 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Hierarchical Consistency and Unbiased Objectness for Open-Vocabulary Object Detection
Apr 25, 2026Conventional object detectors typically operate under a closed-set assumption, limiting recognition to a predefined set of base classes seen during training. Open-vocabulary object detection (OVD) addresses this limitation by leveraging vision-language models (VLMs) to generate pseudo labels for novel object classes. However, existing OVD methods suffer from two critical drawbacks: (1) inaccurate class label assignments, as VLMs are optimized for image-level predictions rather than the region-level predictions required for pseudo labeling, and (2) unreliable objectness scores from region proposal networks (RPNs) trained exclusively on base object classes. To address these issues, we propose a novel pseudo labeling framework for OVD. Our approach introduces a hierarchical confidence calibration (HCC) technique, which ensures reliable class label estimation by assessing consistency across hierarchical semantic levels (class, super- and sub-category). We also present LoCLIP, a parameter-efficient adaptation of CLIP that incorporates an objectness token to mitigate base class bias problem of RPNs and provide reliable objectness estimations for novel object classes. Extensive experiments on standard OVD benchmarks, including COCO and LVIS, demonstrate that our approach clearly sets a new state of the art, validating the effectiveness of our approach. Project site: https://cvlab.yonsei.ac.kr/projects/HCC
ReFuGe: Feature Generation for Prediction Tasks on Relational Databases with LLM Agents
Jan 25, 2026Relational databases (RDBs) play a crucial role in many real-world web applications, supporting data management across multiple interconnected tables. Beyond typical retrieval-oriented tasks, prediction tasks on RDBs have recently gained attention. In this work, we address this problem by generating informative relational features that enhance predictive performance. However, generating such features is challenging: it requires reasoning over complex schemas and exploring a combinatorially large feature space, all without explicit supervision. To address these challenges, we propose ReFuGe, an agentic framework that leverages specialized large language model agents: (1) a schema selection agent identifies the tables and columns relevant to the task, (2) a feature generation agent produces diverse candidate features from the selected schema, and (3) a feature filtering agent evaluates and retains promising features through reasoning-based and validation-based filtering. It operates within an iterative feedback loop until performance converges. Experiments on RDB benchmarks demonstrate that ReFuGe substantially improves performance on various RDB prediction tasks. Our code and datasets are available at https://github.com/K-Kyungho/REFUGE.
ItemRAG: Item-Based Retrieval-Augmented Generation for LLM-Based Recommendation
Nov 19, 2025Recently, large language models (LLMs) have been widely used as recommender systems, owing to their strong reasoning capability and their effectiveness in handling cold-start items. To better adapt LLMs for recommendation, retrieval-augmented generation (RAG) has been incorporated. Most existing RAG methods are user-based, retrieving purchase patterns of users similar to the target user and providing them to the LLM. In this work, we propose ItemRAG, an item-based RAG method for LLM-based recommendation that retrieves relevant items (rather than users) from item-item co-purchase histories. ItemRAG helps LLMs capture co-purchase patterns among items, which are beneficial for recommendations. Especially, our retrieval strategy incorporates semantically similar items to better handle cold-start items and uses co-purchase frequencies to improve the relevance of the retrieved items. Through extensive experiments, we demonstrate that ItemRAG consistently (1) improves the zero-shot LLM-based recommender by up to 43% in Hit-Ratio-1 and (2) outperforms user-based RAG baselines under both standard and cold-start item recommendation settings.
SDS KoPub VDR: A Benchmark Dataset for Visual Document Retrieval in Korean Public Documents
Nov 07, 2025Existing benchmarks for visual document retrieval (VDR) largely overlook non-English languages and the structural complexity of official publications. To address this critical gap, we introduce SDS KoPub VDR, the first large-scale, publicly available benchmark for retrieving and understanding Korean public documents. The benchmark is built upon a corpus of 361 real-world documents (40,781 pages), including 256 files under the KOGL Type 1 license and 105 from official legal portals, capturing complex visual elements like tables, charts, and multi-column layouts. To establish a challenging and reliable evaluation set, we constructed 600 query-page-answer triples. These were initially generated using multimodal models (e.g., GPT-4o) and subsequently underwent a rigorous human verification and refinement process to ensure factual accuracy and contextual relevance. The queries span six major public domains and are systematically categorized by the reasoning modality required: text-based, visual-based (e.g., chart interpretation), and cross-modal. We evaluate SDS KoPub VDR on two complementary tasks that reflect distinct retrieval paradigms: (1) text-only retrieval, which measures a model's ability to locate relevant document pages based solely on textual signals, and (2) multimodal retrieval, which assesses retrieval performance when visual features (e.g., tables, charts, and layouts) are jointly leveraged alongside text. This dual-task evaluation reveals substantial performance gaps, particularly in multimodal scenarios requiring cross-modal reasoning, even for state-of-the-art models. As a foundational resource, SDS KoPub VDR not only enables rigorous and fine-grained evaluation across textual and multimodal retrieval tasks but also provides a clear roadmap for advancing multimodal AI in complex, real-world document intelligence.
A Self-Supervised Mixture-of-Experts Framework for Multi-behavior Recommendation
Aug 28, 2025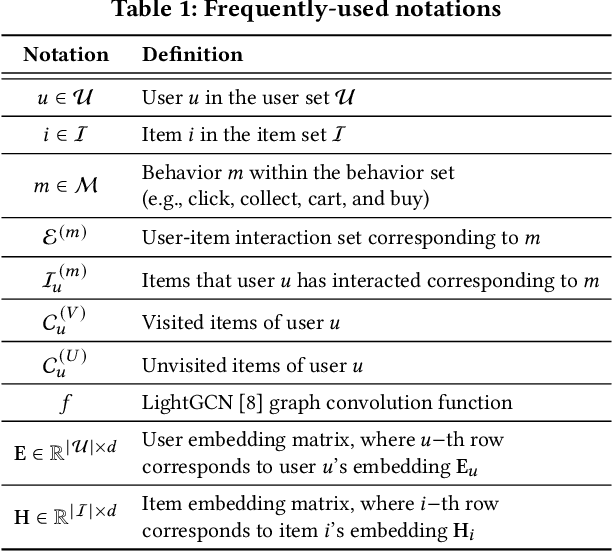
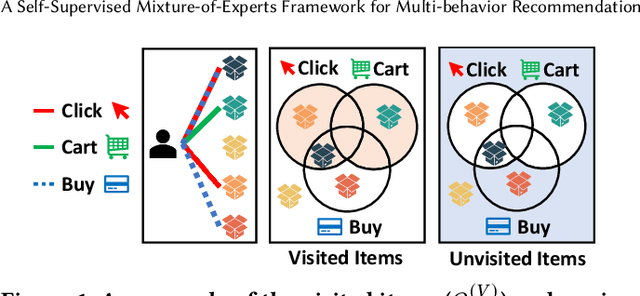
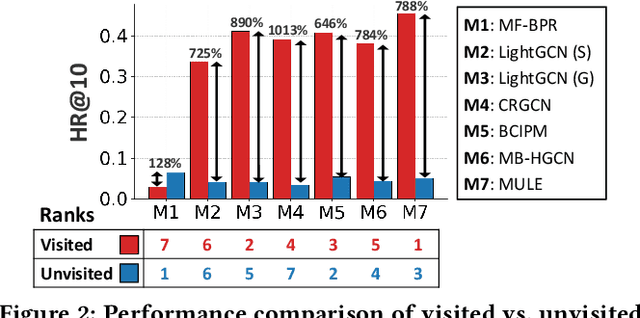
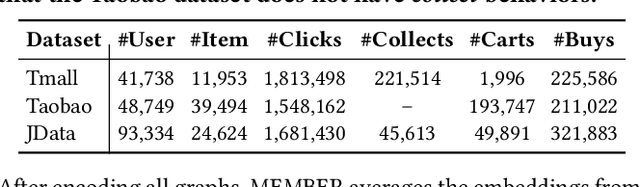
In e-commerce, where users face a vast array of possible item choices, recommender systems are vital for helping them discover suitable items they might otherwise overlook. While many recommender systems primarily rely on a user's purchase history, recent multi-behavior recommender systems incorporate various auxiliary user behaviors, such as item clicks and cart additions, to enhance recommendations. Despite their overall performance gains, their effectiveness varies considerably between visited items (i.e., those a user has interacted with through auxiliary behaviors) and unvisited items (i.e., those with which the user has had no such interactions). Specifically, our analysis reveals that (1) existing multi-behavior recommender systems exhibit a significant gap in recommendation quality between the two item types (visited and unvisited items) and (2) achieving strong performance on both types with a single model architecture remains challenging. To tackle these issues, we propose a novel multi-behavior recommender system, MEMBER. It employs a mixture-of-experts framework, with experts designed to recommend the two item types, respectively. Each expert is trained using a self-supervised method specialized for its design goal. In our comprehensive experiments, we show the effectiveness of MEMBER across both item types, achieving up to 65.46% performance gain over the best competitor in terms of Hit Ratio@20.
KGMEL: Knowledge Graph-Enhanced Multimodal Entity Linking
Apr 21, 2025


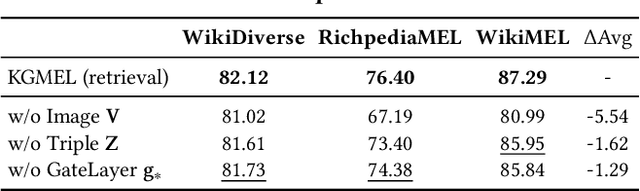
Entity linking (EL) aligns textual mentions with their corresponding entities in a knowledge base, facilitating various applications such as semantic search and question answering. Recent advances in multimodal entity linking (MEL) have shown that combining text and images can reduce ambiguity and improve alignment accuracy. However, most existing MEL methods overlook the rich structural information available in the form of knowledge-graph (KG) triples. In this paper, we propose KGMEL, a novel framework that leverages KG triples to enhance MEL. Specifically, it operates in three stages: (1) Generation: Produces high-quality triples for each mention by employing vision-language models based on its text and images. (2) Retrieval: Learns joint mention-entity representations, via contrastive learning, that integrate text, images, and (generated or KG) triples to retrieve candidate entities for each mention. (3) Reranking: Refines the KG triples of the candidate entities and employs large language models to identify the best-matching entity for the mention. Extensive experiments on benchmark datasets demonstrate that KGMEL outperforms existing methods. Our code and datasets are available at: https://github.com/juyeonnn/KGMEL.
MARIOH: Multiplicity-Aware Hypergraph Reconstruction
Apr 01, 2025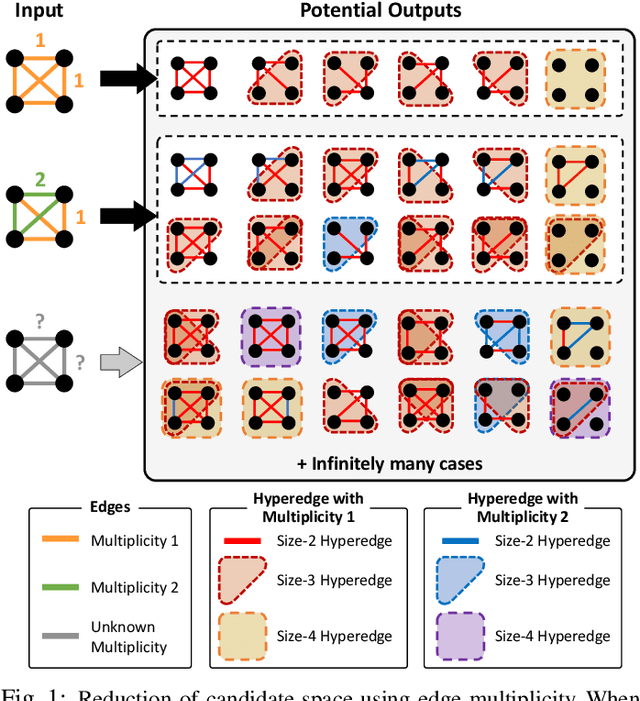
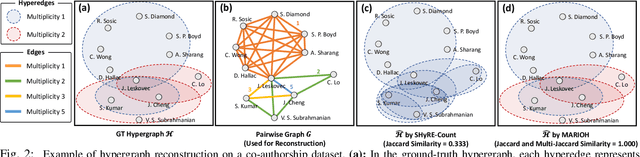
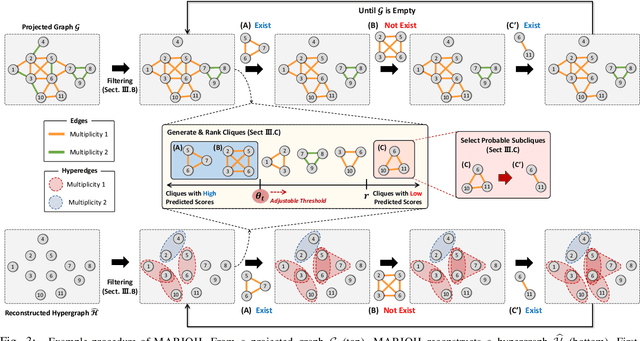
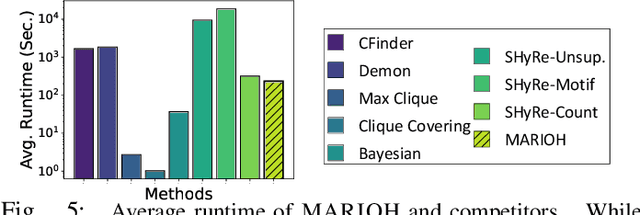
Hypergraphs offer a powerful framework for modeling higher-order interactions that traditional pairwise graphs cannot fully capture. However, practical constraints often lead to their simplification into projected graphs, resulting in substantial information loss and ambiguity in representing higher-order relationships. In this work, we propose MARIOH, a supervised approach for reconstructing the original hypergraph from its projected graph by leveraging edge multiplicity. To overcome the difficulties posed by the large search space, MARIOH integrates several key ideas: (a) identifying provable size-2 hyperedges, which reduces the candidate search space, (b) predicting the likelihood of candidates being hyperedges by utilizing both structural and multiplicity-related features, and (c) not only targeting promising hyperedge candidates but also examining less confident ones to explore alternative possibilities. Together, these ideas enable MARIOH to efficiently and effectively explore the search space. In our experiments using 10 real-world datasets, MARIOH achieves up to 74.51% higher reconstruction accuracy compared to state-of-the-art methods.
Multi-Behavior Recommender Systems: A Survey
Mar 10, 2025Traditional recommender systems primarily rely on a single type of user-item interaction, such as item purchases or ratings, to predict user preferences. However, in real-world scenarios, users engage in a variety of behaviors, such as clicking on items or adding them to carts, offering richer insights into their interests. Multi-behavior recommender systems leverage these diverse interactions to enhance recommendation quality, and research on this topic has grown rapidly in recent years. This survey provides a timely review of multi-behavior recommender systems, focusing on three key steps: (1) Data Modeling: representing multi-behaviors at the input level, (2) Encoding: transforming these inputs into vector representations (i.e., embeddings), and (3) Training: optimizing machine-learning models. We systematically categorize existing multi-behavior recommender systems based on the commonalities and differences in their approaches across the above steps. Additionally, we discuss promising future directions for advancing multi-behavior recommender systems.
Explainable Multi-modal Time Series Prediction with LLM-in-the-Loop
Mar 02, 2025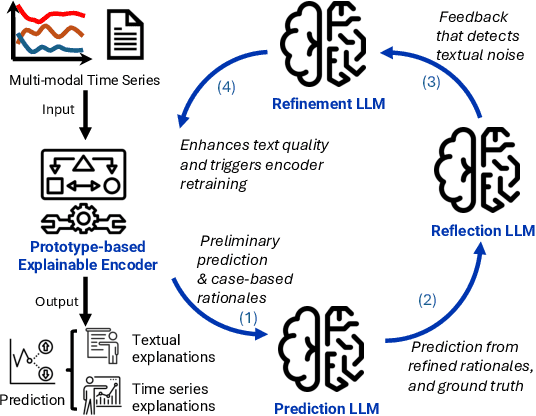

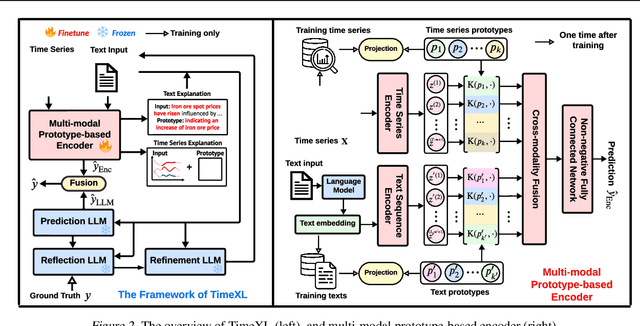
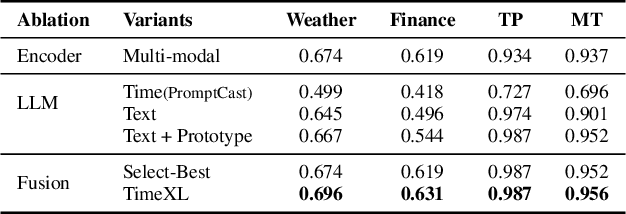
Time series analysis provides essential insights for real-world system dynamics and informs downstream decision-making, yet most existing methods often overlook the rich contextual signals present in auxiliary modalities. To bridge this gap, we introduce TimeXL, a multi-modal prediction framework that integrates a prototype-based time series encoder with three collaborating Large Language Models (LLMs) to deliver more accurate predictions and interpretable explanations. First, a multi-modal prototype-based encoder processes both time series and textual inputs to generate preliminary forecasts alongside case-based rationales. These outputs then feed into a prediction LLM, which refines the forecasts by reasoning over the encoder's predictions and explanations. Next, a reflection LLM compares the predicted values against the ground truth, identifying textual inconsistencies or noise. Guided by this feedback, a refinement LLM iteratively enhances text quality and triggers encoder retraining. This closed-loop workflow -- prediction, critique (reflect), and refinement -- continuously boosts the framework's performance and interpretability. Empirical evaluations on four real-world datasets demonstrate that TimeXL achieves up to 8.9\% improvement in AUC and produces human-centric, multi-modal explanations, highlighting the power of LLM-driven reasoning for time series prediction.
TimeCAP: Learning to Contextualize, Augment, and Predict Time Series Events with Large Language Model Agents
Feb 17, 2025Time series data is essential in various applications, including climate modeling, healthcare monitoring, and financial analytics. Understanding the contextual information associated with real-world time series data is often essential for accurate and reliable event predictions. In this paper, we introduce TimeCAP, a time-series processing framework that creatively employs Large Language Models (LLMs) as contextualizers of time series data, extending their typical usage as predictors. TimeCAP incorporates two independent LLM agents: one generates a textual summary capturing the context of the time series, while the other uses this enriched summary to make more informed predictions. In addition, TimeCAP employs a multi-modal encoder that synergizes with the LLM agents, enhancing predictive performance through mutual augmentation of inputs with in-context examples. Experimental results on real-world datasets demonstrate that TimeCAP outperforms state-of-the-art methods for time series event prediction, including those utilizing LLMs as predictors, achieving an average improvement of 28.75% in F1 score.