 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructuring the Unstructured: A Multi-Agent System for Extracting and Querying Financial KPIs and Guidance
May 25, 2025Extracting structured and quantitative insights from unstructured financial filings is essential in investment research, yet remains time-consuming and resource-intensive. Conventional approaches in practice rely heavily on labor-intensive manual processes, limiting scalability and delaying the research workflow. In this paper, we propose an efficient and scalable method for accurately extracting quantitative insights from unstructured financial documents, leveraging a multi-agent system composed of large language models. Our proposed multi-agent system consists of two specialized agents: the \emph{Extraction Agent} and the \emph{Text-to-SQL Agent}. The \textit{Extraction Agent} automatically identifies key performance indicators from unstructured financial text, standardizes their formats, and verifies their accuracy. On the other hand, the \textit{Text-to-SQL Agent} generates executable SQL statements from natural language queries, allowing users to access structured data accurately without requiring familiarity with the database schema. Through experiments, we demonstrate that our proposed system effectively transforms unstructured text into structured data accurately and enables precise retrieval of key information. First, we demonstrate that our system achieves approximately 95\% accuracy in transforming financial filings into structured data, matching the performance level typically attained by human annotators. Second, in a human evaluation of the retrieval task -- where natural language queries are used to search information from structured data -- 91\% of the responses were rated as correct by human evaluators. In both evaluations, our system generalizes well across financial document types, consistently delivering reliable performance.
FinDER: Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation
Apr 22, 2025In the fast-paced financial domain, accurate and up-to-date information is critical to addressing ever-evolving market conditions. Retrieving this information correctly is essential in financial Question-Answering (QA), since many language models struggle with factual accuracy in this domain. We present FinDER, an expert-generated dataset tailored for Retrieval-Augmented Generation (RAG) in finance. Unlike existing QA datasets that provide predefined contexts and rely on relatively clear and straightforward queries, FinDER focuses on annotating search-relevant evidence by domain experts, offering 5,703 query-evidence-answer triplets derived from real-world financial inquiries. These queries frequently include abbreviations, acronyms, and concise expressions, capturing the brevity and ambiguity common in the realistic search behavior of professionals. By challenging models to retrieve relevant information from large corpora rather than relying on readily determined contexts, FinDER offers a more realistic benchmark for evaluating RAG systems. We further present a comprehensive evaluation of multiple state-of-the-art retrieval models and Large Language Models, showcasing challenges derived from a realistic benchmark to drive future research on truthful and precise RAG in the financial domain.
Linq-Embed-Mistral Technical Report
Dec 04, 2024
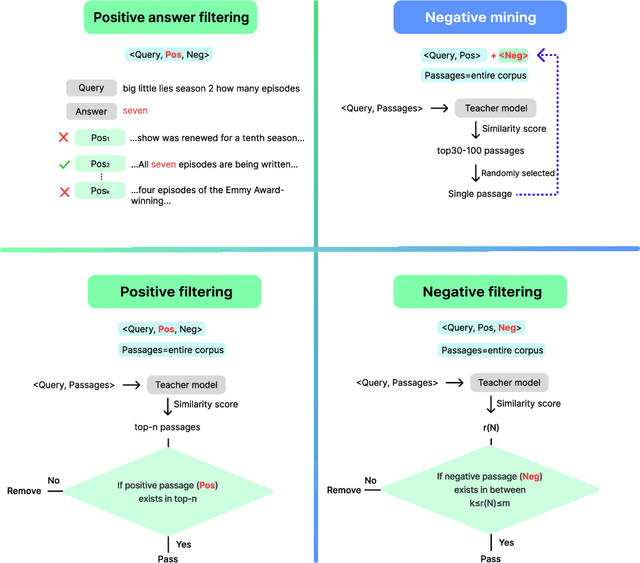

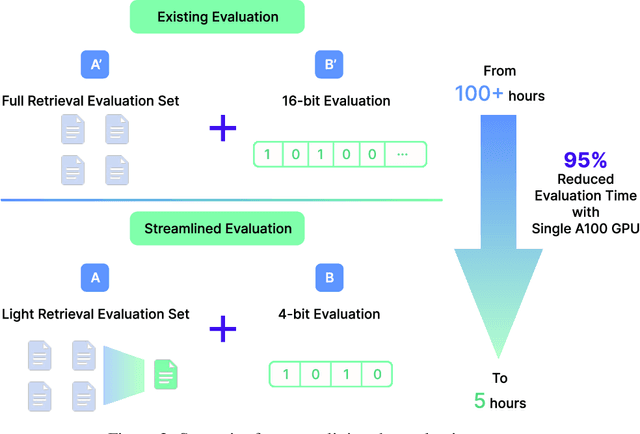
This report explores the enhancement of text retrieval performance using advanced data refinement techniques. We develop Linq-Embed-Mistral\footnote{\url{https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral}} by building on the E5-mistral and Mistral-7B-v0.1 models, focusing on sophisticated data crafting, data filtering, and negative mining methods, which are highly tailored to each task, applied to both existing benchmark dataset and highly tailored synthetic dataset generated via large language models (LLMs). Linq-Embed-Mistral excels in the MTEB benchmarks (as of May 29, 2024), achieving an average score of 68.2 across 56 datasets, and ranks 1st among all models for retrieval tasks on the MTEB leaderboard with a performance score of 60.2. This performance underscores its superior capability in enhancing search precision and reliability. Our contributions include advanced data refinement methods that significantly improve model performance on benchmark and synthetic datasets, techniques for homogeneous task ordering and mixed task fine-tuning to enhance model generalization and stability, and a streamlined evaluation process using 4-bit precision and a light retrieval evaluation set, which accelerates validation without sacrificing accuracy.