 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebSpline: Structure-Informed Splines for Real-Time 3D Gaussians from Monocular Videos
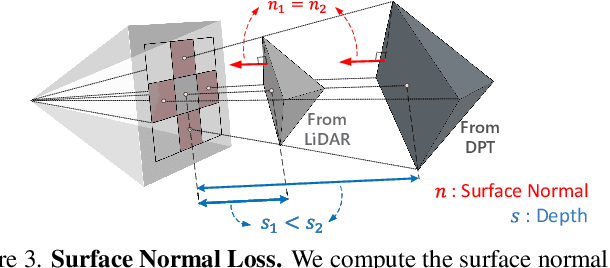
Jun 01, 2026Dynamic scene reconstruction from monocular videos remains highly challenging, as existing methods often struggle to balance global structural coherence and local fine-grained details under limited multi-view cues. To address this challenge, we propose WebSpline, a novel dynamic 3D Gaussian framework that enables structurally coherent and high-fidelity reconstruction from monocular videos with fast rendering. The core of WebSpline is the Structure-Informed Spline (SIS) representation, which models each dynamic Gaussian trajectory using a learnable cubic Hermite spline whose motion is structurally organized with an auxiliary Structural Proxy Graph (SPG). The proposed framework is optimized in two stages: (i) in the first stage, the SPG is initialized from 2D point tracks and refined with temporal rigidity regularization to establish structural coherence for moving objects across the sequence; and (ii) in the second stage, the SIS representation is initialized from the refined SPG and optimized under both spatial and structural neighborhood constraints. At inference, Gaussian motion is obtained solely by evaluating the learned SIS, enabling fast rendering. Extensive experiments on the challenging monocular dynamic scene benchmarks, iPhone and NVIDIA, demonstrate that our WebSpline achieves state-of-the-art rendering quality while rendering over 10 times faster than WorldTree, the second-best method on the iPhone dataset.
AirSplat: Alignment and Rating for Robust Feed-Forward 3D Gaussian Splatting
Mar 26, 2026While 3D Vision Foundation Models (3DVFMs) have demonstrated remarkable zero-shot capabilities in visual geometry estimation, their direct application to generalizable novel view synthesis (NVS) remains challenging. In this paper, we propose AirSplat, a novel training framework that effectively adapts the robust geometric priors of 3DVFMs into high-fidelity, pose-free NVS. Our approach introduces two key technical contributions: (1) Self-Consistent Pose Alignment (SCPA), a training-time feedback loop that ensures pixel-aligned supervision to resolve pose-geometry discrepancy; and (2) Rating-based Opacity Matching (ROM), which leverages the local 3D geometry consistency knowledge from a sparse-view NVS teacher model to filter out degraded primitives. Experimental results on large-scale benchmarks demonstrate that our method significantly outperforms state-of-the-art pose-free NVS approaches in reconstruction quality. Our AirSplat highlights the potential of adapting 3DVFMs to enable simultaneous visual geometry estimation and high-quality view synthesis.
EcoSplat: Efficiency-controllable Feed-forward 3D Gaussian Splatting from Multi-view Images
Dec 21, 2025Feed-forward 3D Gaussian Splatting (3DGS) enables efficient one-pass scene reconstruction, providing 3D representations for novel view synthesis without per-scene optimization. However, existing methods typically predict pixel-aligned primitives per-view, producing an excessive number of primitives in dense-view settings and offering no explicit control over the number of predicted Gaussians. To address this, we propose EcoSplat, the first efficiency-controllable feed-forward 3DGS framework that adaptively predicts the 3D representation for any given target primitive count at inference time. EcoSplat adopts a two-stage optimization process. The first stage is Pixel-aligned Gaussian Training (PGT) where our model learns initial primitive prediction. The second stage is Importance-aware Gaussian Finetuning (IGF) stage where our model learns rank primitives and adaptively adjust their parameters based on the target primitive count. Extensive experiments across multiple dense-view settings show that EcoSplat is robust and outperforms state-of-the-art methods under strict primitive-count constraints, making it well-suited for flexible downstream rendering tasks.
MoBGS: Motion Deblurring Dynamic 3D Gaussian Splatting for Blurry Monocular Video
Apr 21, 2025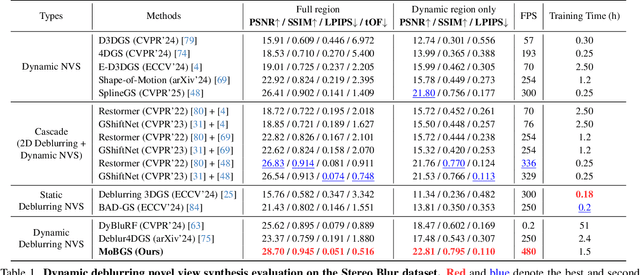

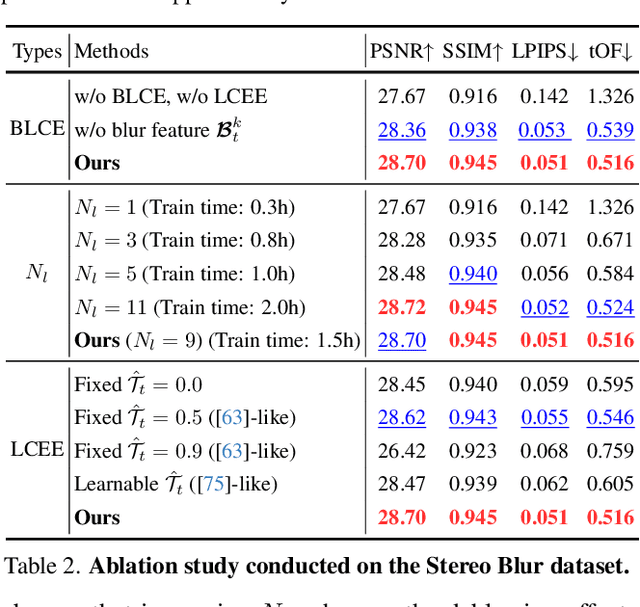

We present MoBGS, a novel deblurring dynamic 3D Gaussian Splatting (3DGS) framework capable of reconstructing sharp and high-quality novel spatio-temporal views from blurry monocular videos in an end-to-end manner. Existing dynamic novel view synthesis (NVS) methods are highly sensitive to motion blur in casually captured videos, resulting in significant degradation of rendering quality. While recent approaches address motion-blurred inputs for NVS, they primarily focus on static scene reconstruction and lack dedicated motion modeling for dynamic objects. To overcome these limitations, our MoBGS introduces a novel Blur-adaptive Latent Camera Estimation (BLCE) method for effective latent camera trajectory estimation, improving global camera motion deblurring. In addition, we propose a physically-inspired Latent Camera-induced Exposure Estimation (LCEE) method to ensure consistent deblurring of both global camera and local object motion. Our MoBGS framework ensures the temporal consistency of unseen latent timestamps and robust motion decomposition of static and dynamic regions. Extensive experiments on the Stereo Blur dataset and real-world blurry videos show that our MoBGS significantly outperforms the very recent advanced methods (DyBluRF and Deblur4DGS), achieving state-of-the-art performance for dynamic NVS under motion blur.
SplineGS: Robust Motion-Adaptive Spline for Real-Time Dynamic 3D Gaussians from Monocular Video
Dec 13, 2024



Synthesizing novel views from in-the-wild monocular videos is challenging due to scene dynamics and the lack of multi-view cues. To address this, we propose SplineGS, a COLMAP-free dynamic 3D Gaussian Splatting (3DGS) framework for high-quality reconstruction and fast rendering from monocular videos. At its core is a novel Motion-Adaptive Spline (MAS) method, which represents continuous dynamic 3D Gaussian trajectories using cubic Hermite splines with a small number of control points. For MAS, we introduce a Motion-Adaptive Control points Pruning (MACP) method to model the deformation of each dynamic 3D Gaussian across varying motions, progressively pruning control points while maintaining dynamic modeling integrity. Additionally, we present a joint optimization strategy for camera parameter estimation and 3D Gaussian attributes, leveraging photometric and geometric consistency. This eliminates the need for Structure-from-Motion preprocessing and enhances SplineGS's robustness in real-world conditions. Experiments show that SplineGS significantly outperforms state-of-the-art methods in novel view synthesis quality for dynamic scenes from monocular videos, achieving thousands times faster rendering speed.
DyBluRF: Dynamic Deblurring Neural Radiance Fields for Blurry Monocular Video
Dec 21, 2023
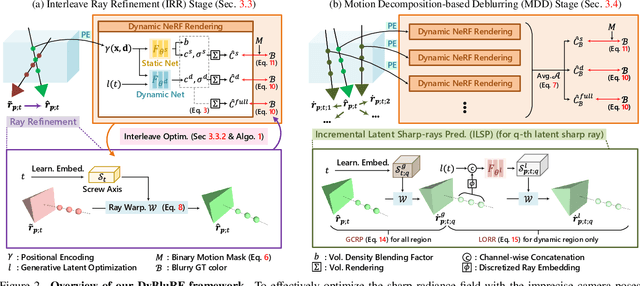
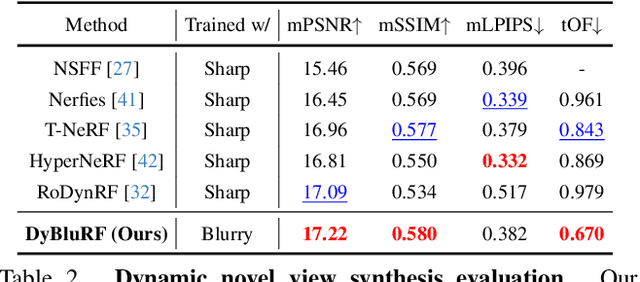
Video view synthesis, allowing for the creation of visually appealing frames from arbitrary viewpoints and times, offers immersive viewing experiences. Neural radiance fields, particularly NeRF, initially developed for static scenes, have spurred the creation of various methods for video view synthesis. However, the challenge for video view synthesis arises from motion blur, a consequence of object or camera movement during exposure, which hinders the precise synthesis of sharp spatio-temporal views. In response, we propose a novel dynamic deblurring NeRF framework for blurry monocular video, called DyBluRF, consisting of an Interleave Ray Refinement (IRR) stage and a Motion Decomposition-based Deblurring (MDD) stage. Our DyBluRF is the first that addresses and handles the novel view synthesis for blurry monocular video. The IRR stage jointly reconstructs dynamic 3D scenes and refines the inaccurate camera pose information to combat imprecise pose information extracted from the given blurry frames. The MDD stage is a novel incremental latent sharp-rays prediction (ILSP) approach for the blurry monocular video frames by decomposing the latent sharp rays into global camera motion and local object motion components. Extensive experimental results demonstrate that our DyBluRF outperforms qualitatively and quantitatively the very recent state-of-the-art methods. Our project page including source codes and pretrained model are publicly available at https://kaist-viclab.github.io/dyblurf-site/.
ProNeRF: Learning Efficient Projection-Aware Ray Sampling for Fine-Grained Implicit Neural Radiance Fields
Dec 13, 2023Recent advances in neural rendering have shown that, albeit slow, implicit compact models can learn a scene's geometries and view-dependent appearances from multiple views. To maintain such a small memory footprint but achieve faster inference times, recent works have adopted `sampler' networks that adaptively sample a small subset of points along each ray in the implicit neural radiance fields. Although these methods achieve up to a 10$\times$ reduction in rendering time, they still suffer from considerable quality degradation compared to the vanilla NeRF. In contrast, we propose ProNeRF, which provides an optimal trade-off between memory footprint (similar to NeRF), speed (faster than HyperReel), and quality (better than K-Planes). ProNeRF is equipped with a novel projection-aware sampling (PAS) network together with a new training strategy for ray exploration and exploitation, allowing for efficient fine-grained particle sampling. Our ProNeRF yields state-of-the-art metrics, being 15-23x faster with 0.65dB higher PSNR than NeRF and yielding 0.95dB higher PSNR than the best published sampler-based method, HyperReel. Our exploration and exploitation training strategy allows ProNeRF to learn the full scenes' color and density distributions while also learning efficient ray sampling focused on the highest-density regions. We provide extensive experimental results that support the effectiveness of our method on the widely adopted forward-facing and 360 datasets, LLFF and Blender, respectively.