 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperficial Success vs. Internal Breakdown: An Empirical Study of Generalization in Adaptive Multi-Agent Systems
Apr 22, 2026Adaptive multi-agent systems (MAS) are increasingly adopted to tackle complex problems. However, the narrow task coverage of their optimization raises the question of whether they can function as general-purpose systems. To address this gap, we conduct an extensive empirical study of adaptive MAS, revealing two key findings: (1) topological overfitting -- they fail to generalize across different domains; and (2) illusory coordination -- they achieve reasonable surface-level accuracy while the underlying agent interactions diverge from ideal MAS behavior, raising concerns about their practical utility. These findings highlight the pressing need to prioritize generalization in MAS development and motivate evaluation protocols that extend beyond simple final-answer correctness.
Latent Preference Modeling for Cross-Session Personalized Tool Calling
Apr 20, 2026Users often omit essential details in their requests to LLM-based agents, resulting in under-specified inputs for tool use. This poses a fundamental challenge for tool-augmented agents, as API execution typically requires complete arguments, highlighting the need for personalized tool calling. To study this problem, we introduce MPT, a benchmark comprising 265 multi-session dialogues that cover three challenges: Preference Recall, Preference Induction, and Preference Transfer. We also propose PRefine, a test-time memory-augmented method that represents user preferences as evolving hypotheses. Through a generate--verify--refine loop, it extracts reusable constraints from history and improves tool-calling accuracy while using only 1.24% of the tokens required by full-history prompting. These results indicate that robust personalization in agentic systems depends on memory that captures the reasons behind user choices, not just the choices themselves.
OmniACBench: A Benchmark for Evaluating Context-Grounded Acoustic Control in Omni-Modal Models
Mar 25, 2026Most testbeds for omni-modal models assess multimodal understanding via textual outputs, leaving it unclear whether these models can properly speak their answers. To study this, we introduce OmniACBench, a benchmark for evaluating context-grounded acoustic control in omni-modal models. Given a spoken instruction, a text script, and an image, a model must read the script aloud with an appropriate tone and manner. OmniACBench comprises 3,559 verified instances covering six acoustic features: speech rate, phonation, pronunciation, emotion, global accent, and timbre. Extensive experiments on eight models reveal their limitations in the proposed setting, despite their strong performance on prior textual-output evaluations. Our analyses show that the main bottleneck lies not in processing individual modalities, but in integrating multimodal context for faithful speech generation. Moreover, we identify three common failure modes-weak direct control, failed implicit inference, and failed multimodal grounding-providing insights for developing models that can verbalize responses effectively.
Beyond Task-Oriented and Chitchat Dialogues: Proactive and Transition-Aware Conversational Agents
Nov 11, 2025Conversational agents have traditionally been developed for either task-oriented dialogue (TOD) or open-ended chitchat, with limited progress in unifying the two. Yet, real-world conversations naturally involve fluid transitions between these modes. To address this gap, we introduce TACT (TOD-And-Chitchat Transition), a dataset designed for transition-aware dialogue modeling that incorporates structurally diverse and integrated mode flows. TACT supports both user- and agent-driven mode switches, enabling robust modeling of complex conversational dynamics. To evaluate an agent's ability to initiate and recover from mode transitions, we propose two new metrics -- Switch and Recovery. Models trained on TACT outperform baselines in both intent detection and mode transition handling. Moreover, applying Direct Preference Optimization (DPO) to TACT-trained models yields additional gains, achieving 75.74\% joint mode-intent accuracy and a 70.1\% win rate against GPT-4o in human evaluation. These results demonstrate that pairing structurally diverse data with DPO enhances response quality and transition control, paving the way for more proactive and transition-aware conversational agents.
RAISE: Enhancing Scientific Reasoning in LLMs via Step-by-Step Retrieval
Jun 10, 2025Scientific reasoning requires not only long-chain reasoning processes, but also knowledge of domain-specific terminologies and adaptation to updated findings. To deal with these challenges for scientific reasoning, we introduce RAISE, a step-by-step retrieval-augmented framework which retrieves logically relevant documents from in-the-wild corpus. RAISE is divided into three steps: problem decomposition, logical query generation, and logical retrieval. We observe that RAISE consistently outperforms other baselines on scientific reasoning benchmarks. We analyze that unlike other baselines, RAISE retrieves documents that are not only similar in terms of the domain knowledge, but also documents logically more relevant.
Memorization or Reasoning? Exploring the Idiom Understanding of LLMs
May 22, 2025
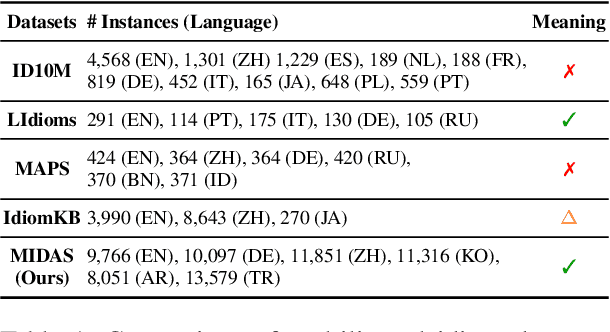


Idioms have long posed a challenge due to their unique linguistic properties, which set them apart from other common expressions. While recent studies have leveraged large language models (LLMs) to handle idioms across various tasks, e.g., idiom-containing sentence generation and idiomatic machine translation, little is known about the underlying mechanisms of idiom processing in LLMs, particularly in multilingual settings. To this end, we introduce MIDAS, a new large-scale dataset of idioms in six languages, each paired with its corresponding meaning. Leveraging this resource, we conduct a comprehensive evaluation of LLMs' idiom processing ability, identifying key factors that influence their performance. Our findings suggest that LLMs rely not only on memorization, but also adopt a hybrid approach that integrates contextual cues and reasoning, especially when processing compositional idioms. This implies that idiom understanding in LLMs emerges from an interplay between internal knowledge retrieval and reasoning-based inference.
Does Localization Inform Unlearning? A Rigorous Examination of Local Parameter Attribution for Knowledge Unlearning in Language Models
May 22, 2025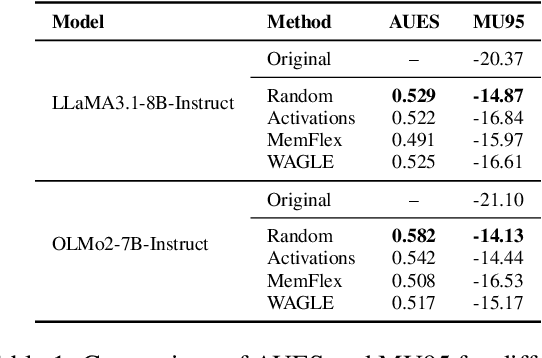
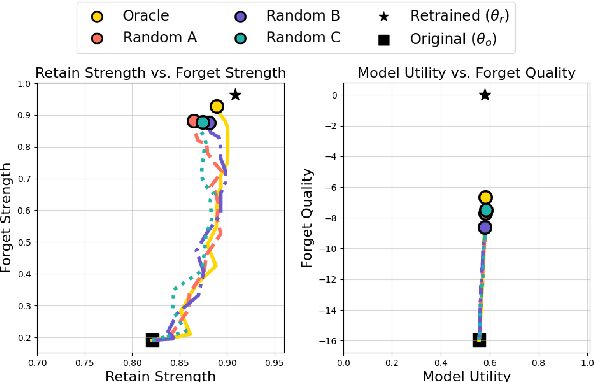
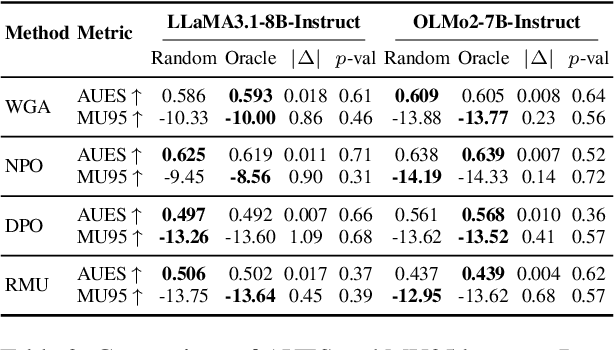
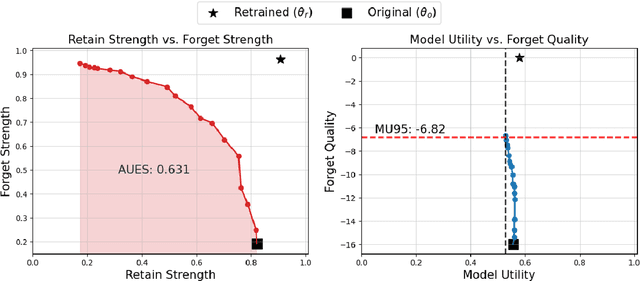
Large language models often retain unintended content, prompting growing interest in knowledge unlearning. Recent approaches emphasize localized unlearning, which restricts parameter updates to specific regions in an effort to remove target knowledge while preserving unrelated general knowledge. However, their effectiveness remains uncertain due to the lack of robust and thorough evaluation of the trade-off between the competing goals of unlearning. In this paper, we begin by revisiting existing localized unlearning approaches. We then conduct controlled experiments to rigorously evaluate whether local parameter updates causally contribute to unlearning. Our findings reveal that the set of parameters that must be modified for effective unlearning is not strictly determined, challenging the core assumption of localized unlearning that parameter locality is inherently indicative of effective knowledge removal.
KGMEL: Knowledge Graph-Enhanced Multimodal Entity Linking
Apr 21, 2025


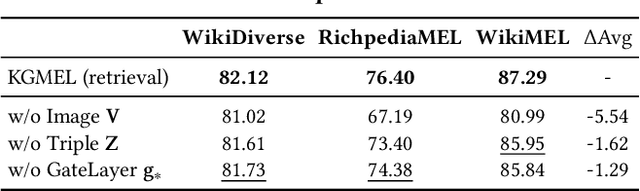
Entity linking (EL) aligns textual mentions with their corresponding entities in a knowledge base, facilitating various applications such as semantic search and question answering. Recent advances in multimodal entity linking (MEL) have shown that combining text and images can reduce ambiguity and improve alignment accuracy. However, most existing MEL methods overlook the rich structural information available in the form of knowledge-graph (KG) triples. In this paper, we propose KGMEL, a novel framework that leverages KG triples to enhance MEL. Specifically, it operates in three stages: (1) Generation: Produces high-quality triples for each mention by employing vision-language models based on its text and images. (2) Retrieval: Learns joint mention-entity representations, via contrastive learning, that integrate text, images, and (generated or KG) triples to retrieve candidate entities for each mention. (3) Reranking: Refines the KG triples of the candidate entities and employs large language models to identify the best-matching entity for the mention. Extensive experiments on benchmark datasets demonstrate that KGMEL outperforms existing methods. Our code and datasets are available at: https://github.com/juyeonnn/KGMEL.
Reliability Across Parametric and External Knowledge: Understanding Knowledge Handling in LLMs
Feb 19, 2025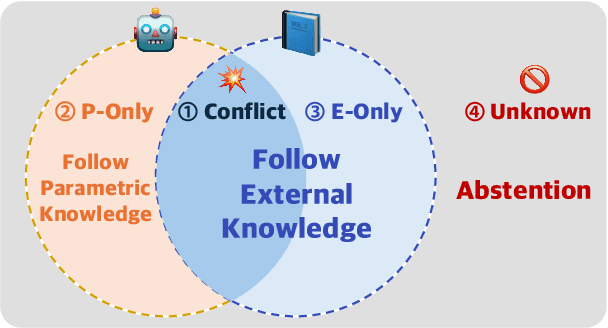
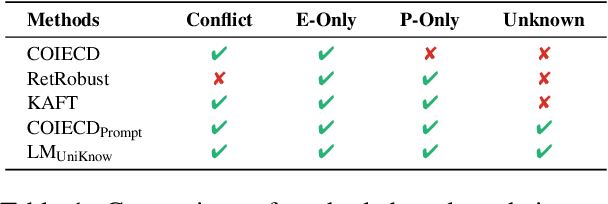
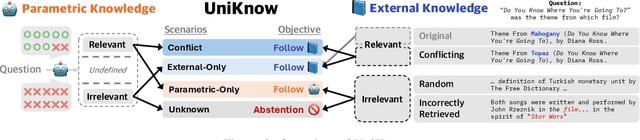
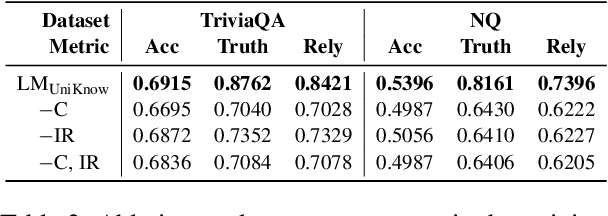
Large Language Models (LLMs) enhance their problem-solving capability by leveraging both parametric and external knowledge. Beyond leveraging external knowledge to improve response accuracy, they require key capabilities for reliable knowledge-handling: resolving conflicts between knowledge sources, avoiding distraction from uninformative external knowledge, and abstaining when sufficient knowledge is unavailable. Prior studies have examined these scenarios in isolation or with limited scope. To systematically evaluate these capabilities, we introduce a comprehensive framework for analyzing knowledge-handling based on two key dimensions: the presence of parametric knowledge and the informativeness of external knowledge. Through analysis, we identify biases in knowledge utilization and examine how the ability to handle one scenario impacts performance in others. Furthermore, we demonstrate that training on data constructed based on the knowledge-handling scenarios improves LLMs' reliability in integrating and utilizing knowledge.
FCMR: Robust Evaluation of Financial Cross-Modal Multi-Hop Reasoning
Dec 17, 2024Real-world decision-making often requires integrating and reasoning over information from multiple modalities. While recent multimodal large language models (MLLMs) have shown promise in such tasks, their ability to perform multi-hop reasoning across diverse sources remains insufficiently evaluated. Existing benchmarks, such as MMQA, face challenges due to (1) data contamination and (2) a lack of complex queries that necessitate operations across more than two modalities, hindering accurate performance assessment. To address this, we present Financial Cross-Modal Multi-Hop Reasoning (FCMR), a benchmark created to analyze the reasoning capabilities of MLLMs by urging them to combine information from textual reports, tables, and charts within the financial domain. FCMR is categorized into three difficulty levels-Easy, Medium, and Hard-facilitating a step-by-step evaluation. In particular, problems at the Hard level require precise cross-modal three-hop reasoning and are designed to prevent the disregard of any modality. Experiments on this new benchmark reveal that even state-of-the-art MLLMs struggle, with the best-performing model (Claude 3.5 Sonnet) achieving only 30.4% accuracy on the most challenging tier. We also conduct analysis to provide insights into the inner workings of the models, including the discovery of a critical bottleneck in the information retrieval phase.