 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator
Paper and Code
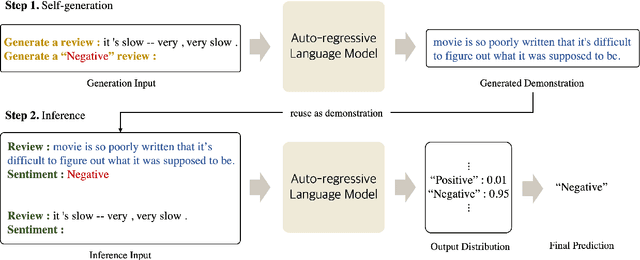
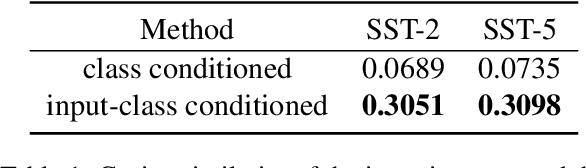

Large-scale pre-trained language models (PLMs) are well-known for being capable of solving a task simply by conditioning a few input-label pairs dubbed demonstrations on a prompt without being explicitly tuned for the desired downstream task. Such a process (i.e., in-context learning), however, naturally leads to high reliance on the demonstrations which are usually selected from external datasets. In this paper, we propose self-generated in-context learning (SG-ICL), which generates demonstrations for in-context learning from PLM itself to minimize the reliance on the external demonstration. We conduct experiments on four different text classification tasks and show SG-ICL significantly outperforms zero-shot learning and is generally worth approximately 0.6 gold training samples. Moreover, our generated demonstrations show more consistent performance with low variance compared to randomly selected demonstrations from the training dataset.