 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAST-GOAL: Fast and Efficient Global-local Object Alignment Learning
May 26, 2026Vision-language models such as CLIP have shown impressive capabilities in aligning images and text, but they often struggle with lengthy and detailed text descriptions due to pre-training on short and concise captions. We present FAST-GOAL (Fast and Efficient Global-local Object Alignment Learning), an efficient fine-tuning method that enhances ability of CLIP to handle lengthy text through global-local semantic alignment. Our method consists of two key components. First, Fast Local Image-Sentence Matching (FLISM) efficiently extracts local image regions through object detection and spatial division, then matches them with corresponding sentences. Second, Token Similarity-based Learning (TSL) maximizes the similarity between patch tokens from specific regions in the image and their corresponding region embeddings, applying the same principle to text, which enhances the ability of the model to capture detailed correspondences. Additionally, we introduce GLIT100k, a dataset that provides both global image-lengthy caption pairs and context-derived local pairs, where local descriptions are extracted from global captions to maintain semantic coherence. Through extensive experiments on long caption datasets (DOCCI, DCI) and short caption datasets (MSCOCO, Flickr30k), we demonstrate that FAST-GOAL achieves significant improvements over baselines, enabling effective adaptation of CLIP to detailed textual descriptions while maintaining computational efficiency.
CoVA: Text-Guided Composed Video Retrieval for Audio-Visual Content
Jan 30, 2026Composed Video Retrieval (CoVR) aims to retrieve a target video from a large gallery using a reference video and a textual query specifying visual modifications. However, existing benchmarks consider only visual changes, ignoring videos that differ in audio despite visual similarity. To address this limitation, we introduce Composed retrieval for Video with its Audio CoVA, a new retrieval task that accounts for both visual and auditory variations. To support this, we construct AV-Comp, a benchmark consisting of video pairs with cross-modal changes and corresponding textual queries that describe the differences. We also propose AVT Compositional Fusion (AVT), which integrates video, audio, and text features by selectively aligning the query to the most relevant modality. AVT outperforms traditional unimodal fusion and serves as a strong baseline for CoVA. Examples from the proposed dataset, including both visual and auditory information, are available at https://perceptualai-lab.github.io/CoVA/.
Disentangled Concept Representation for Text-to-image Person Re-identification
Jan 15, 2026Text-to-image person re-identification (TIReID) aims to retrieve person images from a large gallery given free-form textual descriptions. TIReID is challenging due to the substantial modality gap between visual appearances and textual expressions, as well as the need to model fine-grained correspondences that distinguish individuals with similar attributes such as clothing color, texture, or outfit style. To address these issues, we propose DiCo (Disentangled Concept Representation), a novel framework that achieves hierarchical and disentangled cross-modal alignment. DiCo introduces a shared slot-based representation, where each slot acts as a part-level anchor across modalities and is further decomposed into multiple concept blocks. This design enables the disentanglement of complementary attributes (\textit{e.g.}, color, texture, shape) while maintaining consistent part-level correspondence between image and text. Extensive experiments on CUHK-PEDES, ICFG-PEDES, and RSTPReid demonstrate that our framework achieves competitive performance with state-of-the-art methods, while also enhancing interpretability through explicit slot- and block-level representations for more fine-grained retrieval results.
Leveraging Prior Knowledge of Diffusion Model for Person Search
Oct 02, 2025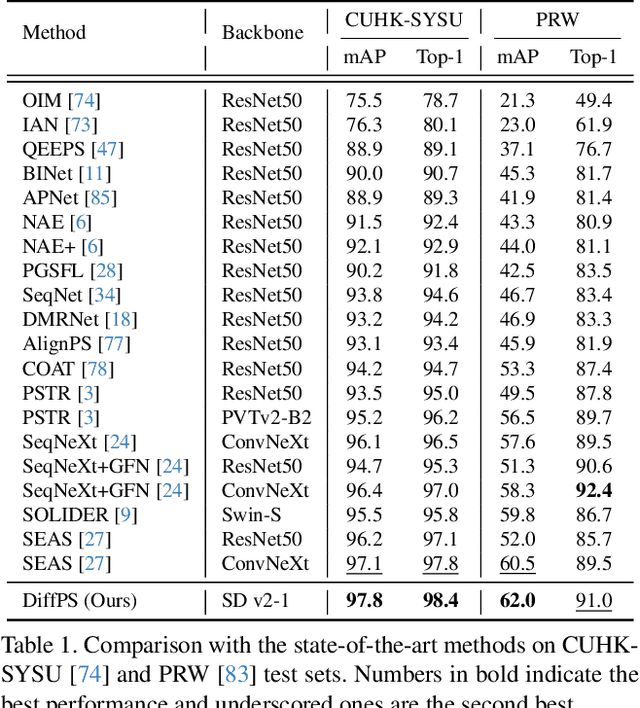

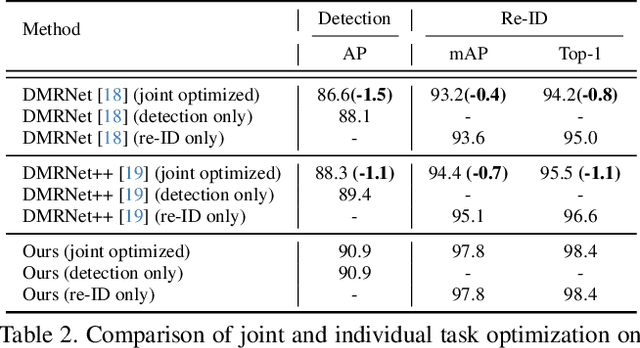

Person search aims to jointly perform person detection and re-identification by localizing and identifying a query person within a gallery of uncropped scene images. Existing methods predominantly utilize ImageNet pre-trained backbones, which may be suboptimal for capturing the complex spatial context and fine-grained identity cues necessary for person search. Moreover, they rely on a shared backbone feature for both person detection and re-identification, leading to suboptimal features due to conflicting optimization objectives. In this paper, we propose DiffPS (Diffusion Prior Knowledge for Person Search), a novel framework that leverages a pre-trained diffusion model while eliminating the optimization conflict between two sub-tasks. We analyze key properties of diffusion priors and propose three specialized modules: (i) Diffusion-Guided Region Proposal Network (DGRPN) for enhanced person localization, (ii) Multi-Scale Frequency Refinement Network (MSFRN) to mitigate shape bias, and (iii) Semantic-Adaptive Feature Aggregation Network (SFAN) to leverage text-aligned diffusion features. DiffPS sets a new state-of-the-art on CUHK-SYSU and PRW.
Visual Representation Alignment for Multimodal Large Language Models
Sep 09, 2025Multimodal large language models (MLLMs) trained with visual instruction tuning have achieved strong performance across diverse tasks, yet they remain limited in vision-centric tasks such as object counting or spatial reasoning. We attribute this gap to the prevailing text-only supervision paradigm, which provides only indirect guidance for the visual pathway and often leads MLLMs to discard fine-grained visual details during training. In this paper, we present VIsual Representation ALignment (VIRAL), a simple yet effective regularization strategy that aligns the internal visual representations of MLLMs with those of pre-trained vision foundation models (VFMs). By explicitly enforcing this alignment, VIRAL enables the model not only to retain critical visual details from the input vision encoder but also to complement additional visual knowledge from VFMs, thereby enhancing its ability to reason over complex visual inputs. Our experiments demonstrate consistent improvements across all tasks on widely adopted multimodal benchmarks. Furthermore, we conduct comprehensive ablation studies to validate the key design choices underlying our framework. We believe this simple finding opens up an important direction for the effective integration of visual information in training MLLMs.
MoCHA-former: Moiré-Conditioned Hybrid Adaptive Transformer for Video Demoiréing
Aug 21, 2025Recent advances in portable imaging have made camera-based screen capture ubiquitous. Unfortunately, frequency aliasing between the camera's color filter array (CFA) and the display's sub-pixels induces moir\'e patterns that severely degrade captured photos and videos. Although various demoir\'eing models have been proposed to remove such moir\'e patterns, these approaches still suffer from several limitations: (i) spatially varying artifact strength within a frame, (ii) large-scale and globally spreading structures, (iii) channel-dependent statistics and (iv) rapid temporal fluctuations across frames. We address these issues with the Moir\'e Conditioned Hybrid Adaptive Transformer (MoCHA-former), which comprises two key components: Decoupled Moir\'e Adaptive Demoir\'eing (DMAD) and Spatio-Temporal Adaptive Demoir\'eing (STAD). DMAD separates moir\'e and content via a Moir\'e Decoupling Block (MDB) and a Detail Decoupling Block (DDB), then produces moir\'e-adaptive features using a Moir\'e Conditioning Block (MCB) for targeted restoration. STAD introduces a Spatial Fusion Block (SFB) with window attention to capture large-scale structures, and a Feature Channel Attention (FCA) to model channel dependence in RAW frames. To ensure temporal consistency, MoCHA-former performs implicit frame alignment without any explicit alignment module. We analyze moir\'e characteristics through qualitative and quantitative studies, and evaluate on two video datasets covering RAW and sRGB domains. MoCHA-former consistently surpasses prior methods across PSNR, SSIM, and LPIPS.
Domain Generalization for Person Re-identification: A Survey Towards Domain-Agnostic Person Matching
Jun 14, 2025Person Re-identification (ReID) aims to retrieve images of the same individual captured across non-overlapping camera views, making it a critical component of intelligent surveillance systems. Traditional ReID methods assume that the training and test domains share similar characteristics and primarily focus on learning discriminative features within a given domain. However, they often fail to generalize to unseen domains due to domain shifts caused by variations in viewpoint, background, and lighting conditions. To address this issue, Domain-Adaptive ReID (DA-ReID) methods have been proposed. These approaches incorporate unlabeled target domain data during training and improve performance by aligning feature distributions between source and target domains. Domain-Generalizable ReID (DG-ReID) tackles a more realistic and challenging setting by aiming to learn domain-invariant features without relying on any target domain data. Recent methods have explored various strategies to enhance generalization across diverse environments, but the field remains relatively underexplored. In this paper, we present a comprehensive survey of DG-ReID. We first review the architectural components of DG-ReID including the overall setting, commonly used backbone networks and multi-source input configurations. Then, we categorize and analyze domain generalization modules that explicitly aim to learn domain-invariant and identity-discriminative representations. To examine the broader applicability of these techniques, we further conduct a case study on a related task that also involves distribution shifts. Finally, we discuss recent trends, open challenges, and promising directions for future research in DG-ReID. To the best of our knowledge, this is the first systematic survey dedicated to DG-ReID.
Subnet-Aware Dynamic Supernet Training for Neural Architecture Search
Mar 13, 2025N-shot neural architecture search (NAS) exploits a supernet containing all candidate subnets for a given search space. The subnets are typically trained with a static training strategy (e.g., using the same learning rate (LR) scheduler and optimizer for all subnets). This, however, does not consider that individual subnets have distinct characteristics, leading to two problems: (1) The supernet training is biased towards the low-complexity subnets (unfairness); (2) the momentum update in the supernet is noisy (noisy momentum). We present a dynamic supernet training technique to address these problems by adjusting the training strategy adaptive to the subnets. Specifically, we introduce a complexity-aware LR scheduler (CaLR) that controls the decay ratio of LR adaptive to the complexities of subnets, which alleviates the unfairness problem. We also present a momentum separation technique (MS). It groups the subnets with similar structural characteristics and uses a separate momentum for each group, avoiding the noisy momentum problem. Our approach can be applicable to various N-shot NAS methods with marginal cost, while improving the search performance drastically. We validate the effectiveness of our approach on various search spaces (e.g., NAS-Bench-201, Mobilenet spaces) and datasets (e.g., CIFAR-10/100, ImageNet).
Cerberus: Attribute-based person re-identification using semantic IDs
Dec 02, 2024We introduce a new framework, dubbed Cerberus, for attribute-based person re-identification (reID). Our approach leverages person attribute labels to learn local and global person representations that encode specific traits, such as gender and clothing style. To achieve this, we define semantic IDs (SIDs) by combining attribute labels, and use a semantic guidance loss to align the person representations with the prototypical features of corresponding SIDs, encouraging the representations to encode the relevant semantics. Simultaneously, we enforce the representations of the same person to be embedded closely, enabling recognizing subtle differences in appearance to discriminate persons sharing the same attribute labels. To increase the generalization ability on unseen data, we also propose a regularization method that takes advantage of the relationships between SID prototypes. Our framework performs individual comparisons of local and global person representations between query and gallery images for attribute-based reID. By exploiting the SID prototypes aligned with the corresponding representations, it can also perform person attribute recognition (PAR) and attribute-based person search (APS) without bells and whistles. Experimental results on standard benchmarks on attribute-based person reID, Market-1501 and DukeMTMC, demonstrate the superiority of our model compared to the state of the art.
Disentangled Representations for Short-Term and Long-Term Person Re-Identification
Sep 09, 2024
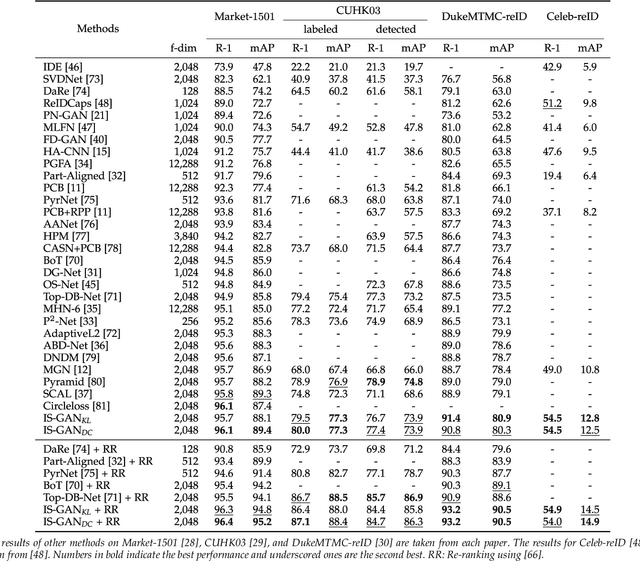

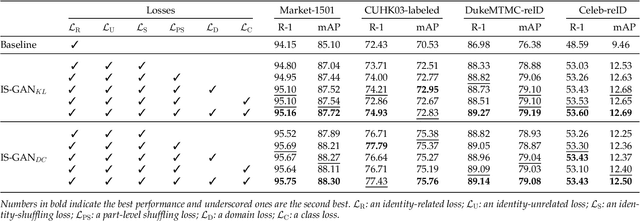
We address the problem of person re-identification (reID), that is, retrieving person images from a large dataset, given a query image of the person of interest. A key challenge is to learn person representations robust to intra-class variations, as different persons could have the same attribute, and persons' appearances look different, e.g., with viewpoint changes. Recent reID methods focus on learning person features discriminative only for a particular factor of variations (e.g., human pose), which also requires corresponding supervisory signals (e.g., pose annotations). To tackle this problem, we propose to factorize person images into identity-related and unrelated features. Identity-related features contain information useful for specifying a particular person (e.g., clothing), while identity-unrelated ones hold other factors (e.g., human pose). To this end, we propose a new generative adversarial network, dubbed identity shuffle GAN (IS-GAN). It disentangles identity-related and unrelated features from person images through an identity-shuffling technique that exploits identification labels alone without any auxiliary supervisory signals. We restrict the distribution of identity-unrelated features or encourage the identity-related and unrelated features to be uncorrelated, facilitating the disentanglement process. Experimental results validate the effectiveness of IS-GAN, showing state-of-the-art performance on standard reID benchmarks, including Market-1501, CUHK03, and DukeMTMC-reID. We further demonstrate the advantages of disentangling person representations on a long-term reID task, setting a new state of the art on a Celeb-reID dataset.
* arXiv admin note: substantial text overlap with arXiv:1910.12003