 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugWard: Augmentation-Aware Representation Learning for Accurate Graph Classification
Mar 27, 2025How can we accurately classify graphs? Graph classification is a pivotal task in data mining with applications in social network analysis, web analysis, drug discovery, molecular property prediction, etc. Graph neural networks have achieved the state-of-the-art performance in graph classification, but they consistently struggle with overfitting. To mitigate overfitting, researchers have introduced various representation learning methods utilizing graph augmentation. However, existing methods rely on simplistic use of graph augmentation, which loses augmentation-induced differences and limits the expressiveness of representations. In this paper, we propose AugWard (Augmentation-Aware Training with Graph Distance and Consistency Regularization), a novel graph representation learning framework that carefully considers the diversity introduced by graph augmentation. AugWard applies augmentation-aware training to predict the graph distance between the augmented graph and its original one, aligning the representation difference directly with graph distance at both feature and structure levels. Furthermore, AugWard employs consistency regularization to encourage the classifier to handle richer representations. Experimental results show that AugWard gives the state-of-the-art performance in supervised, semi-supervised graph classification, and transfer learning.
Multi-Behavior Recommender Systems: A Survey
Mar 10, 2025Traditional recommender systems primarily rely on a single type of user-item interaction, such as item purchases or ratings, to predict user preferences. However, in real-world scenarios, users engage in a variety of behaviors, such as clicking on items or adding them to carts, offering richer insights into their interests. Multi-behavior recommender systems leverage these diverse interactions to enhance recommendation quality, and research on this topic has grown rapidly in recent years. This survey provides a timely review of multi-behavior recommender systems, focusing on three key steps: (1) Data Modeling: representing multi-behaviors at the input level, (2) Encoding: transforming these inputs into vector representations (i.e., embeddings), and (3) Training: optimizing machine-learning models. We systematically categorize existing multi-behavior recommender systems based on the commonalities and differences in their approaches across the above steps. Additionally, we discuss promising future directions for advancing multi-behavior recommender systems.
Effective and Lightweight Representation Learning for Link Sign Prediction in Signed Bipartite Graphs
Dec 25, 2024



How can we effectively and efficiently learn node representations in signed bipartite graphs? A signed bipartite graph is a graph consisting of two nodes sets where nodes of different types are positively or negative connected, and it has been extensively used to model various real-world relationships such as e-commerce, etc. To analyze such a graph, previous studies have focused on designing methods for learning node representations using graph neural networks. In particular, these methods insert edges between nodes of the same type based on balance theory, enabling them to leverage augmented structures in their learning. However, the existing methods rely on a naive message passing design, which is prone to over-smoothing and susceptible to noisy interactions in real-world graphs. Furthermore, they suffer from computational inefficiency due to their heavy design and the significant increase in the number of added edges. In this paper, we propose ELISE, an effective and lightweight GNN-based approach for learning signed bipartite graphs. We first extend personalized propagation to a signed bipartite graph, incorporating signed edges during message passing. This extension adheres to balance theory without introducing additional edges, mitigating the over-smoothing issue and enhancing representation power. We then jointly learn node embeddings on a low-rank approximation of the signed bipartite graph, which reduces potential noise and emphasizes its global structure, further improving expressiveness without significant loss of efficiency. We encapsulate these ideas into ELISE, designing it to be lightweight, unlike the previous methods that add too many edges and cause inefficiency. Through extensive experiments on real-world signed bipartite graphs, we demonstrate that ELISE outperforms its competitors for predicting link signs while providing faster training and inference time.
TensorCodec: Compact Lossy Compression of Tensors without Strong Data Assumptions
Sep 20, 2023



Many real-world datasets are represented as tensors, i.e., multi-dimensional arrays of numerical values. Storing them without compression often requires substantial space, which grows exponentially with the order. While many tensor compression algorithms are available, many of them rely on strong data assumptions regarding its order, sparsity, rank, and smoothness. In this work, we propose TENSORCODEC, a lossy compression algorithm for general tensors that do not necessarily adhere to strong input data assumptions. TENSORCODEC incorporates three key ideas. The first idea is Neural Tensor-Train Decomposition (NTTD) where we integrate a recurrent neural network into Tensor-Train Decomposition to enhance its expressive power and alleviate the limitations imposed by the low-rank assumption. Another idea is to fold the input tensor into a higher-order tensor to reduce the space required by NTTD. Finally, the mode indices of the input tensor are reordered to reveal patterns that can be exploited by NTTD for improved approximation. Our analysis and experiments on 8 real-world datasets demonstrate that TENSORCODEC is (a) Concise: it gives up to 7.38x more compact compression than the best competitor with similar reconstruction error, (b) Accurate: given the same budget for compressed size, it yields up to 3.33x more accurate reconstruction than the best competitor, (c) Scalable: its empirical compression time is linear in the number of tensor entries, and it reconstructs each entry in logarithmic time. Our code and datasets are available at https://github.com/kbrother/TensorCodec.
Learning Disentangled Representations in Signed Directed Graphs without Social Assumptions
Jul 06, 2023Signed graphs are complex systems that represent trust relationships or preferences in various domains. Learning node representations in such graphs is crucial for many mining tasks. Although real-world signed relationships can be influenced by multiple latent factors, most existing methods often oversimplify the modeling of signed relationships by relying on social theories and treating them as simplistic factors. This limits their expressiveness and their ability to capture the diverse factors that shape these relationships. In this paper, we propose DINES, a novel method for learning disentangled node representations in signed directed graphs without social assumptions. We adopt a disentangled framework that separates each embedding into distinct factors, allowing for capturing multiple latent factors. We also explore lightweight graph convolutions that focus solely on sign and direction, without depending on social theories. Additionally, we propose a decoder that effectively classifies an edge's sign by considering correlations between the factors. To further enhance disentanglement, we jointly train a self-supervised factor discriminator with our encoder and decoder. Throughout extensive experiments on real-world signed directed graphs, we show that DINES effectively learns disentangled node representations, and significantly outperforms its competitors in the sign prediction task.
NeuKron: Constant-Size Lossy Compression of Sparse Reorderable Matrices and Tensors
Feb 09, 2023



Many real-world data are naturally represented as a sparse reorderable matrix, whose rows and columns can be arbitrarily ordered (e.g., the adjacency matrix of a bipartite graph). Storing a sparse matrix in conventional ways requires an amount of space linear in the number of non-zeros, and lossy compression of sparse matrices (e.g., Truncated SVD) typically requires an amount of space linear in the number of rows and columns. In this work, we propose NeuKron for compressing a sparse reorderable matrix into a constant-size space. NeuKron generalizes Kronecker products using a recurrent neural network with a constant number of parameters. NeuKron updates the parameters so that a given matrix is approximated by the product and reorders the rows and columns of the matrix to facilitate the approximation. The updates take time linear in the number of non-zeros in the input matrix, and the approximation of each entry can be retrieved in logarithmic time. We also extend NeuKron to compress sparse reorderable tensors (e.g. multi-layer graphs), which generalize matrices. Through experiments on ten real-world datasets, we show that NeuKron is (a) Compact: requiring up to five orders of magnitude less space than its best competitor with similar approximation errors, (b) Accurate: giving up to 10x smaller approximation error than its best competitors with similar size outputs, and (c) Scalable: successfully compressing a matrix with over 230 million non-zero entries.
Time-aware Random Walk Diffusion to Improve Dynamic Graph Learning
Nov 04, 2022How can we augment a dynamic graph for improving the performance of dynamic graph neural networks? Graph augmentation has been widely utilized to boost the learning performance of GNN-based models. However, most existing approaches only enhance spatial structure within an input static graph by transforming the graph, and do not consider dynamics caused by time such as temporal locality, i.e., recent edges are more influential than earlier ones, which remains challenging for dynamic graph augmentation. In this work, we propose TiaRa (Time-aware Random Walk Diffusion), a novel diffusion-based method for augmenting a dynamic graph represented as a discrete-time sequence of graph snapshots. For this purpose, we first design a time-aware random walk proximity so that a surfer can walk along the time dimension as well as edges, resulting in spatially and temporally localized scores. We then derive our diffusion matrices based on the time-aware random walk, and show they become enhanced adjacency matrices that both spatial and temporal localities are augmented. Throughout extensive experiments, we demonstrate that TiaRa effectively augments a given dynamic graph, and leads to significant improvements in dynamic GNN models for various graph datasets and tasks.
Accurate Node Feature Estimation with Structured Variational Graph Autoencoder
Jun 09, 2022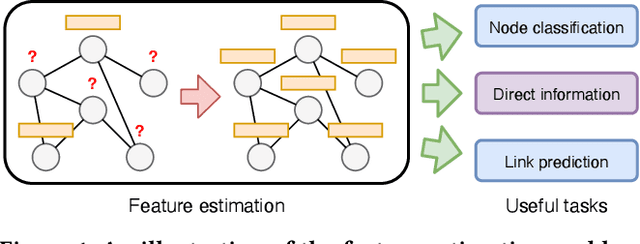
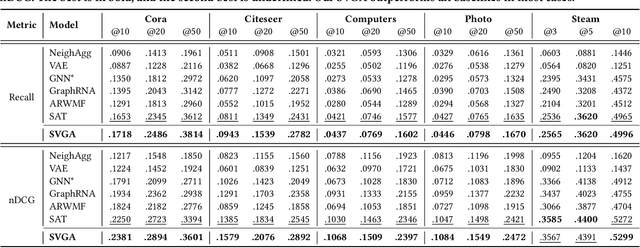
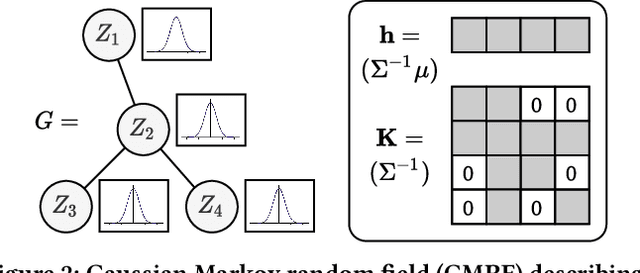
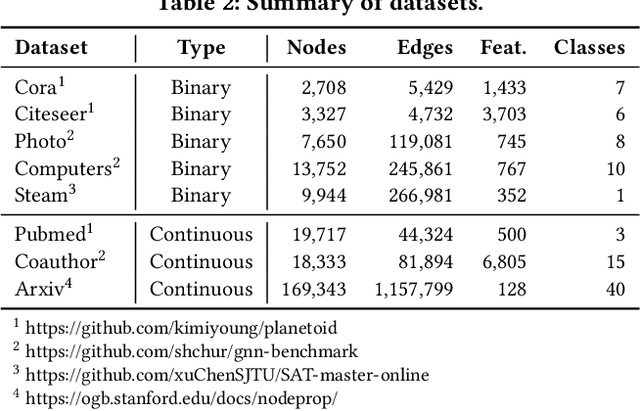
Given a graph with partial observations of node features, how can we estimate the missing features accurately? Feature estimation is a crucial problem for analyzing real-world graphs whose features are commonly missing during the data collection process. Accurate estimation not only provides diverse information of nodes but also supports the inference of graph neural networks that require the full observation of node features. However, designing an effective approach for estimating high-dimensional features is challenging, since it requires an estimator to have large representation power, increasing the risk of overfitting. In this work, we propose SVGA (Structured Variational Graph Autoencoder), an accurate method for feature estimation. SVGA applies strong regularization to the distribution of latent variables by structured variational inference, which models the prior of variables as Gaussian Markov random field based on the graph structure. As a result, SVGA combines the advantages of probabilistic inference and graph neural networks, achieving state-of-the-art performance in real datasets.
Signed Graph Diffusion Network
Dec 28, 2020



Given a signed social graph, how can we learn appropriate node representations to infer the signs of missing edges? Signed social graphs have received considerable attention to model trust relationships. Learning node representations is crucial to effectively analyze graph data, and various techniques such as network embedding and graph convolutional network (GCN) have been proposed for learning signed graphs. However, traditional network embedding methods are not end-to-end for a specific task such as link sign prediction, and GCN-based methods suffer from a performance degradation problem when their depth increases. In this paper, we propose Signed Graph Diffusion Network (SGDNet), a novel graph neural network that achieves end-to-end node representation learning for link sign prediction in signed social graphs. We propose a random walk technique specially designed for signed graphs so that SGDNet effectively diffuses hidden node features. Through extensive experiments, we demonstrate that SGDNet outperforms state-of-the-art models in terms of link sign prediction accuracy.
T-GAP: Learning to Walk across Time for Temporal Knowledge Graph Completion
Dec 19, 2020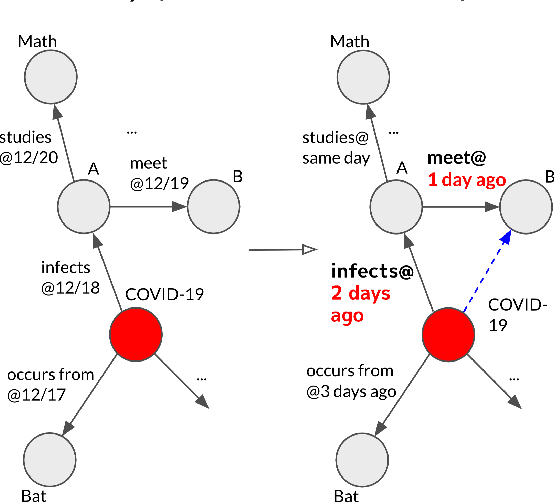



Temporal knowledge graphs (TKGs) inherently reflect the transient nature of real-world knowledge, as opposed to static knowledge graphs. Naturally, automatic TKG completion has drawn much research interests for a more realistic modeling of relational reasoning. However, most of the existing mod-els for TKG completion extend static KG embeddings that donot fully exploit TKG structure, thus lacking in 1) account-ing for temporally relevant events already residing in the lo-cal neighborhood of a query, and 2) path-based inference that facilitates multi-hop reasoning and better interpretability. In this paper, we propose T-GAP, a novel model for TKG completion that maximally utilizes both temporal information and graph structure in its encoder and decoder. T-GAP encodes query-specific substructure of TKG by focusing on the temporal displacement between each event and the query times-tamp, and performs path-based inference by propagating attention through the graph. Our empirical experiments demonstrate that T-GAP not only achieves superior performance against state-of-the-art baselines, but also competently generalizes to queries with unseen timestamps. Through extensive qualitative analyses, we also show that T-GAP enjoys from transparent interpretability, and follows human intuition in its reasoning process.