 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFleXOR: Trainable Fractional Quantization
Paper and Code
Sep 09, 2020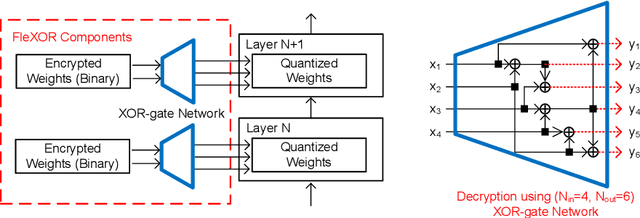
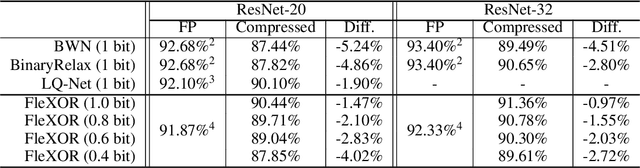
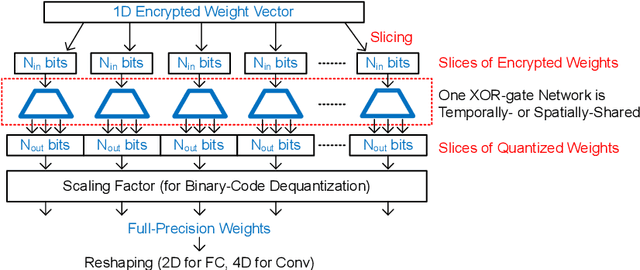
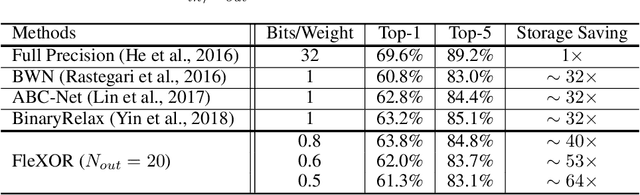
Quantization based on the binary codes is gaining attention because each quantized bit can be directly utilized for computations without dequantization using look-up tables. Previous attempts, however, only allow for integer numbers of quantization bits, which ends up restricting the search space for compression ratio and accuracy. In this paper, we propose an encryption algorithm/architecture to compress quantized weights so as to achieve fractional numbers of bits per weight.Decryption during inference is implemented by digital XOR-gate networks added into the neural network model while XOR gates are described by utilizing tanh(x) for backward propagation to enable gradient calculations. We perform experiments using MNIST, CIFAR-10, and ImageNet to show that inserting XOR gates learns quantization/encrypted bit decisions through training and obtains high accuracy even for fractional sub 1-bit weights. As a result, our proposed method yields smaller size and higher model accuracy compared to binary neural networks.