 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiQGEMM: Matrix Multiplication with Lookup Table For Binary-Coding-based Quantized DNNs
Paper and Code
May 20, 2020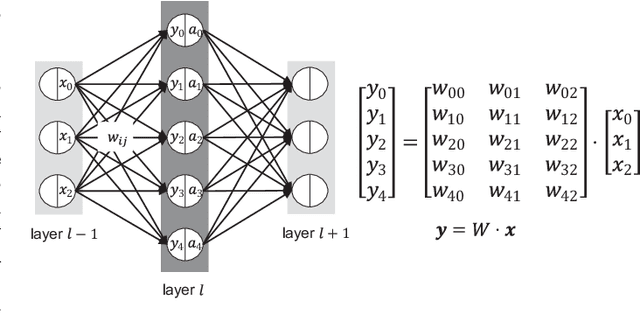
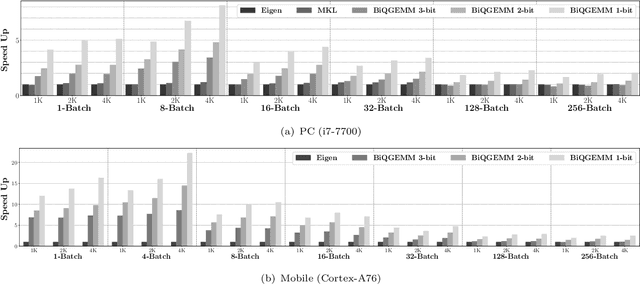
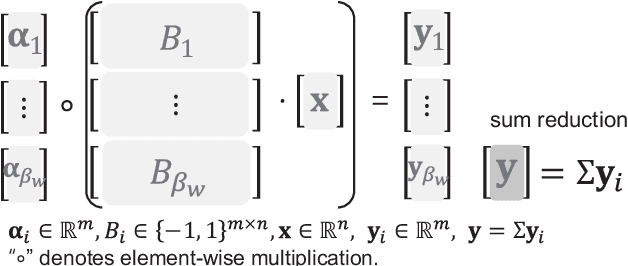
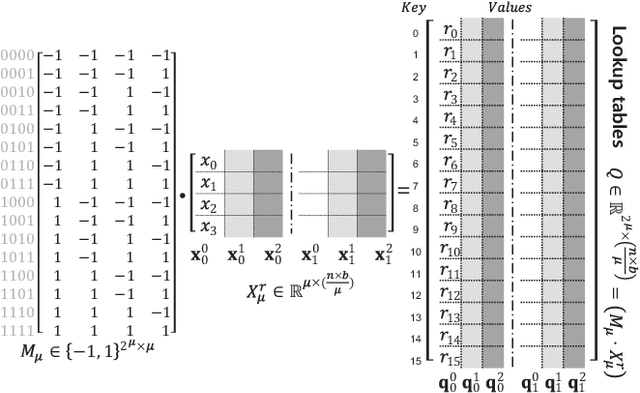
The number of parameters in deep neural networks (DNNs) is rapidly increasing to support complicated tasks and to improve model accuracy. Correspondingly, the amount of computations and required memory footprint increase as well. Quantization is an efficient method to address such concerns by compressing DNNs such that computations can be simplified while required storage footprint is significantly reduced. Unfortunately, commercial CPUs and GPUs do not fully support quantization because only fixed data transfers (such as 32 bits) are allowed. As a result, even if weights are quantized into a few bits, CPUs and GPUs cannot access multiple quantized weights without memory bandwidth waste. Success of quantization in practice, hence, relies on an efficient computation engine design, especially for matrix multiplication that is a basic computation engine in most DNNs. In this paper, we propose a novel matrix multiplication method, called BiQGEMM, dedicated to quantized DNNs. BiQGEMM can access multiple quantized weights simultaneously in one instruction. In addition, BiQGEMM pre-computes intermediate results that are highly redundant when quantization leads to limited available computation space. Since pre-computed values are stored in lookup tables and reused, BiQGEMM achieves lower amount of overall computations. Our extensive experimental results show that BiQGEMM presents higher performance than conventional schemes when DNNs are quantized.