 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGMEL: Knowledge Graph-Enhanced Multimodal Entity Linking
Paper and Code



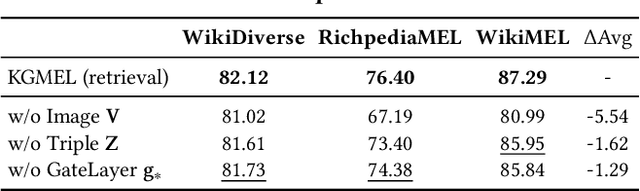
Entity linking (EL) aligns textual mentions with their corresponding entities in a knowledge base, facilitating various applications such as semantic search and question answering. Recent advances in multimodal entity linking (MEL) have shown that combining text and images can reduce ambiguity and improve alignment accuracy. However, most existing MEL methods overlook the rich structural information available in the form of knowledge-graph (KG) triples. In this paper, we propose KGMEL, a novel framework that leverages KG triples to enhance MEL. Specifically, it operates in three stages: (1) Generation: Produces high-quality triples for each mention by employing vision-language models based on its text and images. (2) Retrieval: Learns joint mention-entity representations, via contrastive learning, that integrate text, images, and (generated or KG) triples to retrieve candidate entities for each mention. (3) Reranking: Refines the KG triples of the candidate entities and employs large language models to identify the best-matching entity for the mention. Extensive experiments on benchmark datasets demonstrate that KGMEL outperforms existing methods. Our code and datasets are available at: https://github.com/juyeonnn/KGMEL.