 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewarding How Models Think Pedagogically: Integrating Pedagogical Reasoning and Thinking Rewards for LLMs in Education
Jan 21, 2026Large language models (LLMs) are increasingly deployed as intelligent tutoring systems, yet research on optimizing LLMs specifically for educational contexts remains limited. Recent works have proposed reinforcement learning approaches for training LLM tutors, but these methods focus solely on optimizing visible responses while neglecting the model's internal thinking process. We introduce PedagogicalRL-Thinking, a framework that extends pedagogical alignment to reasoning LLMs in education through two novel approaches: (1) Pedagogical Reasoning Prompting, which guides internal reasoning using domain-specific educational theory rather than generic instructions; and (2) Thinking Reward, which explicitly evaluates and reinforces the pedagogical quality of the model's reasoning traces. Our experiments reveal that domain-specific, theory-grounded prompting outperforms generic prompting, and that Thinking Reward is most effective when combined with pedagogical prompting. Furthermore, models trained only on mathematics tutoring dialogues show improved performance on educational benchmarks not seen during training, while preserving the base model's factual knowledge. Our quantitative and qualitative analyses reveal that pedagogical thinking reward produces systematic reasoning trace changes, with increased pedagogical reasoning and more structured instructional decision-making in the tutor's thinking process.
OpenLearnLM Benchmark: A Unified Framework for Evaluating Knowledge, Skill, and Attitude in Educational Large Language Models
Jan 20, 2026Large Language Models are increasingly deployed as educational tools, yet existing benchmarks focus on narrow skills and lack grounding in learning sciences. We introduce OpenLearnLM Benchmark, a theory-grounded framework evaluating LLMs across three dimensions derived from educational assessment theory: Knowledge (curriculum-aligned content and pedagogical understanding), Skills (scenario-based competencies organized through a four-level center-role-scenario-subscenario hierarchy), and Attitude (alignment consistency and deception resistance). Our benchmark comprises 124K+ items spanning multiple subjects, educational roles, and difficulty levels based on Bloom's taxonomy. The Knowledge domain prioritizes authentic assessment items from established benchmarks, while the Attitude domain adapts Anthropic's Alignment Faking methodology to detect behavioral inconsistency under varying monitoring conditions. Evaluation of seven frontier models reveals distinct capability profiles: Claude-Opus-4.5 excels in practical skills despite lower content knowledge, while Grok-4.1-fast leads in knowledge but shows alignment concerns. Notably, no single model dominates all dimensions, validating the necessity of multi-axis evaluation. OpenLearnLM provides an open, comprehensive framework for advancing LLM readiness in authentic educational contexts.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Reliability Across Parametric and External Knowledge: Understanding Knowledge Handling in LLMs
Feb 19, 2025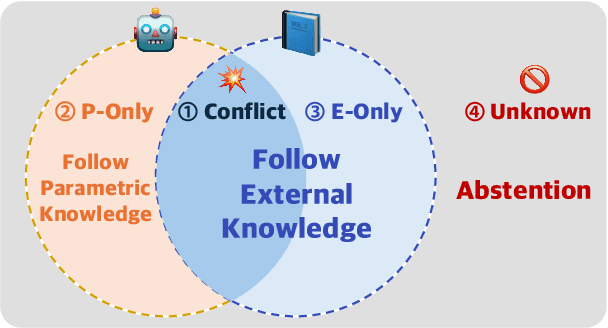
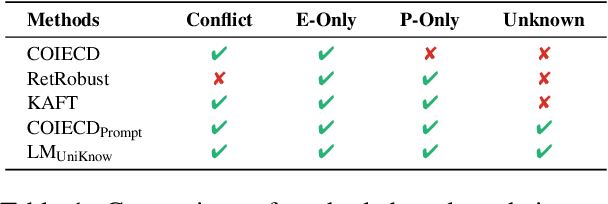
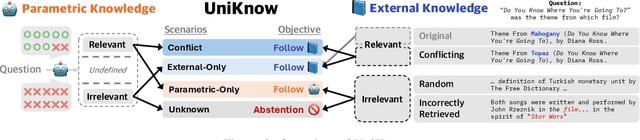
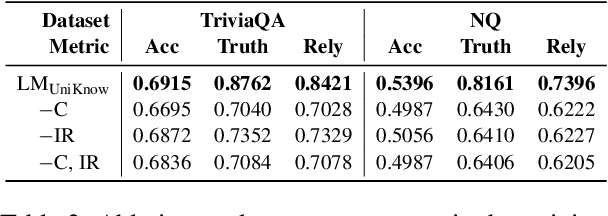
Large Language Models (LLMs) enhance their problem-solving capability by leveraging both parametric and external knowledge. Beyond leveraging external knowledge to improve response accuracy, they require key capabilities for reliable knowledge-handling: resolving conflicts between knowledge sources, avoiding distraction from uninformative external knowledge, and abstaining when sufficient knowledge is unavailable. Prior studies have examined these scenarios in isolation or with limited scope. To systematically evaluate these capabilities, we introduce a comprehensive framework for analyzing knowledge-handling based on two key dimensions: the presence of parametric knowledge and the informativeness of external knowledge. Through analysis, we identify biases in knowledge utilization and examine how the ability to handle one scenario impacts performance in others. Furthermore, we demonstrate that training on data constructed based on the knowledge-handling scenarios improves LLMs' reliability in integrating and utilizing knowledge.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Upright adjustment with graph convolutional networks
Jun 01, 2024We present a novel method for the upright adjustment of 360 images. Our network consists of two modules, which are a convolutional neural network (CNN) and a graph convolutional network (GCN). The input 360 images is processed with the CNN for visual feature extraction, and the extracted feature map is converted into a graph that finds a spherical representation of the input. We also introduce a novel loss function to address the issue of discrete probability distributions defined on the surface of a sphere. Experimental results demonstrate that our method outperforms fully connected based methods.
Spherical Transformer
Feb 11, 2022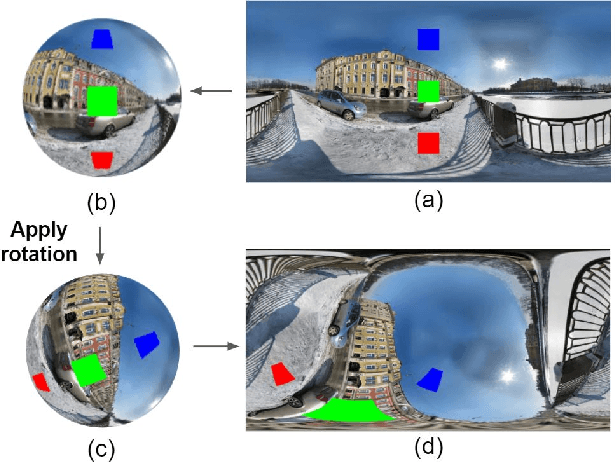
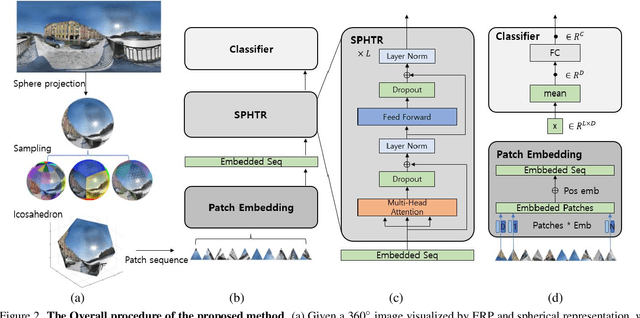
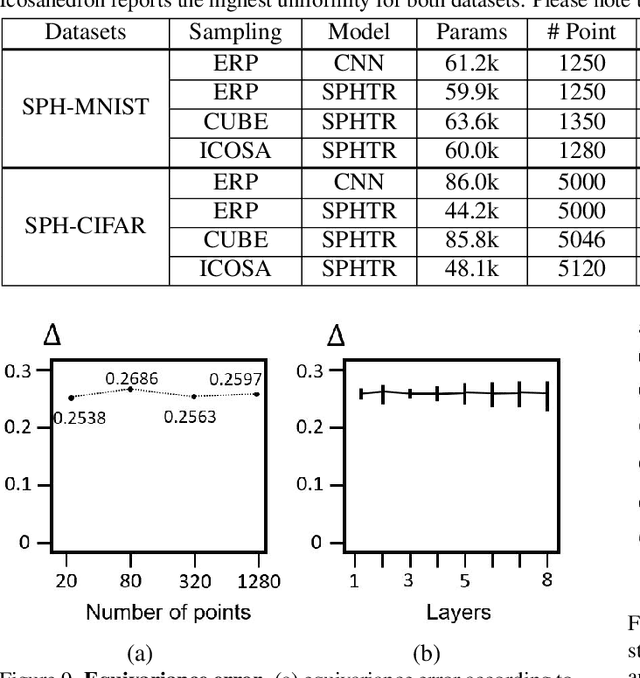
Using convolutional neural networks for 360images can induce sub-optimal performance due to distortions entailed by a planar projection. The distortion gets deteriorated when a rotation is applied to the 360image. Thus, many researches based on convolutions attempt to reduce the distortions to learn accurate representation. In contrast, we leverage the transformer architecture to solve image classification problems for 360images. Using the proposed transformer for 360images has two advantages. First, our method does not require the erroneous planar projection process by sampling pixels from the sphere surface. Second, our sampling method based on regular polyhedrons makes low rotation equivariance errors, because specific rotations can be reduced to permutations of faces. In experiments, we validate our network on two aspects, as follows. First, we show that using a transformer with highly uniform sampling methods can help reduce the distortion. Second, we demonstrate that the transformer architecture can achieve rotation equivariance on specific rotations. We compare our method to other state-of-the-art algorithms using the SPH-MNIST, SPH-CIFAR, and SUN360 datasets and show that our method is competitive with other methods.
On the Overlooked Significance of Underutilized Contextual Features in Recent News Recommendation Models
Dec 29, 2021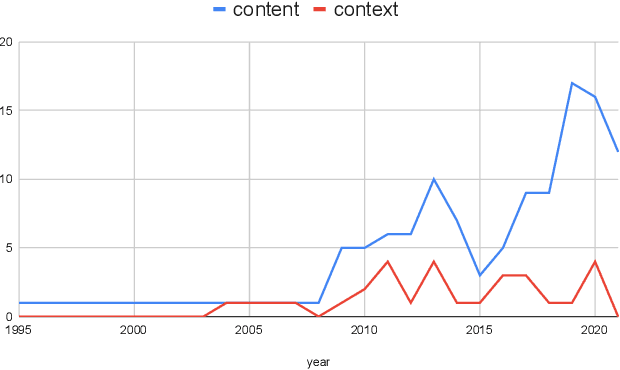
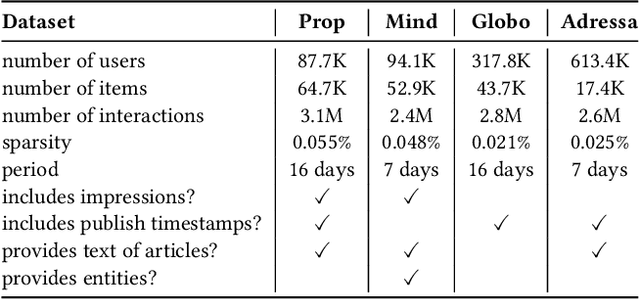
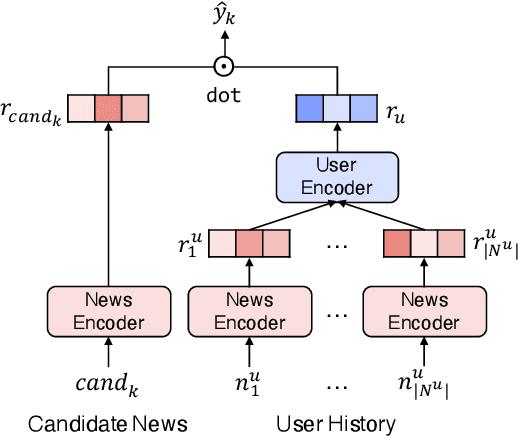
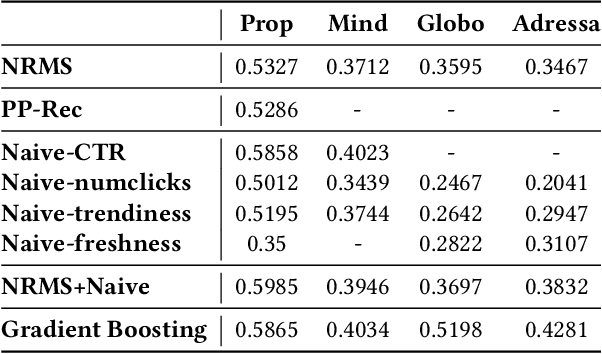
Personalized news recommendation aims to provide attractive articles for readers by predicting their likelihood of clicking on a certain article. To accurately predict this probability, plenty of studies have been proposed that actively utilize content features of articles, such as words, categories, or entities. However, we observed that the articles' contextual features, such as CTR (click-through-rate), popularity, or freshness, were either neglected or underutilized recently. To prove that this is the case, we conducted an extensive comparison between recent deep-learning models and naive contextual models that we devised and surprisingly discovered that the latter easily outperforms the former. Furthermore, our analysis showed that the recent tendency to apply overly sophisticated deep-learning operations to contextual features was actually hindering the recommendation performance. From this knowledge, we design a purposefully simple contextual module that can boost the previous news recommendation models by a large margin.