 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndoor Path Planning for Multiple Unmanned Aerial Vehicles via Curriculum Learning
Paper and Code
Sep 05, 2022
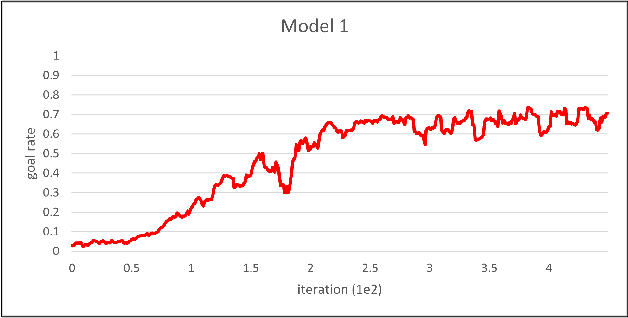
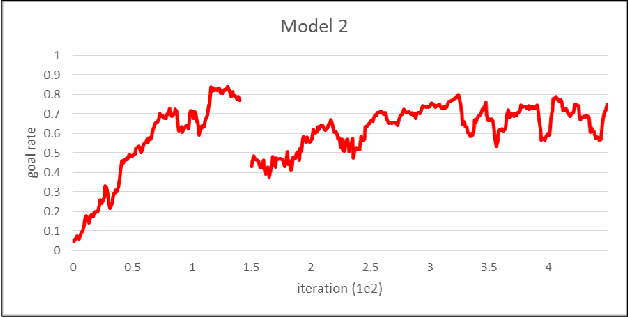
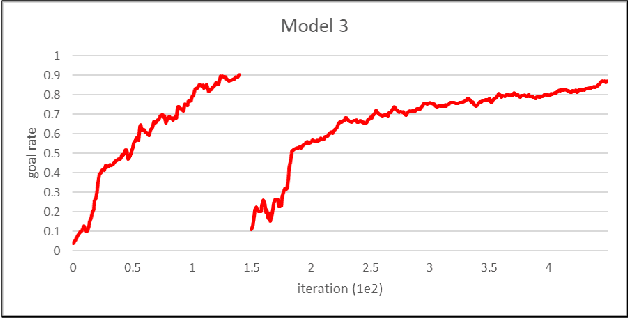
Multi-agent reinforcement learning was performed in this study for indoor path planning of two unmanned aerial vehicles (UAVs). Each UAV performed the task of moving as fast as possible from a randomly paired initial position to a goal position in an environment with obstacles. To minimize training time and prevent the damage of UAVs, learning was performed by simulation. Considering the non-stationary characteristics of the multi-agent environment wherein the optimal behavior varies based on the actions of other agents, the action of the other UAV was also included in the state space of each UAV. Curriculum learning was performed in two stages to increase learning efficiency. A goal rate of 89.0% was obtained compared with other learning strategies that obtained goal rates of 73.6% and 79.9%.