 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Calibration with Energy Based Instance-wise Scaling in the Wild Dataset
Jul 17, 2024With the rapid advancement in the performance of deep neural networks (DNNs), there has been significant interest in deploying and incorporating artificial intelligence (AI) systems into real-world scenarios. However, many DNNs lack the ability to represent uncertainty, often exhibiting excessive confidence even when making incorrect predictions. To ensure the reliability of AI systems, particularly in safety-critical cases, DNNs should transparently reflect the uncertainty in their predictions. In this paper, we investigate robust post-hoc uncertainty calibration methods for DNNs within the context of multi-class classification tasks. While previous studies have made notable progress, they still face challenges in achieving robust calibration, particularly in scenarios involving out-of-distribution (OOD). We identify that previous methods lack adaptability to individual input data and struggle to accurately estimate uncertainty when processing inputs drawn from the wild dataset. To address this issue, we introduce a novel instance-wise calibration method based on an energy model. Our method incorporates energy scores instead of softmax confidence scores, allowing for adaptive consideration of DNN uncertainty for each prediction within a logit space. In experiments, we show that the proposed method consistently maintains robust performance across the spectrum, spanning from in-distribution to OOD scenarios, when compared to other state-of-the-art methods.
Upright adjustment with graph convolutional networks
Jun 01, 2024We present a novel method for the upright adjustment of 360 images. Our network consists of two modules, which are a convolutional neural network (CNN) and a graph convolutional network (GCN). The input 360 images is processed with the CNN for visual feature extraction, and the extracted feature map is converted into a graph that finds a spherical representation of the input. We also introduce a novel loss function to address the issue of discrete probability distributions defined on the surface of a sphere. Experimental results demonstrate that our method outperforms fully connected based methods.
Spherical Transformer
Feb 11, 2022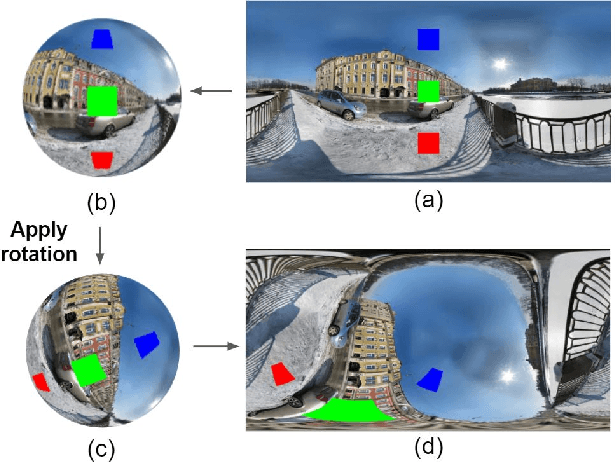
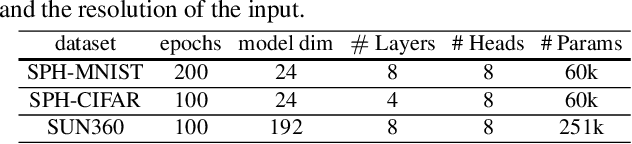
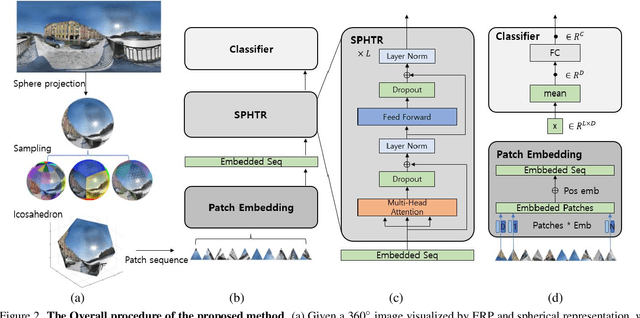
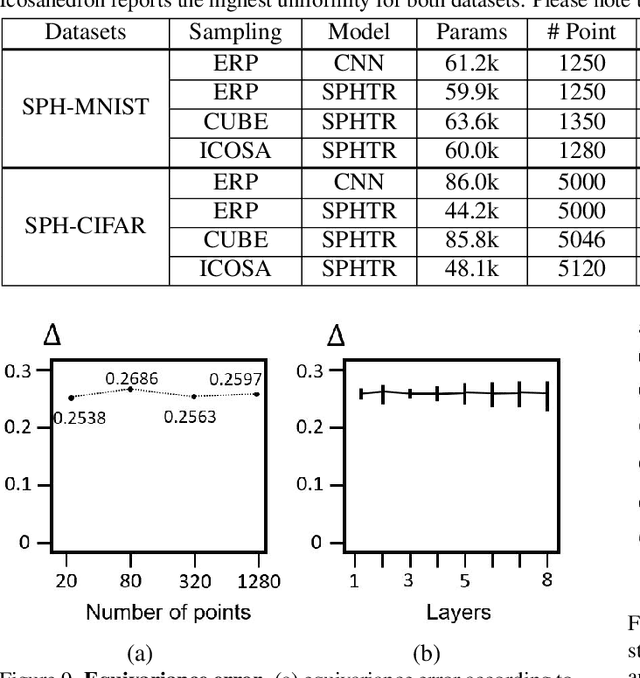
Using convolutional neural networks for 360images can induce sub-optimal performance due to distortions entailed by a planar projection. The distortion gets deteriorated when a rotation is applied to the 360image. Thus, many researches based on convolutions attempt to reduce the distortions to learn accurate representation. In contrast, we leverage the transformer architecture to solve image classification problems for 360images. Using the proposed transformer for 360images has two advantages. First, our method does not require the erroneous planar projection process by sampling pixels from the sphere surface. Second, our sampling method based on regular polyhedrons makes low rotation equivariance errors, because specific rotations can be reduced to permutations of faces. In experiments, we validate our network on two aspects, as follows. First, we show that using a transformer with highly uniform sampling methods can help reduce the distortion. Second, we demonstrate that the transformer architecture can achieve rotation equivariance on specific rotations. We compare our method to other state-of-the-art algorithms using the SPH-MNIST, SPH-CIFAR, and SUN360 datasets and show that our method is competitive with other methods.
Style Transfer with Target Feature Palette and Attention Coloring
Nov 07, 2021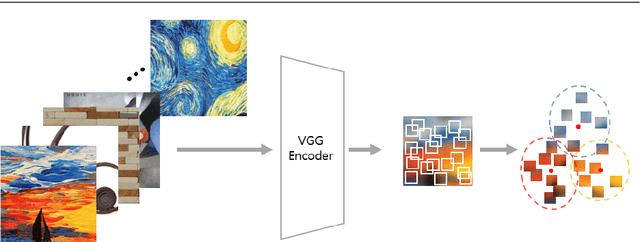
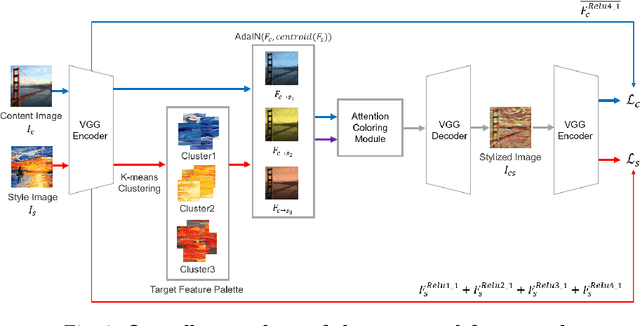
Style transfer has attracted a lot of attentions, as it can change a given image into one with splendid artistic styles while preserving the image structure. However, conventional approaches easily lose image details and tend to produce unpleasant artifacts during style transfer. In this paper, to solve these problems, a novel artistic stylization method with target feature palettes is proposed, which can transfer key features accurately. Specifically, our method contains two modules, namely feature palette composition (FPC) and attention coloring (AC) modules. The FPC module captures representative features based on K-means clustering and produces a feature target palette. The following AC module calculates attention maps between content and style images, and transfers colors and patterns based on the attention map and the target palette. These modules enable the proposed stylization to focus on key features and generate plausibly transferred images. Thus, the contributions of the proposed method are to propose a novel deep learning-based style transfer method and present target feature palette and attention coloring modules, and provide in-depth analysis and insight on the proposed method via exhaustive ablation study. Qualitative and quantitative results show that our stylized images exhibit state-of-the-art performance, with strength in preserving core structures and details of the content image.
DALE : Dark Region-Aware Low-light Image Enhancement
Aug 28, 2020

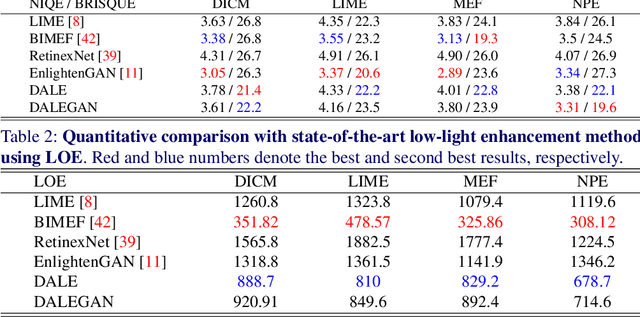

In this paper, we present a novel low-light image enhancement method called dark region-aware low-light image enhancement (DALE), where dark regions are accurately recognized by the proposed visual attention module and their brightness are intensively enhanced. Our method can estimate the visual attention in an efficient manner using super-pixels without any complicated process. Thus, the method can preserve the color, tone, and brightness of original images and prevents normally illuminated areas of the images from being saturated and distorted. Experimental results show that our method accurately identifies dark regions via the proposed visual attention, and qualitatively and quantitatively outperforms state-of-the-art methods.
Visual Tracking by TridentAlign and Context Embedding
Jul 14, 2020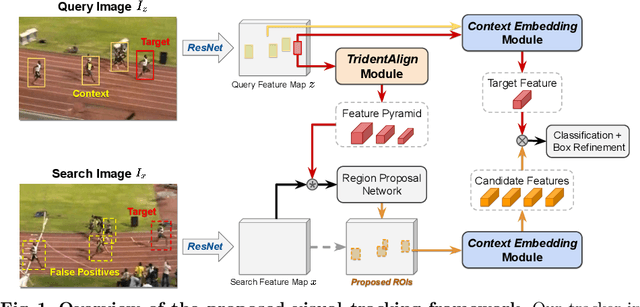
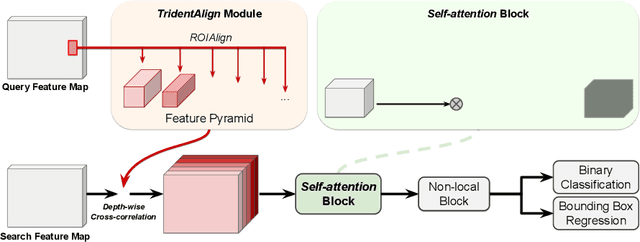

Recent advances in Siamese network-based visual tracking methods have enabled high performance on numerous tracking benchmarks. However, extensive scale variations of the target object and distractor objects with similar categories have consistently posed challenges in visual tracking. To address these persisting issues, we propose novel TridentAlign and context embedding modules for Siamese network-based visual tracking methods. The TridentAlign module facilitates adaptability to extensive scale variations and large deformations of the target, where it pools the feature representation of the target object into multiple spatial dimensions to form a feature pyramid, which is then utilized in the region proposal stage. Meanwhile, context embedding module aims to discriminate the target from distractor objects by accounting for the global context information among objects. The context embedding module extracts and embeds the global context information of a given frame into a local feature representation such that the information can be utilized in the final classification stage. Experimental results obtained on multiple benchmark datasets show that the performance of the proposed tracker is comparable to that of state-of-the-art trackers, while the proposed tracker runs at real-time speed.
Adaptive Regularization via Residual Smoothing in Deep Learning Optimization
Aug 30, 2019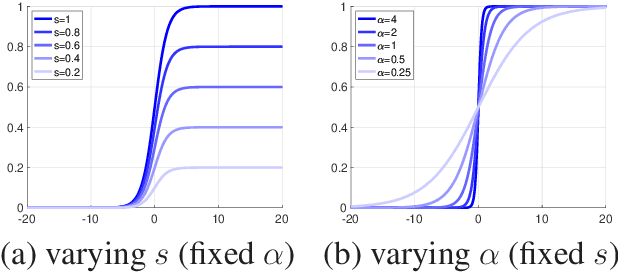

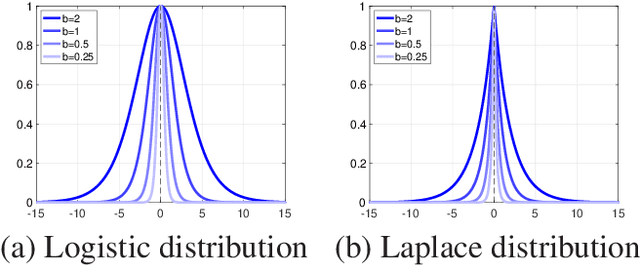
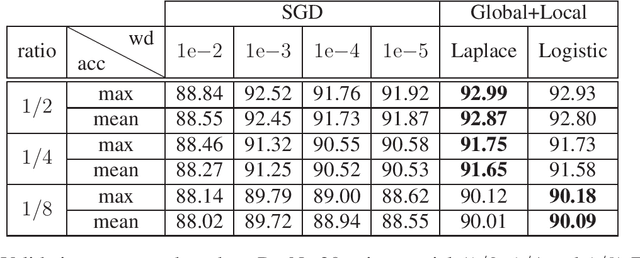
We present an adaptive regularization algorithm that can be effectively applied to the optimization problem in deep learning framework. Our regularization algorithm aims to take into account the fitness of data to the current state of model in the determination of regularity to achieve better generalization. The degree of regularization at each element in the target space of the neural network architecture is determined based on the residual at each optimization iteration in an adaptive way. Our adaptive regularization algorithm is designed to apply a diffusion process driven by the heat equation with spatially varying diffusivity depending on the probability density function following a certain distribution of residual. Our data-driven regularity is imposed by adaptively smoothing a simplified objective function in which the explicit regularization term is omitted in an alternating manner between the evaluation of residual and the determination of the degree of its regularity. The effectiveness of our algorithm is empirically demonstrated by the numerical experiments in the application of image classification problems, indicating that our algorithm outperforms other commonly used optimization algorithms in terms of generalization using popular deep learning models and benchmark datasets.
Deep ensemble network with explicit complementary model for accuracy-balanced classification
Aug 10, 2019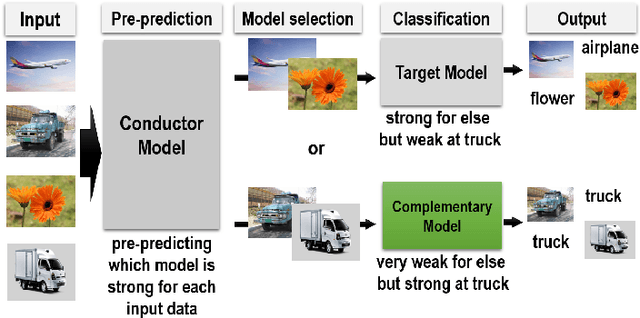
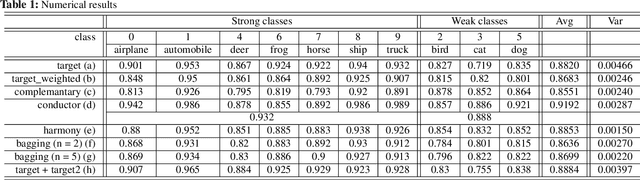
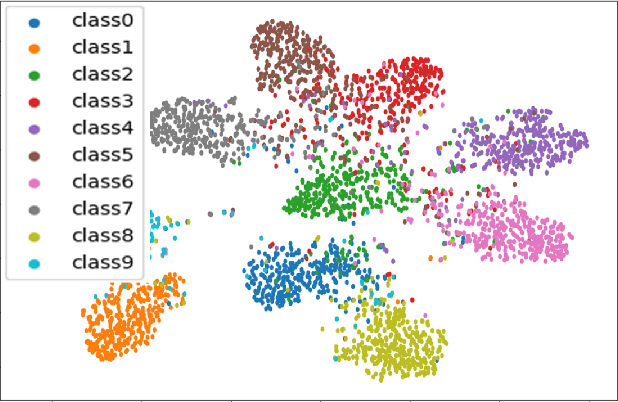
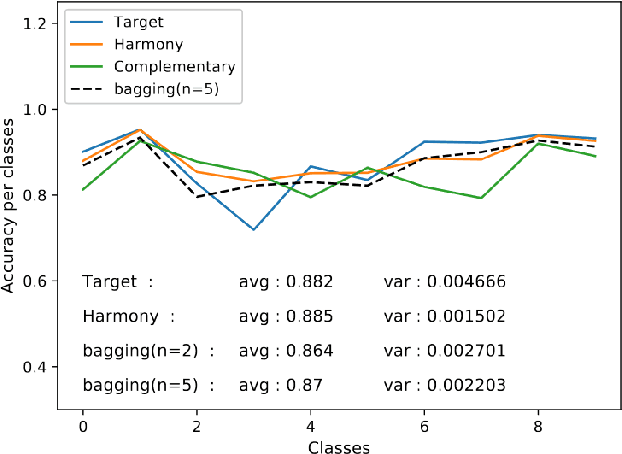
The average accuracy is one of major evaluation metrics for classification systems, while the accuracy deviation is another important performance metric used to evaluate various deep neural networks. In this paper, we present a new ensemble-like fast deep neural network, Harmony, that can reduce the accuracy deviation among categories without degrading overall average accuracy. Harmony consists of three sub-models, namely, Target model, Complementary model, and Conductor model. In Harmony, an object is classified by using either Target model or Complementary model. Target model is a conventional classification network for general categories, while Complementary model is a classification network especially for weak categories that are inaccurately classified by Target model. Conductor model is used to select one of two models. Experimental results demonstrate that Harmony accurately classifies categories, while it reduces the accuracy deviation among the categories.
LED2Net: Deep Illumination-aware Dehazing with Low-light and Detail Enhancement
Jul 26, 2019

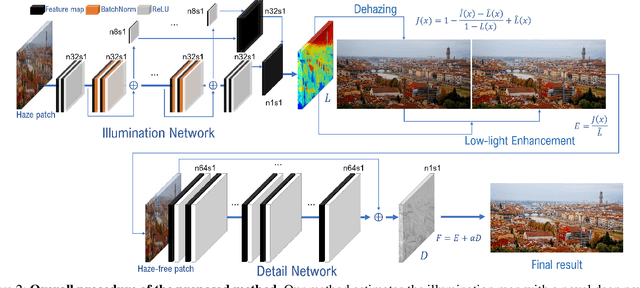

We present a novel dehazing and low-light enhancement method based on an illumination map that is accurately estimated by a convolutional neural network (CNN). In this paper, the illumination map is used as a component for three different tasks, namely, atmospheric light estimation, transmission map estimation, and low-light enhancement. To train CNNs for dehazing and low-light enhancement simultaneously based on the retinex theory, we synthesize numerous low-light and hazy images from normal hazy images from the FADE data set. In addition, we further improve the network using detail enhancement. Experimental results demonstrate that our method surpasses recent state-of-theart algorithms quantitatively and qualitatively. In particular, our haze-free images present vivid colors and enhance visibility without a halo effect or color distortion.
3D Point Cloud Generative Adversarial Network Based on Tree Structured Graph Convolutions
May 16, 2019
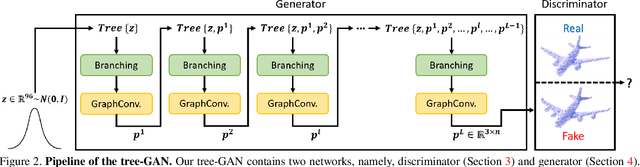

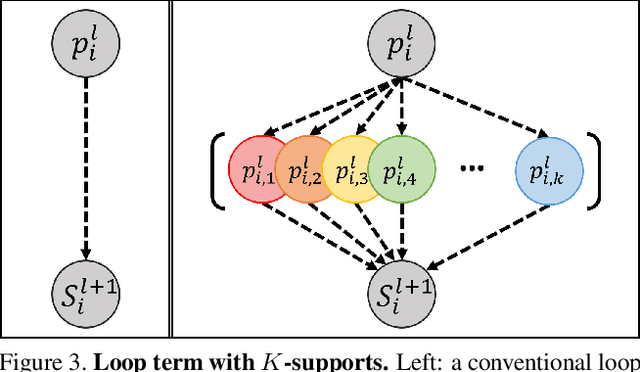
In this paper, we propose a novel generative adversarial network (GAN) for 3D point clouds generation, which is called tree-GAN. To achieve state-of-the-art performance for multi-class 3D point cloud generation, a tree-structured graph convolution network (TreeGCN) is introduced as a generator for tree-GAN. Because TreeGCN performs graph convolutions within a tree, it can use ancestor information to boost the representation power for features. To evaluate GANs for 3D point clouds accurately, we develop a novel evaluation metric called Frechet point cloud distance (FPD). Experimental results demonstrate that the proposed tree-GAN outperforms state-of-the-art GANs in terms of both conventional metrics and FPD, and can generate point clouds for different semantic parts without prior knowledge.