of language models, such as increased carbon emissions and expensive maintenance fees. While numerous compression algorithms have shown remarkable progress in compressing language models, it ironically becomes challenging to capture emerging trends and identify the fundamental concepts underlying them due to the excessive number of algorithms. In this paper, we survey and summarize diverse compression algorithms including pruning, quantization, knowledge distillation, low-rank approximation, parameter sharing, and efficient architecture design. We not only summarize the overall trend of diverse compression algorithms but also select representative algorithms and provide in-depth analyses of them. We discuss the value of each category of compression algorithms, and the desired properties of low-cost compression algorithms which have a significant impact due to the emergence of large language models. Finally, we introduce promising future research topics based on our survey results.
Accurate Cold-start Bundle Recommendation via Popularity-based Coalescence and Curriculum Heating
Oct 09, 2023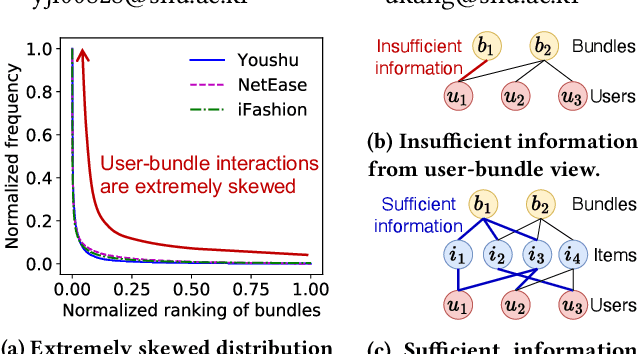



How can we accurately recommend cold-start bundles to users? The cold-start problem in bundle recommendation is critical in practical scenarios since new bundles are continuously created for various marketing purposes. Despite its importance, no previous studies have addressed cold-start bundle recommendation. Moreover, existing methods for cold-start item recommendation overly rely on historical information, even for unpopular bundles, failing to tackle the primary challenge of the highly skewed distribution of bundle interactions. In this work, we propose CoHeat (Popularity-based Coalescence and Curriculum Heating), an accurate approach for the cold-start bundle recommendation. CoHeat tackles the highly skewed distribution of bundle interactions by incorporating both historical and affiliation information based on the bundle's popularity when estimating the user-bundle relationship. Furthermore, CoHeat effectively learns latent representations by exploiting curriculum learning and contrastive learning. CoHeat demonstrates superior performance in cold-start bundle recommendation, achieving up to 193% higher nDCG@20 compared to the best competitor.
Fast and Accurate Transferability Measurement by Evaluating Intra-class Feature Variance
Aug 11, 2023Given a set of pre-trained models, how can we quickly and accurately find the most useful pre-trained model for a downstream task? Transferability measurement is to quantify how transferable is a pre-trained model learned on a source task to a target task. It is used for quickly ranking pre-trained models for a given task and thus becomes a crucial step for transfer learning. Existing methods measure transferability as the discrimination ability of a source model for a target data before transfer learning, which cannot accurately estimate the fine-tuning performance. Some of them restrict the application of transferability measurement in selecting the best supervised pre-trained models that have classifiers. It is important to have a general method for measuring transferability that can be applied in a variety of situations, such as selecting the best self-supervised pre-trained models that do not have classifiers, and selecting the best transferring layer for a target task. In this work, we propose TMI (TRANSFERABILITY MEASUREMENT WITH INTRA-CLASS FEATURE VARIANCE), a fast and accurate algorithm to measure transferability. We view transferability as the generalization of a pre-trained model on a target task by measuring intra-class feature variance. Intra-class variance evaluates the adaptability of the model to a new task, which measures how transferable the model is. Compared to previous studies that estimate how discriminative the models are, intra-class variance is more accurate than those as it does not require an optimal feature extractor and classifier. Extensive experiments on real-world datasets show that TMI outperforms competitors for selecting the top-5 best models, and exhibits consistently better correlation in 13 out of 17 cases.
Knowledge-preserving Pruning for Pre-trained Language Models without Retraining
Aug 07, 2023



Given a pre-trained language model, how can we efficiently compress it without retraining? Retraining-free structured pruning algorithms are crucial in pre-trained language model compression due to their significantly reduced pruning cost and capability to prune large language models. However, existing retraining-free algorithms encounter severe accuracy degradation, as they fail to preserve the useful knowledge of pre-trained models. In this paper, we propose K-pruning (Knowledge-preserving pruning), an accurate retraining-free structured pruning algorithm for pre-trained language models. K-pruning identifies and prunes attention heads and neurons deemed to be superfluous, based on the amount of their inherent knowledge. K-pruning applies an iterative process of pruning followed by knowledge reconstruction for each sub-layer to preserve the knowledge of the pre-trained models. Consequently, K-pruning shows up to 58.02%p higher F1 score than existing retraining-free pruning algorithms under a high compression rate of 80% on the SQuAD benchmark.
Fast and Accurate Dual-Way Streaming PARAFAC2 for Irregular Tensors -- Algorithm and Application
May 28, 2023How can we efficiently and accurately analyze an irregular tensor in a dual-way streaming setting where the sizes of two dimensions of the tensor increase over time? What types of anomalies are there in the dual-way streaming setting? An irregular tensor is a collection of matrices whose column lengths are the same while their row lengths are different. In a dual-way streaming setting, both new rows of existing matrices and new matrices arrive over time. PARAFAC2 decomposition is a crucial tool for analyzing irregular tensors. Although real-time analysis is necessary in the dual-way streaming, static PARAFAC2 decomposition methods fail to efficiently work in this setting since they perform PARAFAC2 decomposition for accumulated tensors whenever new data arrive. Existing streaming PARAFAC2 decomposition methods work in a limited setting and fail to handle new rows of matrices efficiently. In this paper, we propose Dash, an efficient and accurate PARAFAC2 decomposition method working in the dual-way streaming setting. When new data are given, Dash efficiently performs PARAFAC2 decomposition by carefully dividing the terms related to old and new data and avoiding naive computations involved with old data. Furthermore, applying a forgetting factor makes Dash follow recent movements. Extensive experiments show that Dash achieves up to 14.0x faster speed than existing PARAFAC2 decomposition methods for newly arrived data. We also provide discoveries for detecting anomalies in real-world datasets, including Subprime Mortgage Crisis and COVID-19.