 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUB: Benchmarking Context Utilisation Techniques for Language Models
May 22, 2025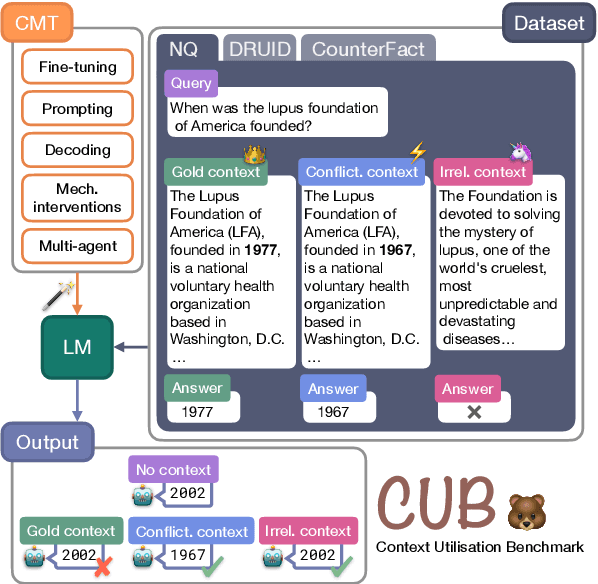



Incorporating external knowledge is crucial for knowledge-intensive tasks, such as question answering and fact checking. However, language models (LMs) may ignore relevant information that contradicts outdated parametric memory or be distracted by irrelevant contexts. While many context utilisation manipulation techniques (CMTs) that encourage or suppress context utilisation have recently been proposed to alleviate these issues, few have seen systematic comparison. In this paper, we develop CUB (Context Utilisation Benchmark) to help practitioners within retrieval-augmented generation (RAG) identify the best CMT for their needs. CUB allows for rigorous testing on three distinct context types, observed to capture key challenges in realistic context utilisation scenarios. With this benchmark, we evaluate seven state-of-the-art methods, representative of the main categories of CMTs, across three diverse datasets and tasks, applied to nine LMs. Our results show that most of the existing CMTs struggle to handle the full set of types of contexts that may be encountered in real-world retrieval-augmented scenarios. Moreover, we find that many CMTs display an inflated performance on simple synthesised datasets, compared to more realistic datasets with naturally occurring samples. Altogether, our results show the need for holistic tests of CMTs and the development of CMTs that can handle multiple context types.
Reliability Across Parametric and External Knowledge: Understanding Knowledge Handling in LLMs
Feb 19, 2025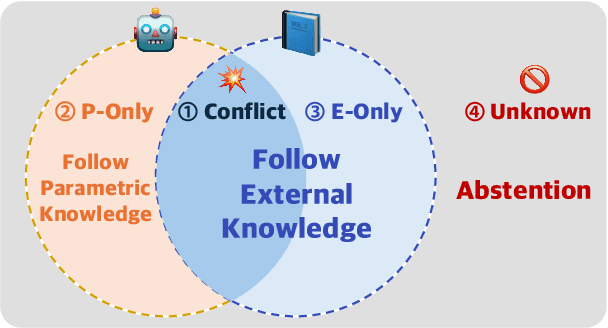
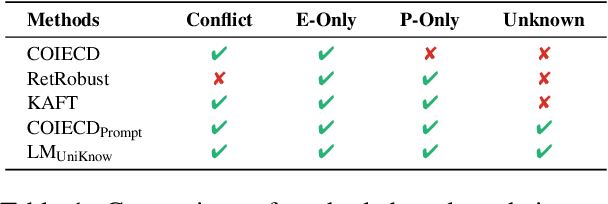
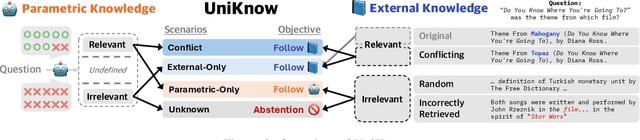
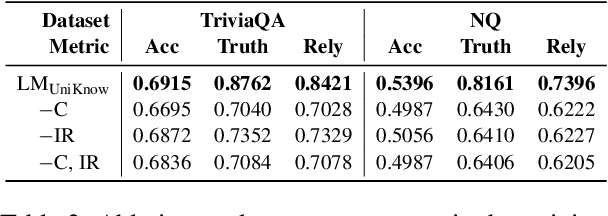
Large Language Models (LLMs) enhance their problem-solving capability by leveraging both parametric and external knowledge. Beyond leveraging external knowledge to improve response accuracy, they require key capabilities for reliable knowledge-handling: resolving conflicts between knowledge sources, avoiding distraction from uninformative external knowledge, and abstaining when sufficient knowledge is unavailable. Prior studies have examined these scenarios in isolation or with limited scope. To systematically evaluate these capabilities, we introduce a comprehensive framework for analyzing knowledge-handling based on two key dimensions: the presence of parametric knowledge and the informativeness of external knowledge. Through analysis, we identify biases in knowledge utilization and examine how the ability to handle one scenario impacts performance in others. Furthermore, we demonstrate that training on data constructed based on the knowledge-handling scenarios improves LLMs' reliability in integrating and utilizing knowledge.
When to Speak, When to Abstain: Contrastive Decoding with Abstention
Dec 17, 2024
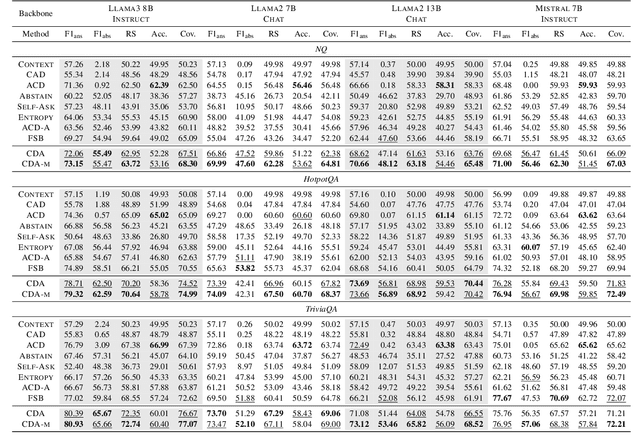
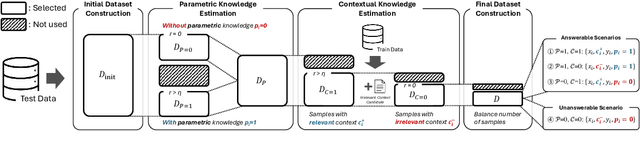
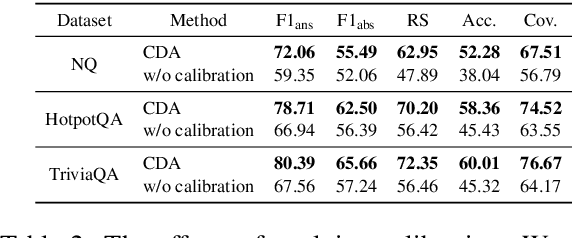
Large Language Models (LLMs) demonstrate exceptional performance across diverse tasks by leveraging both pre-trained knowledge (i.e., parametric knowledge) and external knowledge (i.e., contextual knowledge). While substantial efforts have been made to leverage both forms of knowledge, scenarios in which the model lacks any relevant knowledge remain underexplored. Such limitations can result in issues like hallucination, causing reduced reliability and potential risks in high-stakes applications. To address such limitations, this paper extends the task scope to encompass cases where the user's request cannot be fulfilled due to the lack of relevant knowledge. To this end, we introduce Contrastive Decoding with Abstention (CDA), a training-free decoding method that empowers LLMs to generate responses when relevant knowledge is available and to abstain otherwise. CDA evaluates the relevance of each knowledge for a given query, adaptively determining which knowledge to prioritize or which to completely ignore. Extensive experiments with four LLMs on three question-answering datasets demonstrate that CDA can effectively perform accurate generation and abstention simultaneously. These findings highlight CDA's potential to broaden the applicability of LLMs, enhancing reliability and preserving user trust.
Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts
Aug 02, 2024When using large language models (LLMs) in knowledge-intensive tasks, such as open-domain question answering, external context can bridge a gap between external knowledge and LLM's parametric knowledge. Recent research has been developed to amplify contextual knowledge over the parametric knowledge of LLM with contrastive decoding approaches. While these approaches could yield truthful responses when relevant context is provided, they are prone to vulnerabilities when faced with noisy contexts. We extend the scope of previous studies to encompass noisy contexts and propose adaptive contrastive decoding (ACD) to leverage contextual influence effectively. ACD demonstrates improvements in open-domain question answering tasks compared to baselines, especially in robustness by remaining undistracted by noisy contexts in retrieval-augmented generation.
Investigating the Influence of Prompt-Specific Shortcuts in AI Generated Text Detection
Jun 24, 2024



AI Generated Text (AIGT) detectors are developed with texts from humans and LLMs of common tasks. Despite the diversity of plausible prompt choices, these datasets are generally constructed with a limited number of prompts. The lack of prompt variation can introduce prompt-specific shortcut features that exist in data collected with the chosen prompt, but do not generalize to others. In this paper, we analyze the impact of such shortcuts in AIGT detection. We propose Feedback-based Adversarial Instruction List Optimization (FAILOpt), an attack that searches for instructions deceptive to AIGT detectors exploiting prompt-specific shortcuts. FAILOpt effectively drops the detection performance of the target detector, comparable to other attacks based on adversarial in-context examples. We also utilize our method to enhance the robustness of the detector by mitigating the shortcuts. Based on the findings, we further train the classifier with the dataset augmented by FAILOpt prompt. The augmented classifier exhibits improvements across generation models, tasks, and attacks. Our code will be available at https://github.com/zxcvvxcz/FAILOpt.
Aligning Language Models to Explicitly Handle Ambiguity
Apr 18, 2024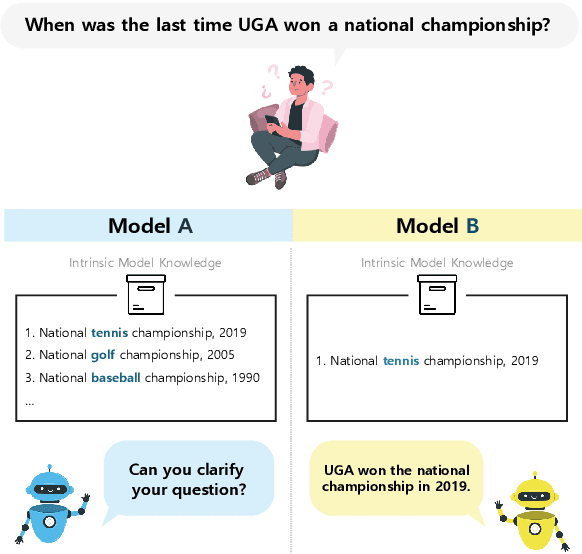
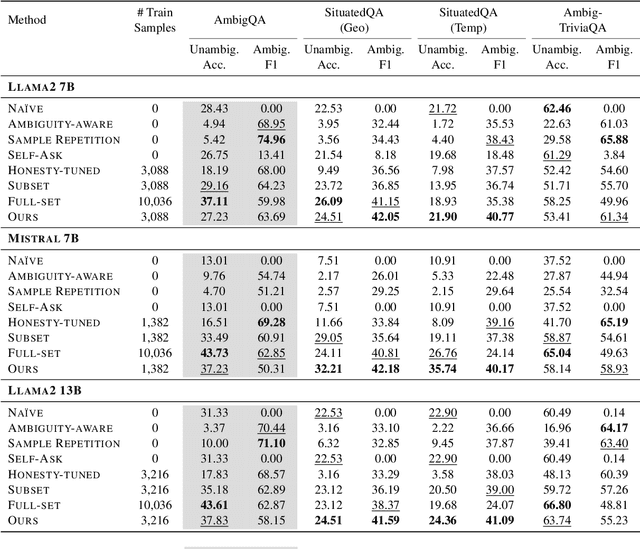
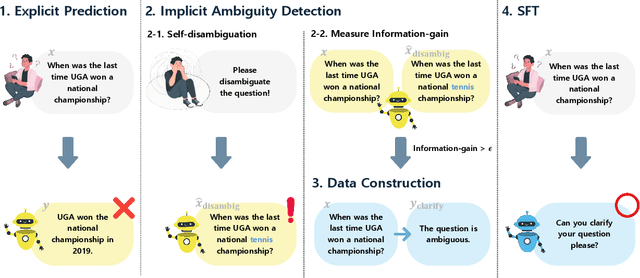
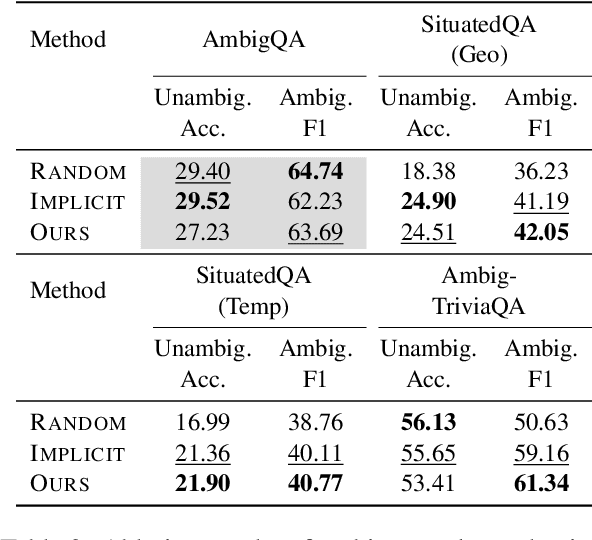
In spoken languages, utterances are often shaped to be incomplete or vague for efficiency. This can lead to varying interpretations of the same input, based on different assumptions about the context. To ensure reliable user-model interactions in such scenarios, it is crucial for models to adeptly handle the inherent ambiguity in user queries. However, conversational agents built upon even the most recent large language models (LLMs) face challenges in processing ambiguous inputs, primarily due to the following two hurdles: (1) LLMs are not directly trained to handle inputs that are too ambiguous to be properly managed; (2) the degree of ambiguity in an input can vary according to the intrinsic knowledge of the LLMs, which is difficult to investigate. To address these issues, this paper proposes a method to align LLMs to explicitly handle ambiguous inputs. Specifically, we introduce a proxy task that guides LLMs to utilize their intrinsic knowledge to self-disambiguate a given input. We quantify the information gain from the disambiguation procedure as a measure of the extent to which the models perceive their inputs as ambiguous. This measure serves as a cue for selecting samples deemed ambiguous from the models' perspectives, which are then utilized for alignment. Experimental results from several question-answering datasets demonstrate that the LLMs fine-tuned with our approach are capable of handling ambiguous inputs while still performing competitively on clear questions within the task.
CELDA: Leveraging Black-box Language Model as Enhanced Classifier without Labels
Jun 09, 2023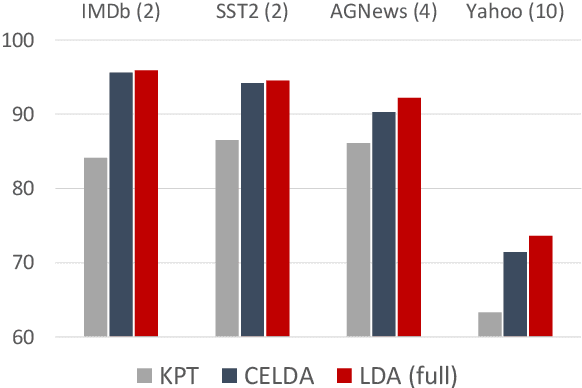
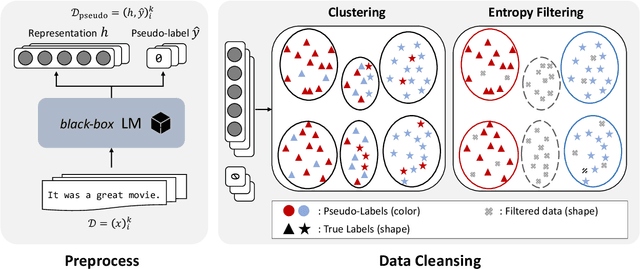

Utilizing language models (LMs) without internal access is becoming an attractive paradigm in the field of NLP as many cutting-edge LMs are released through APIs and boast a massive scale. The de-facto method in this type of black-box scenario is known as prompting, which has shown progressive performance enhancements in situations where data labels are scarce or unavailable. Despite their efficacy, they still fall short in comparison to fully supervised counterparts and are generally brittle to slight modifications. In this paper, we propose Clustering-enhanced Linear Discriminative Analysis, a novel approach that improves the text classification accuracy with a very weak-supervision signal (i.e., name of the labels). Our framework draws a precise decision boundary without accessing weights or gradients of the LM model or data labels. The core ideas of CELDA are twofold: (1) extracting a refined pseudo-labeled dataset from an unlabeled dataset, and (2) training a lightweight and robust model on the top of LM, which learns an accurate decision boundary from an extracted noisy dataset. Throughout in-depth investigations on various datasets, we demonstrated that CELDA reaches new state-of-the-art in weakly-supervised text classification and narrows the gap with a fully-supervised model. Additionally, our proposed methodology can be applied universally to any LM and has the potential to scale to larger models, making it a more viable option for utilizing large LMs.