 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebSpline: Structure-Informed Splines for Real-Time 3D Gaussians from Monocular Videos
Jun 01, 2026Dynamic scene reconstruction from monocular videos remains highly challenging, as existing methods often struggle to balance global structural coherence and local fine-grained details under limited multi-view cues. To address this challenge, we propose WebSpline, a novel dynamic 3D Gaussian framework that enables structurally coherent and high-fidelity reconstruction from monocular videos with fast rendering. The core of WebSpline is the Structure-Informed Spline (SIS) representation, which models each dynamic Gaussian trajectory using a learnable cubic Hermite spline whose motion is structurally organized with an auxiliary Structural Proxy Graph (SPG). The proposed framework is optimized in two stages: (i) in the first stage, the SPG is initialized from 2D point tracks and refined with temporal rigidity regularization to establish structural coherence for moving objects across the sequence; and (ii) in the second stage, the SIS representation is initialized from the refined SPG and optimized under both spatial and structural neighborhood constraints. At inference, Gaussian motion is obtained solely by evaluating the learned SIS, enabling fast rendering. Extensive experiments on the challenging monocular dynamic scene benchmarks, iPhone and NVIDIA, demonstrate that our WebSpline achieves state-of-the-art rendering quality while rendering over 10 times faster than WorldTree, the second-best method on the iPhone dataset.
AA-Splat: Anti-Aliased Feed-forward Gaussian Splatting
Mar 31, 2026Feed-forward 3D Gaussian Splatting (FF-3DGS) emerges as a fast and robust solution for sparse-view 3D reconstruction and novel view synthesis (NVS). However, existing FF-3DGS methods are built on incorrect screen-space dilation filters, causing severe rendering artifacts when rendering at out-of-distribution sampling rates. We firstly propose an FF-3DGS model, called AA-Splat, to enable robust anti-aliased rendering at any resolution. AA-Splat utilizes an opacity-balanced band-limiting (OBBL) design, which combines two components: a 3D band-limiting post-filter integrates multi-view maximal frequency bounds into the feed-forward reconstruction pipeline, effectively band-limiting the resulting 3D scene representations and eliminating degenerate Gaussians; an Opacity Balancing (OB) to seamlessly integrate all pixel-aligned Gaussian primitives into the rendering process, compensating for the increased overlap between expanded Gaussian primitives. AA-Splat demonstrates drastic improvements with average 5.4$\sim$7.5dB PSNR gains on NVS performance over a state-of-the-art (SOTA) baseline, DepthSplat, at all resolutions, between $4\times$ and $1/4\times$. Code will be made available.
Hyperbolic Heterogeneous Graph Transformer
Jan 13, 2026In heterogeneous graphs, we can observe complex structures such as tree-like or hierarchical structures. Recently, the hyperbolic space has been widely adopted in many studies to effectively learn these complex structures. Although these methods have demonstrated the advantages of the hyperbolic space in learning heterogeneous graphs, most existing methods still have several challenges. They rely heavily on tangent-space operations, which often lead to mapping distortions during frequent transitions. Moreover, their message-passing architectures mainly focus on local neighborhood information, making it difficult to capture global hierarchical structures and long-range dependencies between different types of nodes. To address these limitations, we propose Hyperbolic Heterogeneous Graph Transformer (HypHGT), which effectively and efficiently learns heterogeneous graph representations entirely within the hyperbolic space. Unlike previous message-passing based hyperbolic heterogeneous GNNs, HypHGT naturally captures both local and global dependencies through transformer-based architecture. Furthermore, the proposed relation-specific hyperbolic attention mechanism in HypHGT, which operates with linear time complexity, enables efficient computation while preserving the heterogeneous information across different relation types. This design allows HypHGT to effectively capture the complex structural properties and semantic information inherent in heterogeneous graphs. We conduct comprehensive experiments to evaluate the effectiveness and efficiency of HypHGT, and the results demonstrate that it consistently outperforms state-of-the-art methods in node classification task, with significantly reduced training time and memory usage.
EcoSplat: Efficiency-controllable Feed-forward 3D Gaussian Splatting from Multi-view Images
Dec 21, 2025Feed-forward 3D Gaussian Splatting (3DGS) enables efficient one-pass scene reconstruction, providing 3D representations for novel view synthesis without per-scene optimization. However, existing methods typically predict pixel-aligned primitives per-view, producing an excessive number of primitives in dense-view settings and offering no explicit control over the number of predicted Gaussians. To address this, we propose EcoSplat, the first efficiency-controllable feed-forward 3DGS framework that adaptively predicts the 3D representation for any given target primitive count at inference time. EcoSplat adopts a two-stage optimization process. The first stage is Pixel-aligned Gaussian Training (PGT) where our model learns initial primitive prediction. The second stage is Importance-aware Gaussian Finetuning (IGF) stage where our model learns rank primitives and adaptively adjust their parameters based on the target primitive count. Extensive experiments across multiple dense-view settings show that EcoSplat is robust and outperforms state-of-the-art methods under strict primitive-count constraints, making it well-suited for flexible downstream rendering tasks.
Toward High Accuracy DME for Alternative Aircraft Positioning: SFOL Pulse Transmission in High-Power DME
Jun 07, 2025The Stretched-FrOnt-Leg (SFOL) pulse is an advanced distance measuring equipment (DME) pulse that offers superior ranging accuracy compared to conventional Gaussian pulses. Successful SFOL pulse transmission has been recently demonstrated from a commercial Gaussian pulse-based DME in low-power mode utilizing digital predistortion (DPD) techniques for power amplifiers. These adjustments were achieved through software modifications, enabling SFOL integration without replacing existing DME infrastructure. However, the SFOL pulse is designed to optimize ranging capabilities by leveraging the effective radiated power (ERP) and pulse shape parameters permitted within DME specifications. Consequently, it operates with narrow margins against these specifications, potentially leading to non-compliance when transmitted in high-power mode. This paper introduces strategies to enable a Gaussian pulse-based DME to transmit the SFOL pulse while adhering to DME specifications in high-power mode. The proposed strategies involve use of a variant of the SFOL pulse and DPD techniques utilizing truncated singular value decomposition, tailored for high-power DME operations. Test results, conducted on a testbed utilizing a commercial Gaussian pulse-based DME, demonstrate the effectiveness of these strategies, ensuring compliance with DME specifications in high-power mode with minimal performance loss. This study enables cost-effective integration of high-accuracy SFOL pulses into existing high-power DME systems, enhancing aircraft positioning precision while ensuring compliance with industry standards.
MoBGS: Motion Deblurring Dynamic 3D Gaussian Splatting for Blurry Monocular Video
Apr 21, 2025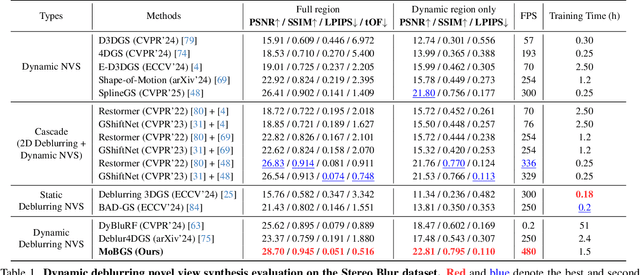

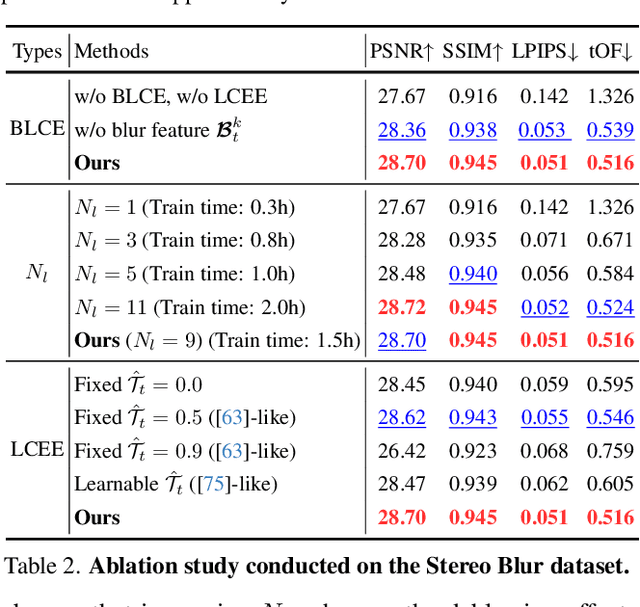

We present MoBGS, a novel deblurring dynamic 3D Gaussian Splatting (3DGS) framework capable of reconstructing sharp and high-quality novel spatio-temporal views from blurry monocular videos in an end-to-end manner. Existing dynamic novel view synthesis (NVS) methods are highly sensitive to motion blur in casually captured videos, resulting in significant degradation of rendering quality. While recent approaches address motion-blurred inputs for NVS, they primarily focus on static scene reconstruction and lack dedicated motion modeling for dynamic objects. To overcome these limitations, our MoBGS introduces a novel Blur-adaptive Latent Camera Estimation (BLCE) method for effective latent camera trajectory estimation, improving global camera motion deblurring. In addition, we propose a physically-inspired Latent Camera-induced Exposure Estimation (LCEE) method to ensure consistent deblurring of both global camera and local object motion. Our MoBGS framework ensures the temporal consistency of unseen latent timestamps and robust motion decomposition of static and dynamic regions. Extensive experiments on the Stereo Blur dataset and real-world blurry videos show that our MoBGS significantly outperforms the very recent advanced methods (DyBluRF and Deblur4DGS), achieving state-of-the-art performance for dynamic NVS under motion blur.
SplineGS: Robust Motion-Adaptive Spline for Real-Time Dynamic 3D Gaussians from Monocular Video
Dec 13, 2024



Synthesizing novel views from in-the-wild monocular videos is challenging due to scene dynamics and the lack of multi-view cues. To address this, we propose SplineGS, a COLMAP-free dynamic 3D Gaussian Splatting (3DGS) framework for high-quality reconstruction and fast rendering from monocular videos. At its core is a novel Motion-Adaptive Spline (MAS) method, which represents continuous dynamic 3D Gaussian trajectories using cubic Hermite splines with a small number of control points. For MAS, we introduce a Motion-Adaptive Control points Pruning (MACP) method to model the deformation of each dynamic 3D Gaussian across varying motions, progressively pruning control points while maintaining dynamic modeling integrity. Additionally, we present a joint optimization strategy for camera parameter estimation and 3D Gaussian attributes, leveraging photometric and geometric consistency. This eliminates the need for Structure-from-Motion preprocessing and enhances SplineGS's robustness in real-world conditions. Experiments show that SplineGS significantly outperforms state-of-the-art methods in novel view synthesis quality for dynamic scenes from monocular videos, achieving thousands times faster rendering speed.
Multi-Hyperbolic Space-based Heterogeneous Graph Attention Network
Nov 18, 2024


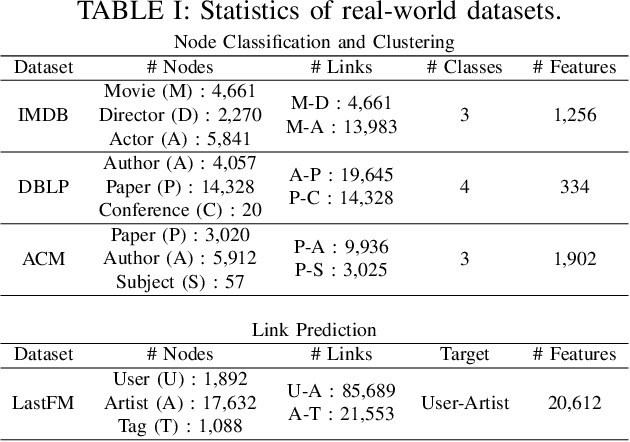
To leverage the complex structures within heterogeneous graphs, recent studies on heterogeneous graph embedding use a hyperbolic space, characterized by a constant negative curvature and exponentially increasing space, which aligns with the structural properties of heterogeneous graphs. However, despite heterogeneous graphs inherently possessing diverse power-law structures, most hyperbolic heterogeneous graph embedding models use a single hyperbolic space for the entire heterogeneous graph, which may not effectively capture the diverse power-law structures within the heterogeneous graph. To address this limitation, we propose Multi-hyperbolic Space-based heterogeneous Graph Attention Network (MSGAT), which uses multiple hyperbolic spaces to effectively capture diverse power-law structures within heterogeneous graphs. We conduct comprehensive experiments to evaluate the effectiveness of MSGAT. The experimental results demonstrate that MSGAT outperforms state-of-the-art baselines in various graph machine learning tasks, effectively capturing the complex structures of heterogeneous graphs.
Hyperbolic Heterogeneous Graph Attention Networks
Apr 15, 2024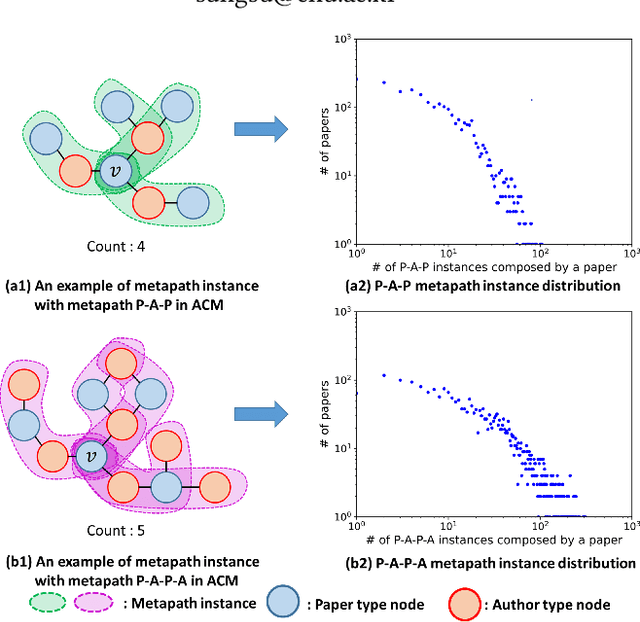
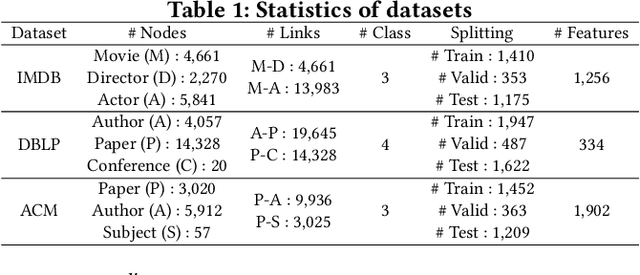
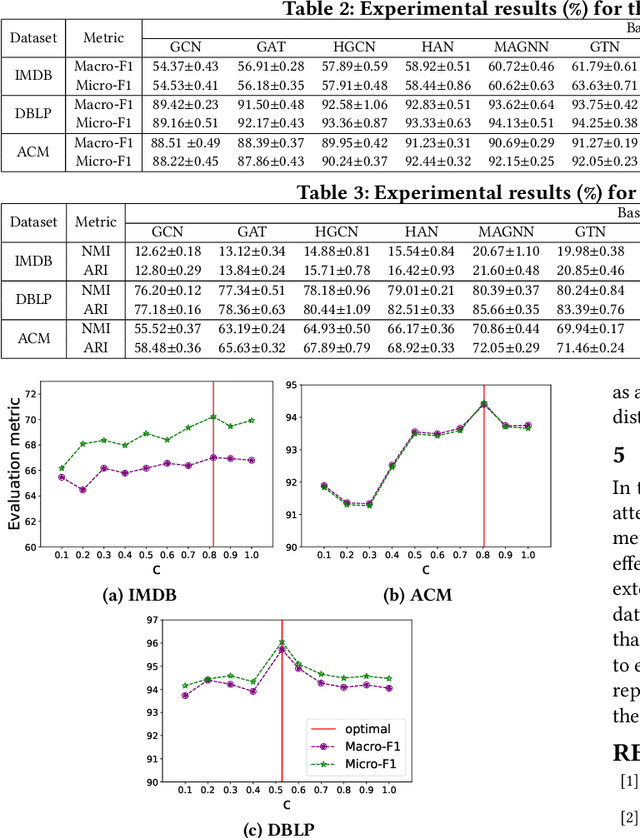
Most previous heterogeneous graph embedding models represent elements in a heterogeneous graph as vector representations in a low-dimensional Euclidean space. However, because heterogeneous graphs inherently possess complex structures, such as hierarchical or power-law structures, distortions can occur when representing them in Euclidean space. To overcome this limitation, we propose Hyperbolic Heterogeneous Graph Attention Networks (HHGAT) that learn vector representations in hyperbolic spaces with meta-path instances. We conducted experiments on three real-world heterogeneous graph datasets, demonstrating that HHGAT outperforms state-of-the-art heterogeneous graph embedding models in node classification and clustering tasks.
DyBluRF: Dynamic Deblurring Neural Radiance Fields for Blurry Monocular Video
Dec 21, 2023
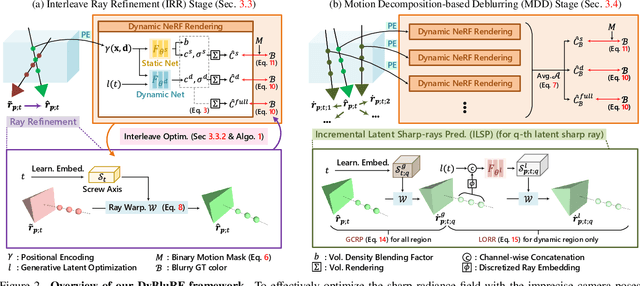
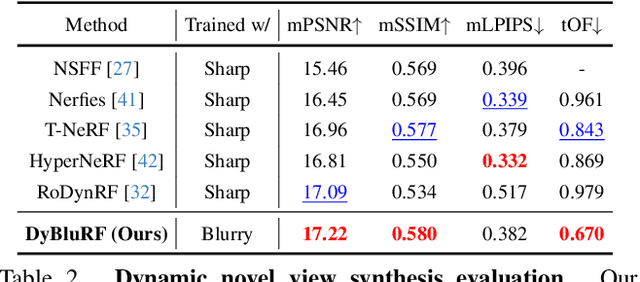
Video view synthesis, allowing for the creation of visually appealing frames from arbitrary viewpoints and times, offers immersive viewing experiences. Neural radiance fields, particularly NeRF, initially developed for static scenes, have spurred the creation of various methods for video view synthesis. However, the challenge for video view synthesis arises from motion blur, a consequence of object or camera movement during exposure, which hinders the precise synthesis of sharp spatio-temporal views. In response, we propose a novel dynamic deblurring NeRF framework for blurry monocular video, called DyBluRF, consisting of an Interleave Ray Refinement (IRR) stage and a Motion Decomposition-based Deblurring (MDD) stage. Our DyBluRF is the first that addresses and handles the novel view synthesis for blurry monocular video. The IRR stage jointly reconstructs dynamic 3D scenes and refines the inaccurate camera pose information to combat imprecise pose information extracted from the given blurry frames. The MDD stage is a novel incremental latent sharp-rays prediction (ILSP) approach for the blurry monocular video frames by decomposing the latent sharp rays into global camera motion and local object motion components. Extensive experimental results demonstrate that our DyBluRF outperforms qualitatively and quantitatively the very recent state-of-the-art methods. Our project page including source codes and pretrained model are publicly available at https://kaist-viclab.github.io/dyblurf-site/.