 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour AI, Not Your View: The Bias of LLMs in Investment Analysis
Jul 28, 2025In finance, Large Language Models (LLMs) face frequent knowledge conflicts due to discrepancies between pre-trained parametric knowledge and real-time market data. These conflicts become particularly problematic when LLMs are deployed in real-world investment services, where misalignment between a model's embedded preferences and those of the financial institution can lead to unreliable recommendations. Yet little research has examined what investment views LLMs actually hold. We propose an experimental framework to investigate such conflicts, offering the first quantitative analysis of confirmation bias in LLM-based investment analysis. Using hypothetical scenarios with balanced and imbalanced arguments, we extract models' latent preferences and measure their persistence. Focusing on sector, size, and momentum, our analysis reveals distinct, model-specific tendencies. In particular, we observe a consistent preference for large-cap stocks and contrarian strategies across most models. These preferences often harden into confirmation bias, with models clinging to initial judgments despite counter-evidence.
Structuring the Unstructured: A Multi-Agent System for Extracting and Querying Financial KPIs and Guidance
May 25, 2025Extracting structured and quantitative insights from unstructured financial filings is essential in investment research, yet remains time-consuming and resource-intensive. Conventional approaches in practice rely heavily on labor-intensive manual processes, limiting scalability and delaying the research workflow. In this paper, we propose an efficient and scalable method for accurately extracting quantitative insights from unstructured financial documents, leveraging a multi-agent system composed of large language models. Our proposed multi-agent system consists of two specialized agents: the \emph{Extraction Agent} and the \emph{Text-to-SQL Agent}. The \textit{Extraction Agent} automatically identifies key performance indicators from unstructured financial text, standardizes their formats, and verifies their accuracy. On the other hand, the \textit{Text-to-SQL Agent} generates executable SQL statements from natural language queries, allowing users to access structured data accurately without requiring familiarity with the database schema. Through experiments, we demonstrate that our proposed system effectively transforms unstructured text into structured data accurately and enables precise retrieval of key information. First, we demonstrate that our system achieves approximately 95\% accuracy in transforming financial filings into structured data, matching the performance level typically attained by human annotators. Second, in a human evaluation of the retrieval task -- where natural language queries are used to search information from structured data -- 91\% of the responses were rated as correct by human evaluators. In both evaluations, our system generalizes well across financial document types, consistently delivering reliable performance.
FinDER: Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation
Apr 22, 2025In the fast-paced financial domain, accurate and up-to-date information is critical to addressing ever-evolving market conditions. Retrieving this information correctly is essential in financial Question-Answering (QA), since many language models struggle with factual accuracy in this domain. We present FinDER, an expert-generated dataset tailored for Retrieval-Augmented Generation (RAG) in finance. Unlike existing QA datasets that provide predefined contexts and rely on relatively clear and straightforward queries, FinDER focuses on annotating search-relevant evidence by domain experts, offering 5,703 query-evidence-answer triplets derived from real-world financial inquiries. These queries frequently include abbreviations, acronyms, and concise expressions, capturing the brevity and ambiguity common in the realistic search behavior of professionals. By challenging models to retrieve relevant information from large corpora rather than relying on readily determined contexts, FinDER offers a more realistic benchmark for evaluating RAG systems. We further present a comprehensive evaluation of multiple state-of-the-art retrieval models and Large Language Models, showcasing challenges derived from a realistic benchmark to drive future research on truthful and precise RAG in the financial domain.
Linq-Embed-Mistral Technical Report
Dec 04, 2024
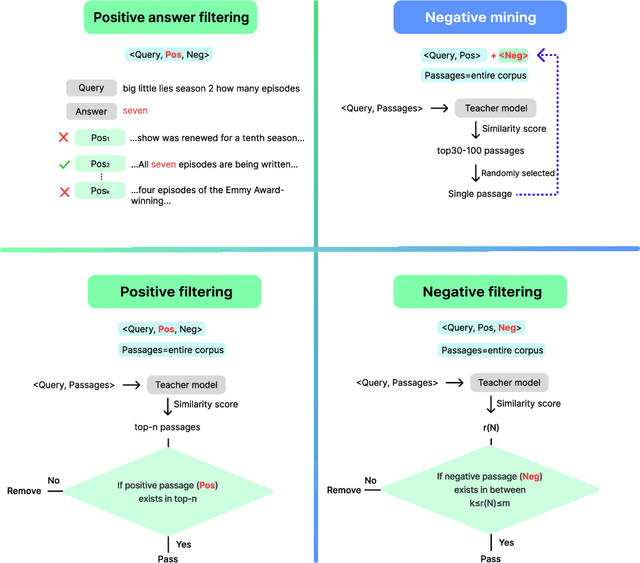

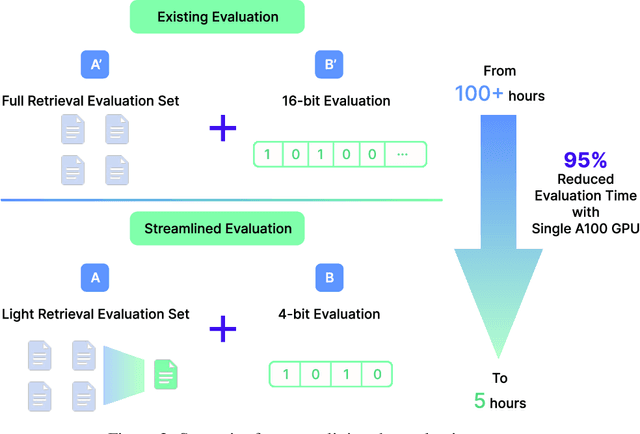
This report explores the enhancement of text retrieval performance using advanced data refinement techniques. We develop Linq-Embed-Mistral\footnote{\url{https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral}} by building on the E5-mistral and Mistral-7B-v0.1 models, focusing on sophisticated data crafting, data filtering, and negative mining methods, which are highly tailored to each task, applied to both existing benchmark dataset and highly tailored synthetic dataset generated via large language models (LLMs). Linq-Embed-Mistral excels in the MTEB benchmarks (as of May 29, 2024), achieving an average score of 68.2 across 56 datasets, and ranks 1st among all models for retrieval tasks on the MTEB leaderboard with a performance score of 60.2. This performance underscores its superior capability in enhancing search precision and reliability. Our contributions include advanced data refinement methods that significantly improve model performance on benchmark and synthetic datasets, techniques for homogeneous task ordering and mixed task fine-tuning to enhance model generalization and stability, and a streamlined evaluation process using 4-bit precision and a light retrieval evaluation set, which accelerates validation without sacrificing accuracy.
Improving Multi-lingual Alignment Through Soft Contrastive Learning
May 28, 2024Making decent multi-lingual sentence representations is critical to achieve high performances in cross-lingual downstream tasks. In this work, we propose a novel method to align multi-lingual embeddings based on the similarity of sentences measured by a pre-trained mono-lingual embedding model. Given translation sentence pairs, we train a multi-lingual model in a way that the similarity between cross-lingual embeddings follows the similarity of sentences measured at the mono-lingual teacher model. Our method can be considered as contrastive learning with soft labels defined as the similarity between sentences. Our experimental results on five languages show that our contrastive loss with soft labels far outperforms conventional contrastive loss with hard labels in various benchmarks for bitext mining tasks and STS tasks. In addition, our method outperforms existing multi-lingual embeddings including LaBSE, for Tatoeba dataset. The code is available at https://github.com/YAI12xLinq-B/IMASCL
Re-Ex: Revising after Explanation Reduces the Factual Errors in LLM Responses
Feb 27, 2024



Mitigating hallucination issues is one of the main challenges of LLMs we need to overcome, in order to reliably use them in real-world scenarios. Recently, various methods are proposed to check the factual errors in the LLM-generated texts and revise them accordingly, to reduce the hallucination issue. In this paper, we propose Re-Ex, a method of revising LLM-generated texts, which introduces a novel step dubbed as the factual error explanation step. Re-Ex revises the initial response of LLMs using 3-steps: first, external tools are used to get the evidences on the factual errors in the response; second, LLMs are instructed to explain the problematic parts of the response based on the evidences gathered in the first step; finally, LLMs revise the response using the explanation obtained in the second step. In addition to the explanation step, we propose new prompting techniques to reduce the amount of tokens and wall-clock time required for the response revision process. Compared with existing methods including Factool, CoVE, and RARR, Re-Ex provides better revision performance with less time and fewer tokens in multiple benchmarks.
Can Separators Improve Chain-of-Thought Prompting?
Feb 16, 2024



Chain-of-thought (CoT) prompting is a simple and effective method for improving the reasoning capabilities of Large language models (LLMs). The basic idea of CoT is to let LLMs break down their thought processes step-by-step by putting exemplars in the input prompt. However, the densely structured prompt exemplars of CoT may cause the cognitive overload of LLMs. Inspired by human cognition, we introduce CoT-Sep, a novel method that strategically employs separators at the end of each exemplar in CoT prompting. These separators are designed to help the LLMs understand their thought processes better while reasoning. It turns out that CoT-Sep significantly improves the LLMs' performances on complex reasoning tasks (e.g., GSM-8K, AQuA, CSQA), compared with the vanilla CoT, which does not use separators. We also study the effects of the type and the location of separators tested on multiple LLMs, including GPT-3.5-Turbo, GPT-4, and LLaMA-2 7B. Interestingly, the type/location of separators should be chosen appropriately to boost the reasoning capability of CoT.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.