 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFuGe: Feature Generation for Prediction Tasks on Relational Databases with LLM Agents
Jan 25, 2026Relational databases (RDBs) play a crucial role in many real-world web applications, supporting data management across multiple interconnected tables. Beyond typical retrieval-oriented tasks, prediction tasks on RDBs have recently gained attention. In this work, we address this problem by generating informative relational features that enhance predictive performance. However, generating such features is challenging: it requires reasoning over complex schemas and exploring a combinatorially large feature space, all without explicit supervision. To address these challenges, we propose ReFuGe, an agentic framework that leverages specialized large language model agents: (1) a schema selection agent identifies the tables and columns relevant to the task, (2) a feature generation agent produces diverse candidate features from the selected schema, and (3) a feature filtering agent evaluates and retains promising features through reasoning-based and validation-based filtering. It operates within an iterative feedback loop until performance converges. Experiments on RDB benchmarks demonstrate that ReFuGe substantially improves performance on various RDB prediction tasks. Our code and datasets are available at https://github.com/K-Kyungho/REFUGE.
ControlMed: Adding Reasoning Control to Medical Language Model
Jul 30, 2025



Reasoning Large Language Models (LLMs) with enhanced accuracy and explainability are increasingly being adopted in the medical domain, as the life-critical nature of clinical decision-making demands reliable support. Despite these advancements, existing reasoning LLMs often generate unnecessarily lengthy reasoning processes, leading to significant computational overhead and response latency. These limitations hinder their practical deployment in real-world clinical environments. To address these challenges, we introduce \textbf{ControlMed}, a medical language model that enables users to actively control the length of the reasoning process at inference time through fine-grained control markers. ControlMed is trained through a three-stage pipeline: 1) pre-training on a large-scale synthetic medical instruction dataset covering both \textit{direct} and \textit{reasoning responses}; 2) supervised fine-tuning with multi-length reasoning data and explicit length-control markers; and 3) reinforcement learning with model-based reward signals to enhance factual accuracy and response quality. Experimental results on a variety of English and Korean medical benchmarks demonstrate that our model achieves similar or better performance compared to state-of-the-art models. Furthermore, users can flexibly balance reasoning accuracy and computational efficiency by controlling the reasoning length as needed. These findings demonstrate that ControlMed is a practical and adaptable solution for clinical question answering and medical information analysis.
KGMEL: Knowledge Graph-Enhanced Multimodal Entity Linking
Apr 21, 2025


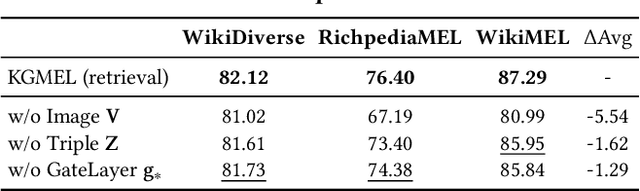
Entity linking (EL) aligns textual mentions with their corresponding entities in a knowledge base, facilitating various applications such as semantic search and question answering. Recent advances in multimodal entity linking (MEL) have shown that combining text and images can reduce ambiguity and improve alignment accuracy. However, most existing MEL methods overlook the rich structural information available in the form of knowledge-graph (KG) triples. In this paper, we propose KGMEL, a novel framework that leverages KG triples to enhance MEL. Specifically, it operates in three stages: (1) Generation: Produces high-quality triples for each mention by employing vision-language models based on its text and images. (2) Retrieval: Learns joint mention-entity representations, via contrastive learning, that integrate text, images, and (generated or KG) triples to retrieve candidate entities for each mention. (3) Reranking: Refines the KG triples of the candidate entities and employs large language models to identify the best-matching entity for the mention. Extensive experiments on benchmark datasets demonstrate that KGMEL outperforms existing methods. Our code and datasets are available at: https://github.com/juyeonnn/KGMEL.
Text2Chart31: Instruction Tuning for Chart Generation with Automatic Feedback
Oct 05, 2024



Large language models (LLMs) have demonstrated strong capabilities across various language tasks, notably through instruction-tuning methods. However, LLMs face challenges in visualizing complex, real-world data through charts and plots. Firstly, existing datasets rarely cover a full range of chart types, such as 3D, volumetric, and gridded charts. Secondly, supervised fine-tuning methods do not fully leverage the intricate relationships within rich datasets, including text, code, and figures. To address these challenges, we propose a hierarchical pipeline and a new dataset for chart generation. Our dataset, Text2Chart31, includes 31 unique plot types referring to the Matplotlib library, with 11.1K tuples of descriptions, code, data tables, and plots. Moreover, we introduce a reinforcement learning-based instruction tuning technique for chart generation tasks without requiring human feedback. Our experiments show that this approach significantly enhances the model performance, enabling smaller models to outperform larger open-source models and be comparable to state-of-the-art proprietary models in data visualization tasks. We make the code and dataset available at https://github.com/fatemehpesaran310/Text2Chart31.
Re-Ex: Revising after Explanation Reduces the Factual Errors in LLM Responses
Feb 27, 2024



Mitigating hallucination issues is one of the main challenges of LLMs we need to overcome, in order to reliably use them in real-world scenarios. Recently, various methods are proposed to check the factual errors in the LLM-generated texts and revise them accordingly, to reduce the hallucination issue. In this paper, we propose Re-Ex, a method of revising LLM-generated texts, which introduces a novel step dubbed as the factual error explanation step. Re-Ex revises the initial response of LLMs using 3-steps: first, external tools are used to get the evidences on the factual errors in the response; second, LLMs are instructed to explain the problematic parts of the response based on the evidences gathered in the first step; finally, LLMs revise the response using the explanation obtained in the second step. In addition to the explanation step, we propose new prompting techniques to reduce the amount of tokens and wall-clock time required for the response revision process. Compared with existing methods including Factool, CoVE, and RARR, Re-Ex provides better revision performance with less time and fewer tokens in multiple benchmarks.