 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFuGe: Feature Generation for Prediction Tasks on Relational Databases with LLM Agents
Jan 25, 2026Relational databases (RDBs) play a crucial role in many real-world web applications, supporting data management across multiple interconnected tables. Beyond typical retrieval-oriented tasks, prediction tasks on RDBs have recently gained attention. In this work, we address this problem by generating informative relational features that enhance predictive performance. However, generating such features is challenging: it requires reasoning over complex schemas and exploring a combinatorially large feature space, all without explicit supervision. To address these challenges, we propose ReFuGe, an agentic framework that leverages specialized large language model agents: (1) a schema selection agent identifies the tables and columns relevant to the task, (2) a feature generation agent produces diverse candidate features from the selected schema, and (3) a feature filtering agent evaluates and retains promising features through reasoning-based and validation-based filtering. It operates within an iterative feedback loop until performance converges. Experiments on RDB benchmarks demonstrate that ReFuGe substantially improves performance on various RDB prediction tasks. Our code and datasets are available at https://github.com/K-Kyungho/REFUGE.
Feature-Centric Unsupervised Node Representation Learning Without Homophily Assumption
Dec 17, 2025Unsupervised node representation learning aims to obtain meaningful node embeddings without relying on node labels. To achieve this, graph convolution, which aggregates information from neighboring nodes, is commonly employed to encode node features and graph topology. However, excessive reliance on graph convolution can be suboptimal-especially in non-homophilic graphs-since it may yield unduly similar embeddings for nodes that differ in their features or topological properties. As a result, adjusting the degree of graph convolution usage has been actively explored in supervised learning settings, whereas such approaches remain underexplored in unsupervised scenarios. To tackle this, we propose FUEL, which adaptively learns the adequate degree of graph convolution usage by aiming to enhance intra-class similarity and inter-class separability in the embedding space. Since classes are unknown, FUEL leverages node features to identify node clusters and treats these clusters as proxies for classes. Through extensive experiments using 15 baseline methods and 14 benchmark datasets, we demonstrate the effectiveness of FUEL in downstream tasks, achieving state-of-the-art performance across graphs with diverse levels of homophily.
ItemRAG: Item-Based Retrieval-Augmented Generation for LLM-Based Recommendation
Nov 19, 2025Recently, large language models (LLMs) have been widely used as recommender systems, owing to their strong reasoning capability and their effectiveness in handling cold-start items. To better adapt LLMs for recommendation, retrieval-augmented generation (RAG) has been incorporated. Most existing RAG methods are user-based, retrieving purchase patterns of users similar to the target user and providing them to the LLM. In this work, we propose ItemRAG, an item-based RAG method for LLM-based recommendation that retrieves relevant items (rather than users) from item-item co-purchase histories. ItemRAG helps LLMs capture co-purchase patterns among items, which are beneficial for recommendations. Especially, our retrieval strategy incorporates semantically similar items to better handle cold-start items and uses co-purchase frequencies to improve the relevance of the retrieved items. Through extensive experiments, we demonstrate that ItemRAG consistently (1) improves the zero-shot LLM-based recommender by up to 43% in Hit-Ratio-1 and (2) outperforms user-based RAG baselines under both standard and cold-start item recommendation settings.
A Self-Supervised Mixture-of-Experts Framework for Multi-behavior Recommendation
Aug 28, 2025
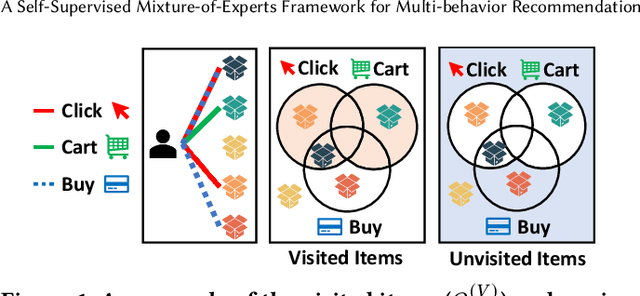
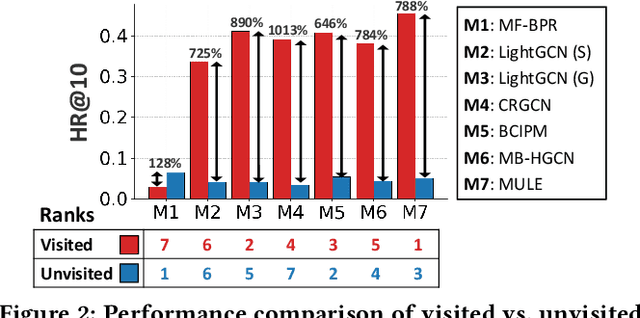
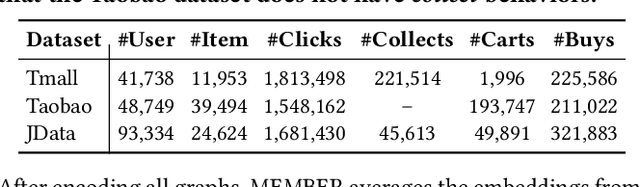
In e-commerce, where users face a vast array of possible item choices, recommender systems are vital for helping them discover suitable items they might otherwise overlook. While many recommender systems primarily rely on a user's purchase history, recent multi-behavior recommender systems incorporate various auxiliary user behaviors, such as item clicks and cart additions, to enhance recommendations. Despite their overall performance gains, their effectiveness varies considerably between visited items (i.e., those a user has interacted with through auxiliary behaviors) and unvisited items (i.e., those with which the user has had no such interactions). Specifically, our analysis reveals that (1) existing multi-behavior recommender systems exhibit a significant gap in recommendation quality between the two item types (visited and unvisited items) and (2) achieving strong performance on both types with a single model architecture remains challenging. To tackle these issues, we propose a novel multi-behavior recommender system, MEMBER. It employs a mixture-of-experts framework, with experts designed to recommend the two item types, respectively. Each expert is trained using a self-supervised method specialized for its design goal. In our comprehensive experiments, we show the effectiveness of MEMBER across both item types, achieving up to 65.46% performance gain over the best competitor in terms of Hit Ratio@20.
Multi-Behavior Recommender Systems: A Survey
Mar 10, 2025Traditional recommender systems primarily rely on a single type of user-item interaction, such as item purchases or ratings, to predict user preferences. However, in real-world scenarios, users engage in a variety of behaviors, such as clicking on items or adding them to carts, offering richer insights into their interests. Multi-behavior recommender systems leverage these diverse interactions to enhance recommendation quality, and research on this topic has grown rapidly in recent years. This survey provides a timely review of multi-behavior recommender systems, focusing on three key steps: (1) Data Modeling: representing multi-behaviors at the input level, (2) Encoding: transforming these inputs into vector representations (i.e., embeddings), and (3) Training: optimizing machine-learning models. We systematically categorize existing multi-behavior recommender systems based on the commonalities and differences in their approaches across the above steps. Additionally, we discuss promising future directions for advancing multi-behavior recommender systems.
Rethinking Reconstruction-based Graph-Level Anomaly Detection: Limitations and a Simple Remedy
Oct 27, 2024Graph autoencoders (Graph-AEs) learn representations of given graphs by aiming to accurately reconstruct them. A notable application of Graph-AEs is graph-level anomaly detection (GLAD), whose objective is to identify graphs with anomalous topological structures and/or node features compared to the majority of the graph population. Graph-AEs for GLAD regard a graph with a high mean reconstruction error (i.e. mean of errors from all node pairs and/or nodes) as anomalies. Namely, the methods rest on the assumption that they would better reconstruct graphs with similar characteristics to the majority. We, however, report non-trivial counter-examples, a phenomenon we call reconstruction flip, and highlight the limitations of the existing Graph-AE-based GLAD methods. Specifically, we empirically and theoretically investigate when this assumption holds and when it fails. Through our analyses, we further argue that, while the reconstruction errors for a given graph are effective features for GLAD, leveraging the multifaceted summaries of the reconstruction errors, beyond just mean, can further strengthen the features. Thus, we propose a novel and simple GLAD method, named MUSE. The key innovation of MUSE involves taking multifaceted summaries of reconstruction errors as graph features for GLAD. This surprisingly simple method obtains SOTA performance in GLAD, performing best overall among 14 methods across 10 datasets.
Unsupervised Extractive Dialogue Summarization in Hyperdimensional Space
May 16, 2024We present HyperSum, an extractive summarization framework that captures both the efficiency of traditional lexical summarization and the accuracy of contemporary neural approaches. HyperSum exploits the pseudo-orthogonality that emerges when randomly initializing vectors at extremely high dimensions ("blessing of dimensionality") to construct representative and efficient sentence embeddings. Simply clustering the obtained embeddings and extracting their medoids yields competitive summaries. HyperSum often outperforms state-of-the-art summarizers -- in terms of both summary accuracy and faithfulness -- while being 10 to 100 times faster. We open-source HyperSum as a strong baseline for unsupervised extractive summarization.