 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLampQ: Towards Accurate Layer-wise Mixed Precision Quantization for Vision Transformers
Nov 14, 2025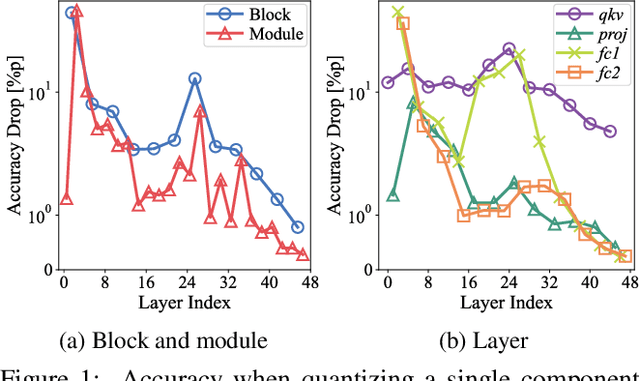

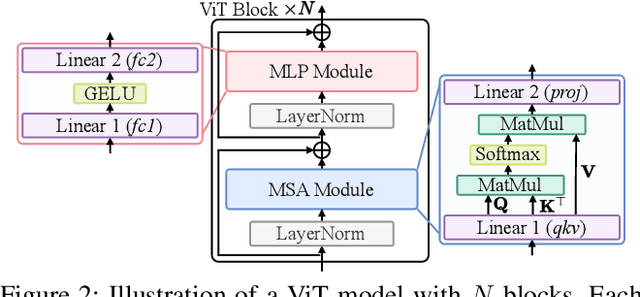

How can we accurately quantize a pre-trained Vision Transformer model? Quantization algorithms compress Vision Transformers (ViTs) into low-bit formats, reducing memory and computation demands with minimal accuracy degradation. However, existing methods rely on uniform precision, ignoring the diverse sensitivity of ViT components to quantization. Metric-based Mixed Precision Quantization (MPQ) is a promising alternative, but previous MPQ methods for ViTs suffer from three major limitations: 1) coarse granularity, 2) mismatch in metric scale across component types, and 3) quantization-unaware bit allocation. In this paper, we propose LampQ (Layer-wise Mixed Precision Quantization for Vision Transformers), an accurate metric-based MPQ method for ViTs to overcome these limitations. LampQ performs layer-wise quantization to achieve both fine-grained control and efficient acceleration, incorporating a type-aware Fisher-based metric to measure sensitivity. Then, LampQ assigns bit-widths optimally through integer linear programming and further updates them iteratively. Extensive experiments show that LampQ provides the state-of-the-art performance in quantizing ViTs pre-trained on various tasks such as image classification, object detection, and zero-shot quantization.
Accurate Cold-start Bundle Recommendation via Popularity-based Coalescence and Curriculum Heating
Oct 09, 2023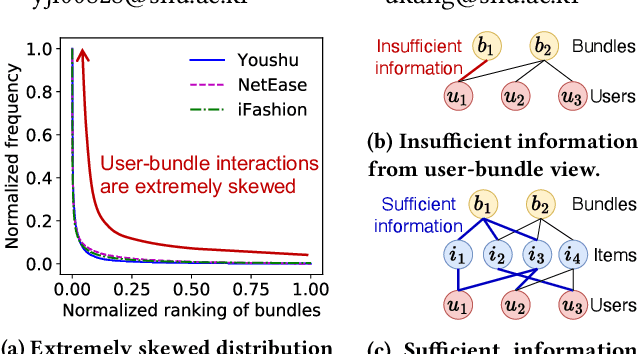



How can we accurately recommend cold-start bundles to users? The cold-start problem in bundle recommendation is critical in practical scenarios since new bundles are continuously created for various marketing purposes. Despite its importance, no previous studies have addressed cold-start bundle recommendation. Moreover, existing methods for cold-start item recommendation overly rely on historical information, even for unpopular bundles, failing to tackle the primary challenge of the highly skewed distribution of bundle interactions. In this work, we propose CoHeat (Popularity-based Coalescence and Curriculum Heating), an accurate approach for the cold-start bundle recommendation. CoHeat tackles the highly skewed distribution of bundle interactions by incorporating both historical and affiliation information based on the bundle's popularity when estimating the user-bundle relationship. Furthermore, CoHeat effectively learns latent representations by exploiting curriculum learning and contrastive learning. CoHeat demonstrates superior performance in cold-start bundle recommendation, achieving up to 193% higher nDCG@20 compared to the best competitor.
Modulating Regularization Frequency for Efficient Compression-Aware Model Training
May 05, 2021
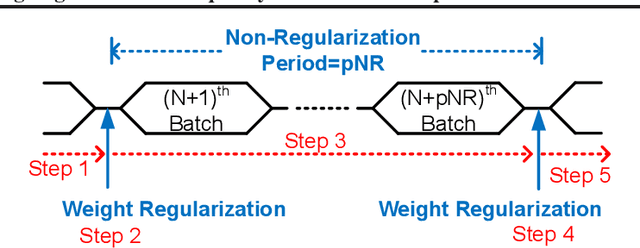

While model compression is increasingly important because of large neural network size, compression-aware training is challenging as it needs sophisticated model modifications and longer training time.In this paper, we introduce regularization frequency (i.e., how often compression is performed during training) as a new regularization technique for a practical and efficient compression-aware training method. For various regularization techniques, such as weight decay and dropout, optimizing the regularization strength is crucial to improve generalization in Deep Neural Networks (DNNs). While model compression also demands the right amount of regularization, the regularization strength incurred by model compression has been controlled only by compression ratio. Throughout various experiments, we show that regularization frequency critically affects the regularization strength of model compression. Combining regularization frequency and compression ratio, the amount of weight updates by model compression per mini-batch can be optimized to achieve the best model accuracy. Modulating regularization frequency is implemented by occasional model compression while conventional compression-aware training is usually performed for every mini-batch.
FleXOR: Trainable Fractional Quantization
Sep 09, 2020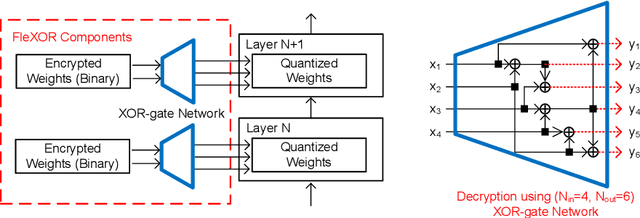
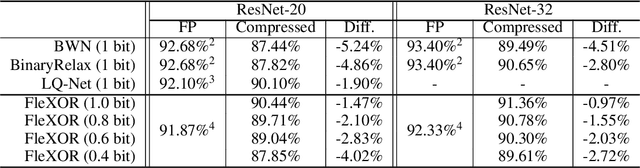
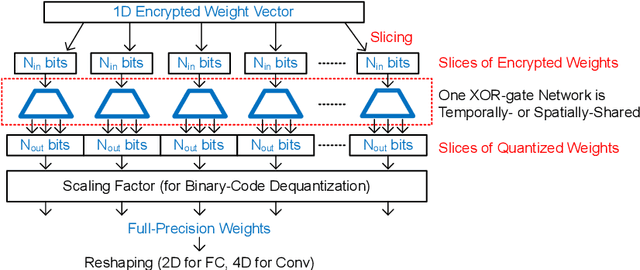
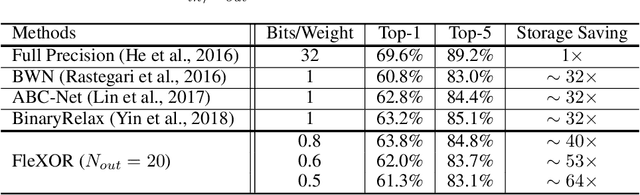
Quantization based on the binary codes is gaining attention because each quantized bit can be directly utilized for computations without dequantization using look-up tables. Previous attempts, however, only allow for integer numbers of quantization bits, which ends up restricting the search space for compression ratio and accuracy. In this paper, we propose an encryption algorithm/architecture to compress quantized weights so as to achieve fractional numbers of bits per weight.Decryption during inference is implemented by digital XOR-gate networks added into the neural network model while XOR gates are described by utilizing tanh(x) for backward propagation to enable gradient calculations. We perform experiments using MNIST, CIFAR-10, and ImageNet to show that inserting XOR gates learns quantization/encrypted bit decisions through training and obtains high accuracy even for fractional sub 1-bit weights. As a result, our proposed method yields smaller size and higher model accuracy compared to binary neural networks.
BiQGEMM: Matrix Multiplication with Lookup Table For Binary-Coding-based Quantized DNNs
May 20, 2020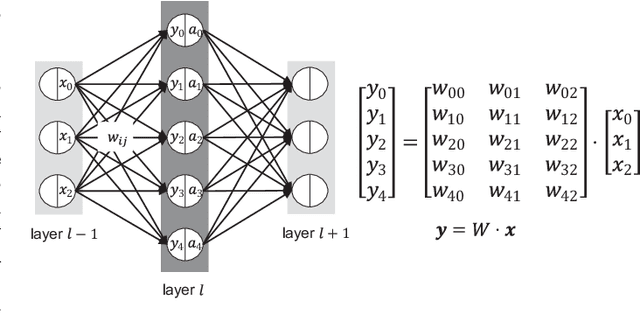
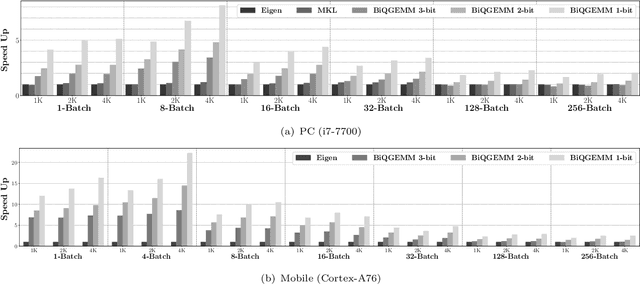
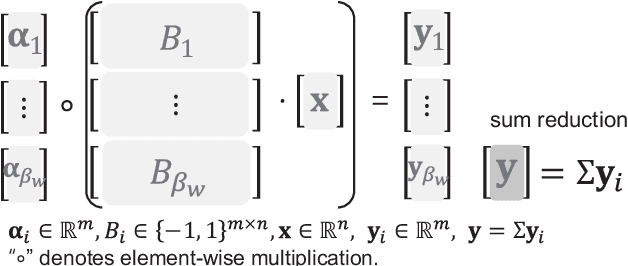
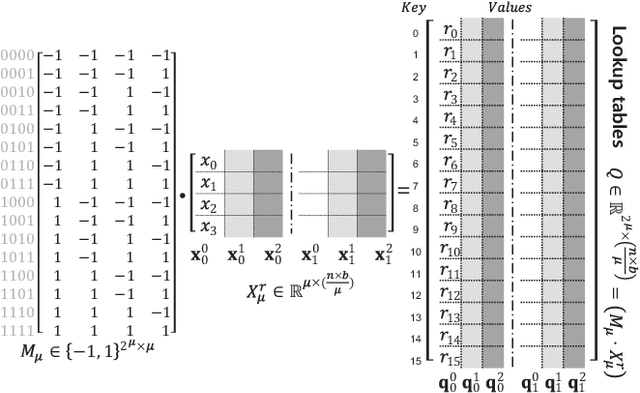
The number of parameters in deep neural networks (DNNs) is rapidly increasing to support complicated tasks and to improve model accuracy. Correspondingly, the amount of computations and required memory footprint increase as well. Quantization is an efficient method to address such concerns by compressing DNNs such that computations can be simplified while required storage footprint is significantly reduced. Unfortunately, commercial CPUs and GPUs do not fully support quantization because only fixed data transfers (such as 32 bits) are allowed. As a result, even if weights are quantized into a few bits, CPUs and GPUs cannot access multiple quantized weights without memory bandwidth waste. Success of quantization in practice, hence, relies on an efficient computation engine design, especially for matrix multiplication that is a basic computation engine in most DNNs. In this paper, we propose a novel matrix multiplication method, called BiQGEMM, dedicated to quantized DNNs. BiQGEMM can access multiple quantized weights simultaneously in one instruction. In addition, BiQGEMM pre-computes intermediate results that are highly redundant when quantization leads to limited available computation space. Since pre-computed values are stored in lookup tables and reused, BiQGEMM achieves lower amount of overall computations. Our extensive experimental results show that BiQGEMM presents higher performance than conventional schemes when DNNs are quantized.