 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliability Across Parametric and External Knowledge: Understanding Knowledge Handling in LLMs
Feb 19, 2025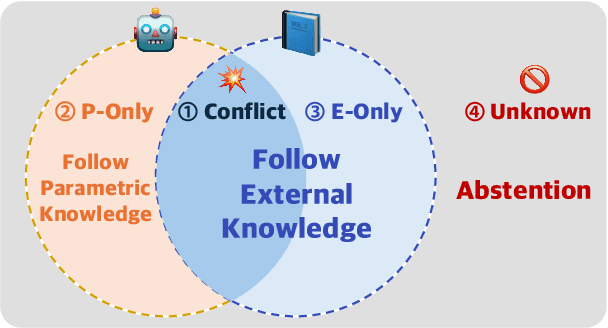
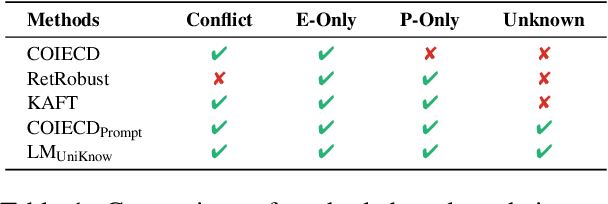
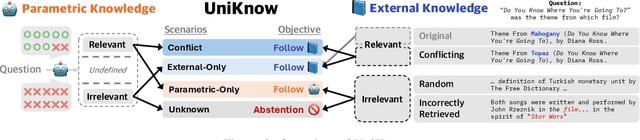
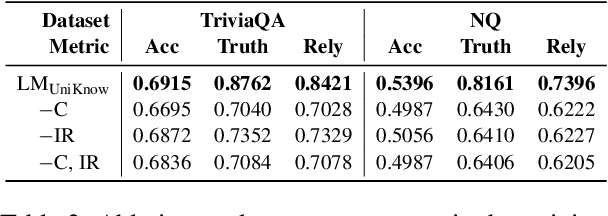
Large Language Models (LLMs) enhance their problem-solving capability by leveraging both parametric and external knowledge. Beyond leveraging external knowledge to improve response accuracy, they require key capabilities for reliable knowledge-handling: resolving conflicts between knowledge sources, avoiding distraction from uninformative external knowledge, and abstaining when sufficient knowledge is unavailable. Prior studies have examined these scenarios in isolation or with limited scope. To systematically evaluate these capabilities, we introduce a comprehensive framework for analyzing knowledge-handling based on two key dimensions: the presence of parametric knowledge and the informativeness of external knowledge. Through analysis, we identify biases in knowledge utilization and examine how the ability to handle one scenario impacts performance in others. Furthermore, we demonstrate that training on data constructed based on the knowledge-handling scenarios improves LLMs' reliability in integrating and utilizing knowledge.
When to Speak, When to Abstain: Contrastive Decoding with Abstention
Dec 17, 2024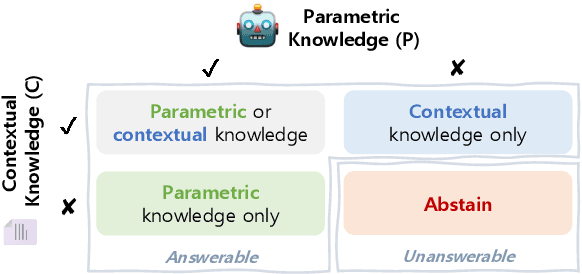
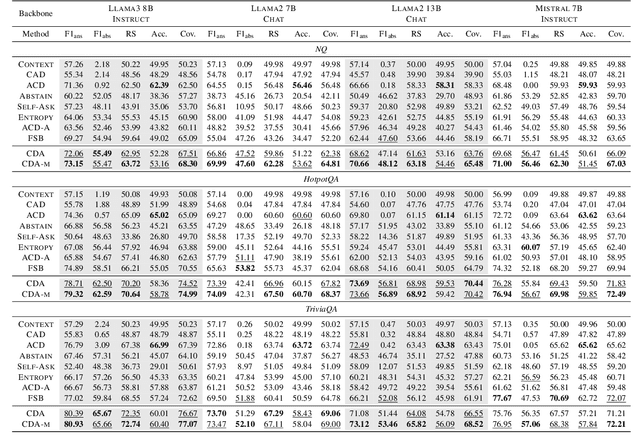
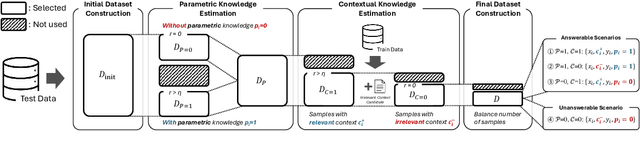
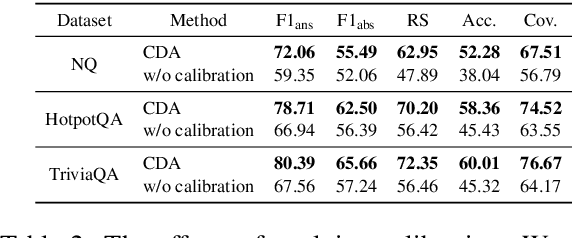
Large Language Models (LLMs) demonstrate exceptional performance across diverse tasks by leveraging both pre-trained knowledge (i.e., parametric knowledge) and external knowledge (i.e., contextual knowledge). While substantial efforts have been made to leverage both forms of knowledge, scenarios in which the model lacks any relevant knowledge remain underexplored. Such limitations can result in issues like hallucination, causing reduced reliability and potential risks in high-stakes applications. To address such limitations, this paper extends the task scope to encompass cases where the user's request cannot be fulfilled due to the lack of relevant knowledge. To this end, we introduce Contrastive Decoding with Abstention (CDA), a training-free decoding method that empowers LLMs to generate responses when relevant knowledge is available and to abstain otherwise. CDA evaluates the relevance of each knowledge for a given query, adaptively determining which knowledge to prioritize or which to completely ignore. Extensive experiments with four LLMs on three question-answering datasets demonstrate that CDA can effectively perform accurate generation and abstention simultaneously. These findings highlight CDA's potential to broaden the applicability of LLMs, enhancing reliability and preserving user trust.
Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts
Aug 02, 2024When using large language models (LLMs) in knowledge-intensive tasks, such as open-domain question answering, external context can bridge a gap between external knowledge and LLM's parametric knowledge. Recent research has been developed to amplify contextual knowledge over the parametric knowledge of LLM with contrastive decoding approaches. While these approaches could yield truthful responses when relevant context is provided, they are prone to vulnerabilities when faced with noisy contexts. We extend the scope of previous studies to encompass noisy contexts and propose adaptive contrastive decoding (ACD) to leverage contextual influence effectively. ACD demonstrates improvements in open-domain question answering tasks compared to baselines, especially in robustness by remaining undistracted by noisy contexts in retrieval-augmented generation.
Investigating the Influence of Prompt-Specific Shortcuts in AI Generated Text Detection
Jun 24, 2024



AI Generated Text (AIGT) detectors are developed with texts from humans and LLMs of common tasks. Despite the diversity of plausible prompt choices, these datasets are generally constructed with a limited number of prompts. The lack of prompt variation can introduce prompt-specific shortcut features that exist in data collected with the chosen prompt, but do not generalize to others. In this paper, we analyze the impact of such shortcuts in AIGT detection. We propose Feedback-based Adversarial Instruction List Optimization (FAILOpt), an attack that searches for instructions deceptive to AIGT detectors exploiting prompt-specific shortcuts. FAILOpt effectively drops the detection performance of the target detector, comparable to other attacks based on adversarial in-context examples. We also utilize our method to enhance the robustness of the detector by mitigating the shortcuts. Based on the findings, we further train the classifier with the dataset augmented by FAILOpt prompt. The augmented classifier exhibits improvements across generation models, tasks, and attacks. Our code will be available at https://github.com/zxcvvxcz/FAILOpt.
Aligning Language Models to Explicitly Handle Ambiguity
Apr 18, 2024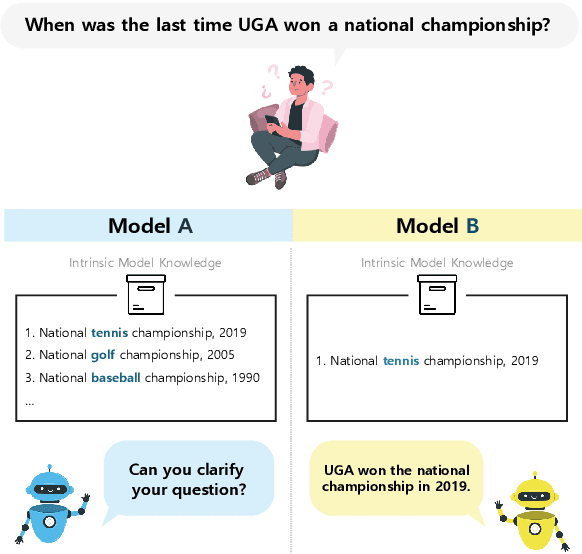
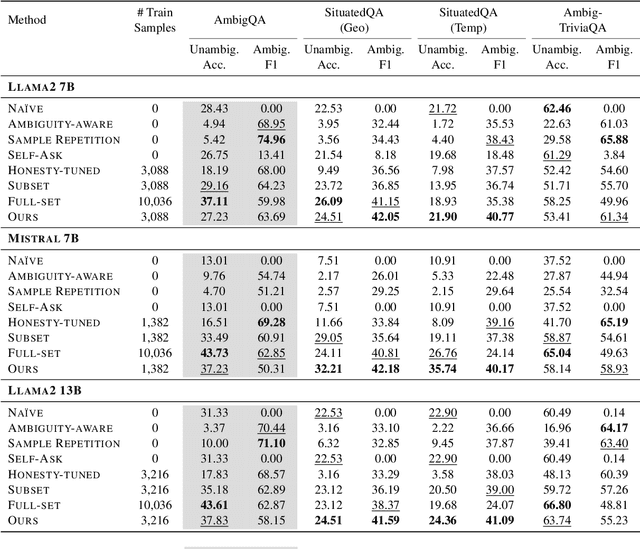
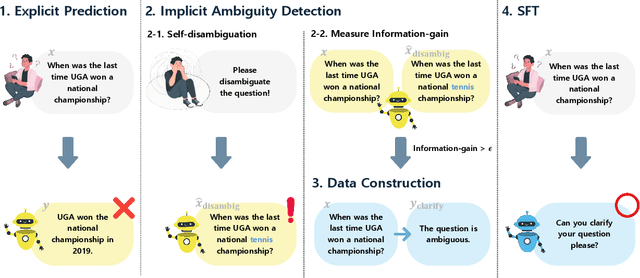
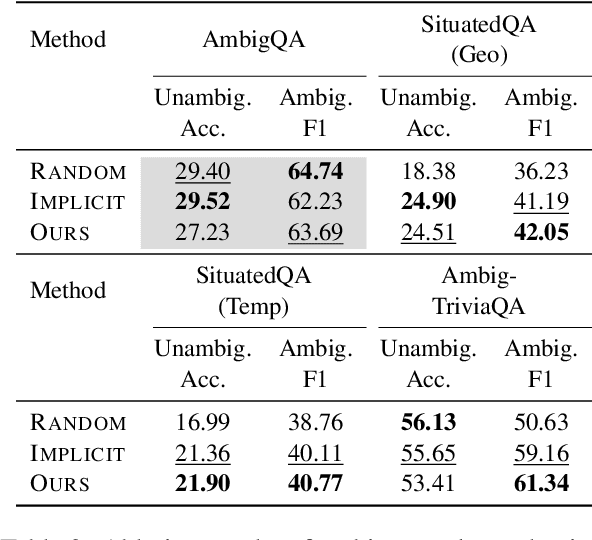
In spoken languages, utterances are often shaped to be incomplete or vague for efficiency. This can lead to varying interpretations of the same input, based on different assumptions about the context. To ensure reliable user-model interactions in such scenarios, it is crucial for models to adeptly handle the inherent ambiguity in user queries. However, conversational agents built upon even the most recent large language models (LLMs) face challenges in processing ambiguous inputs, primarily due to the following two hurdles: (1) LLMs are not directly trained to handle inputs that are too ambiguous to be properly managed; (2) the degree of ambiguity in an input can vary according to the intrinsic knowledge of the LLMs, which is difficult to investigate. To address these issues, this paper proposes a method to align LLMs to explicitly handle ambiguous inputs. Specifically, we introduce a proxy task that guides LLMs to utilize their intrinsic knowledge to self-disambiguate a given input. We quantify the information gain from the disambiguation procedure as a measure of the extent to which the models perceive their inputs as ambiguous. This measure serves as a cue for selecting samples deemed ambiguous from the models' perspectives, which are then utilized for alignment. Experimental results from several question-answering datasets demonstrate that the LLMs fine-tuned with our approach are capable of handling ambiguous inputs while still performing competitively on clear questions within the task.
Universal Domain Adaptation for Robust Handling of Distributional Shifts in NLP
Oct 23, 2023When deploying machine learning systems to the wild, it is highly desirable for them to effectively leverage prior knowledge to the unfamiliar domain while also firing alarms to anomalous inputs. In order to address these requirements, Universal Domain Adaptation (UniDA) has emerged as a novel research area in computer vision, focusing on achieving both adaptation ability and robustness (i.e., the ability to detect out-of-distribution samples). While UniDA has led significant progress in computer vision, its application on language input still needs to be explored despite its feasibility. In this paper, we propose a comprehensive benchmark for natural language that offers thorough viewpoints of the model's generalizability and robustness. Our benchmark encompasses multiple datasets with varying difficulty levels and characteristics, including temporal shifts and diverse domains. On top of our testbed, we validate existing UniDA methods from computer vision and state-of-the-art domain adaptation techniques from NLP literature, yielding valuable findings: We observe that UniDA methods originally designed for image input can be effectively transferred to the natural language domain while also underscoring the effect of adaptation difficulty in determining the model's performance.
Probing Out-of-Distribution Robustness of Language Models with Parameter-Efficient Transfer Learning
Jan 30, 2023
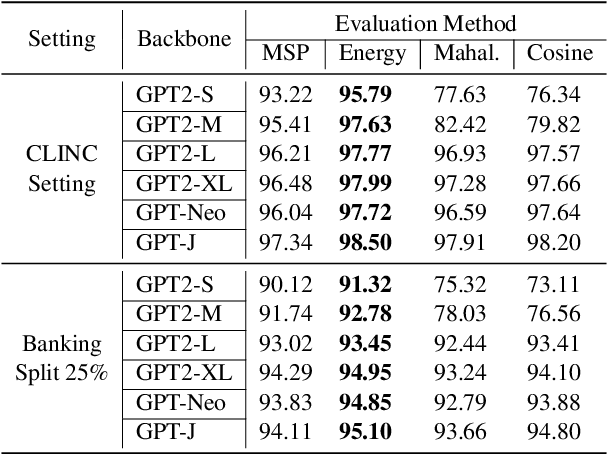


As the size of the pre-trained language model (PLM) continues to increase, numerous parameter-efficient transfer learning methods have been proposed recently to compensate for the tremendous cost of fine-tuning. Despite the impressive results achieved by large pre-trained language models (PLMs) and various parameter-efficient transfer learning (PETL) methods on sundry benchmarks, it remains unclear if they can handle inputs that have been distributionally shifted effectively. In this study, we systematically explore how the ability to detect out-of-distribution (OOD) changes as the size of the PLM grows or the transfer methods are altered. Specifically, we evaluated various PETL techniques, including fine-tuning, Adapter, LoRA, and prefix-tuning, on three different intention classification tasks, each utilizing various language models with different scales.
Prompt-Augmented Linear Probing: Scaling Beyond The Limit of Few-shot In-Context Learners
Dec 28, 2022Through in-context learning (ICL), large-scale language models are effective few-shot learners without additional model fine-tuning. However, the ICL performance does not scale well with the number of available training samples as it is limited by the inherent input length constraint of the underlying language model. Meanwhile, many studies have revealed that language models are also powerful feature extractors, allowing them to be utilized in a black-box manner and enabling the linear probing paradigm, where lightweight discriminators are trained on top of the pre-extracted input representations. This paper proposes prompt-augmented linear probing (PALP), a hybrid of linear probing and ICL, which leverages the best of both worlds. PALP inherits the scalability of linear probing and the capability of enforcing language models to derive more meaningful representations via tailoring input into a more conceivable form. Throughout in-depth investigations on various datasets, we verified that PALP significantly enhances the input representations closing the gap between ICL in the data-hungry scenario and fine-tuning in the data-abundant scenario with little training overhead, potentially making PALP a strong alternative in a black-box scenario.
Self-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator
Jun 16, 2022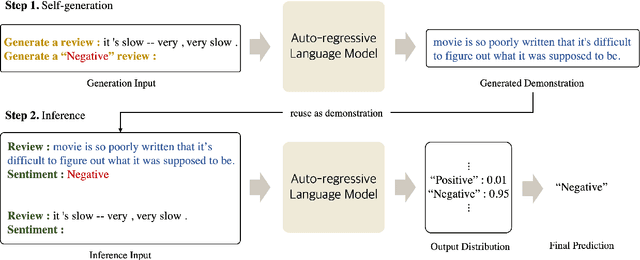
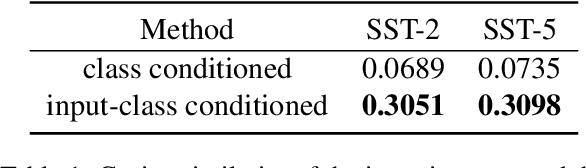

Large-scale pre-trained language models (PLMs) are well-known for being capable of solving a task simply by conditioning a few input-label pairs dubbed demonstrations on a prompt without being explicitly tuned for the desired downstream task. Such a process (i.e., in-context learning), however, naturally leads to high reliance on the demonstrations which are usually selected from external datasets. In this paper, we propose self-generated in-context learning (SG-ICL), which generates demonstrations for in-context learning from PLM itself to minimize the reliance on the external demonstration. We conduct experiments on four different text classification tasks and show SG-ICL significantly outperforms zero-shot learning and is generally worth approximately 0.6 gold training samples. Moreover, our generated demonstrations show more consistent performance with low variance compared to randomly selected demonstrations from the training dataset.
Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations
May 25, 2022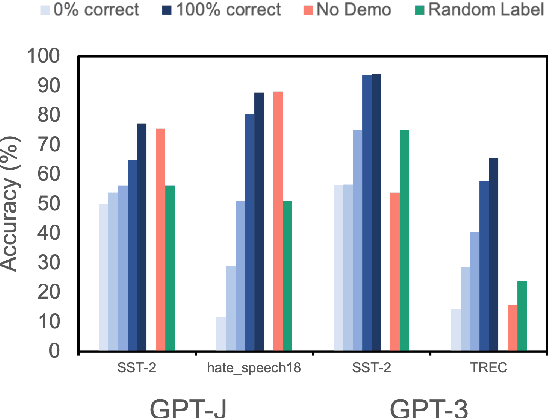
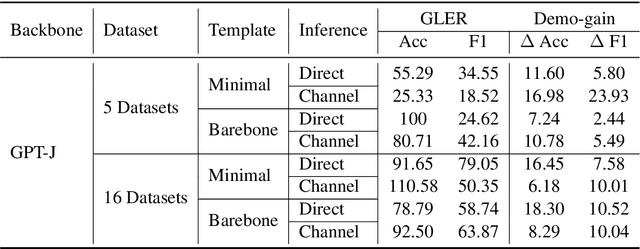
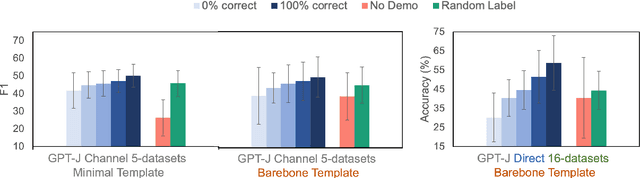
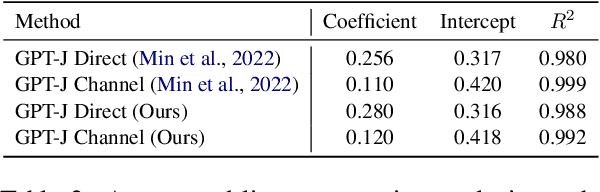
Despite recent explosion in research interests, in-context learning and the precise impact of the quality of demonstrations remain elusive. While, based on current literature, it is expected that in-context learning shares a similar mechanism to supervised learning, Min et al. (2022) recently reported that, surprisingly, input-label correspondence is less important than other aspects of prompt demonstrations. Inspired by this counter-intuitive observation, we re-examine the importance of ground truth labels on in-context learning from diverse and statistical points of view. With the aid of the newly introduced metrics, i.e., Ground-truth Label Effect Ratio (GLER), demo-gain, and label sensitivity, we find that the impact of the correct input-label matching can vary according to different configurations. Expanding upon the previous key finding on the role of demonstrations, the complementary and contrastive results suggest that one might need to take more care when estimating the impact of each component in in-context learning demonstrations.