 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning by Aligning: Visible-Infrared Person Re-identification using Cross-Modal Correspondences
Aug 17, 2021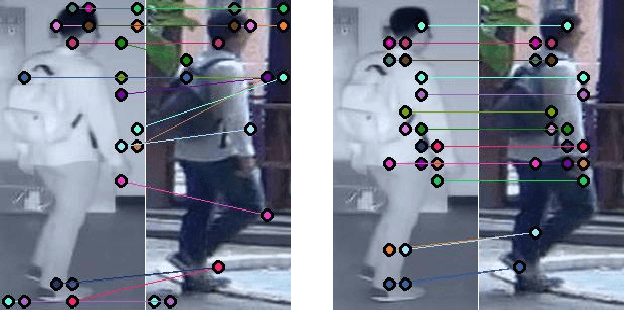
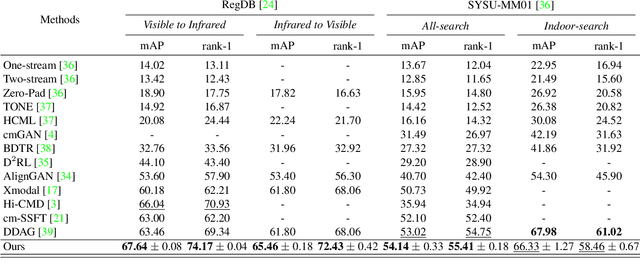
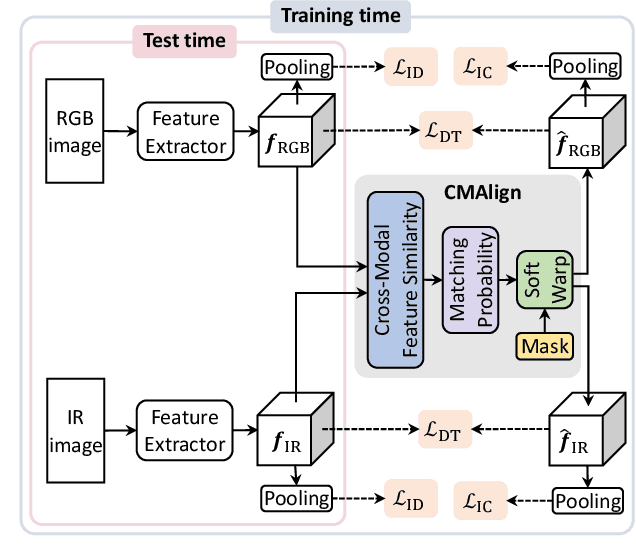
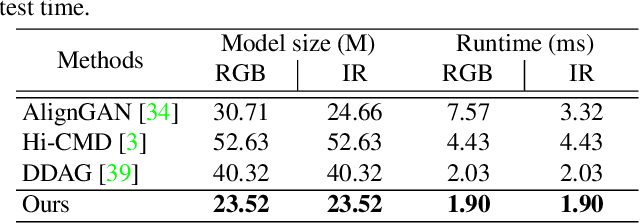
We address the problem of visible-infrared person re-identification (VI-reID), that is, retrieving a set of person images, captured by visible or infrared cameras, in a cross-modal setting. Two main challenges in VI-reID are intra-class variations across person images, and cross-modal discrepancies between visible and infrared images. Assuming that the person images are roughly aligned, previous approaches attempt to learn coarse image- or rigid part-level person representations that are discriminative and generalizable across different modalities. However, the person images, typically cropped by off-the-shelf object detectors, are not necessarily well-aligned, which distract discriminative person representation learning. In this paper, we introduce a novel feature learning framework that addresses these problems in a unified way. To this end, we propose to exploit dense correspondences between cross-modal person images. This allows to address the cross-modal discrepancies in a pixel-level, suppressing modality-related features from person representations more effectively. This also encourages pixel-wise associations between cross-modal local features, further facilitating discriminative feature learning for VI-reID. Extensive experiments and analyses on standard VI-reID benchmarks demonstrate the effectiveness of our approach, which significantly outperforms the state of the art.
Learning Memory-guided Normality for Anomaly Detection
Mar 30, 2020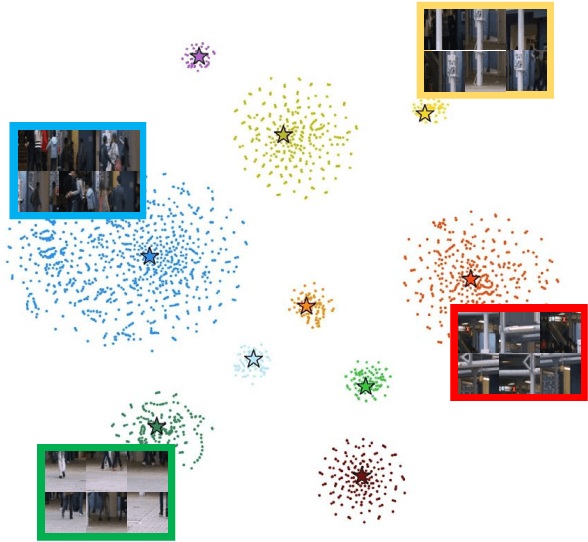
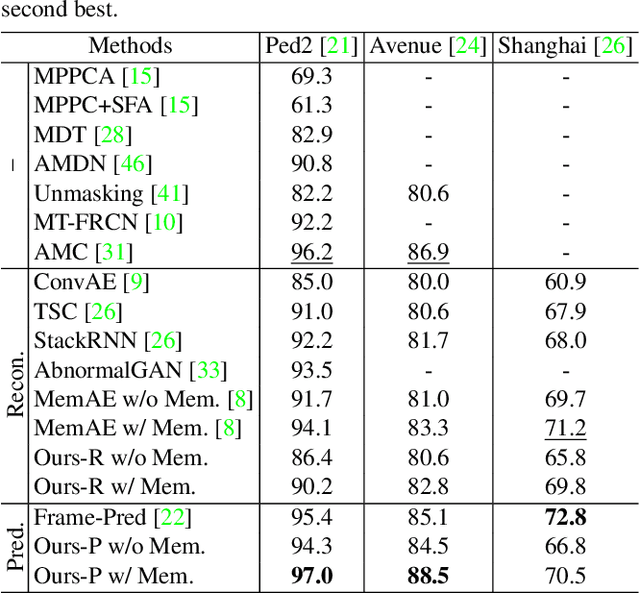


We address the problem of anomaly detection, that is, detecting anomalous events in a video sequence. Anomaly detection methods based on convolutional neural networks (CNNs) typically leverage proxy tasks, such as reconstructing input video frames, to learn models describing normality without seeing anomalous samples at training time, and quantify the extent of abnormalities using the reconstruction error at test time. The main drawbacks of these approaches are that they do not consider the diversity of normal patterns explicitly, and the powerful representation capacity of CNNs allows to reconstruct abnormal video frames. To address this problem, we present an unsupervised learning approach to anomaly detection that considers the diversity of normal patterns explicitly, while lessening the representation capacity of CNNs. To this end, we propose to use a memory module with a new update scheme where items in the memory record prototypical patterns of normal data. We also present novel feature compactness and separateness losses to train the memory, boosting the discriminative power of both memory items and deeply learned features from normal data. Experimental results on standard benchmarks demonstrate the effectiveness and efficiency of our approach, which outperforms the state of the art.
Relation Network for Person Re-identification
Nov 25, 2019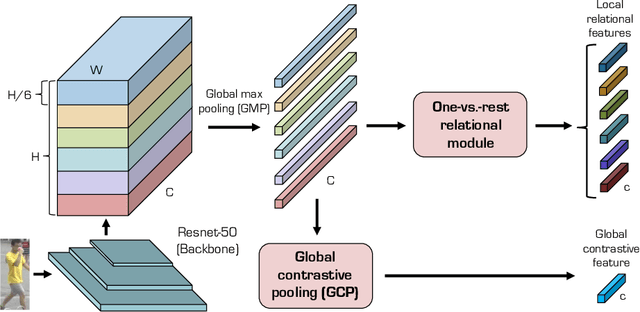
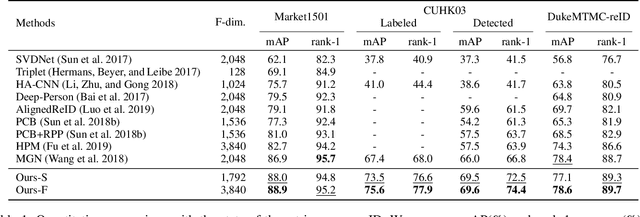
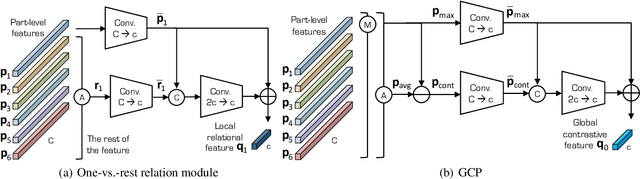
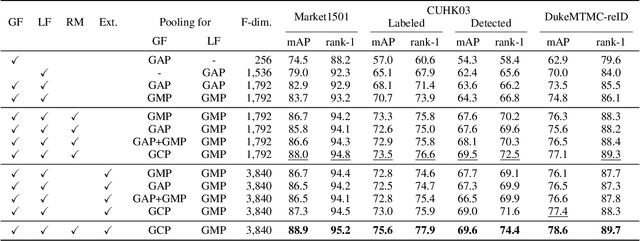
Person re-identification (reID) aims at retrieving an image of the person of interest from a set of images typically captured by multiple cameras. Recent reID methods have shown that exploiting local features describing body parts, together with a global feature of a person image itself, gives robust feature representations, even in the case of missing body parts. However, using the individual part-level features directly, without considering relations between body parts, confuses differentiating identities of different persons having similar attributes in corresponding parts. To address this issue, we propose a new relation network for person reID that considers relations between individual body parts and the rest of them. Our model makes a single part-level feature incorporate partial information of other body parts as well, supporting it to be more discriminative. We also introduce a global contrastive pooling (GCP) method to obtain a global feature of a person image. We propose to use contrastive features for GCP to complement conventional max and averaging pooling techniques. We show that our model outperforms the state of the art on the Market1501, DukeMTMC-reID and CUHK03 datasets, demonstrating the effectiveness of our approach on discriminative person representations.
Temporally Consistent Depth Prediction with Flow-Guided Memory Units
Sep 16, 2019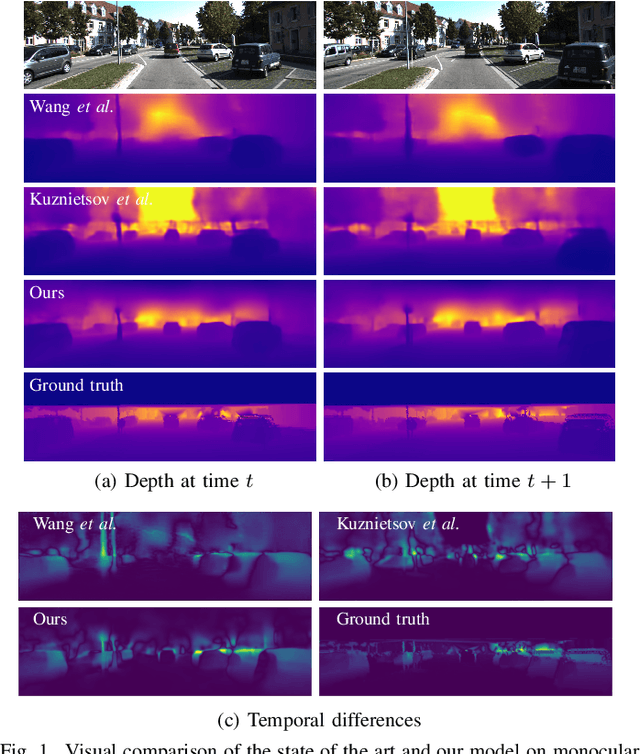
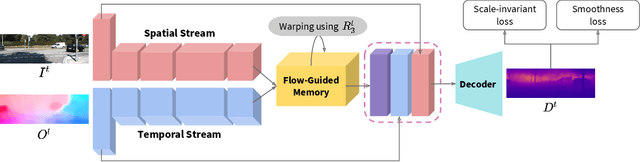
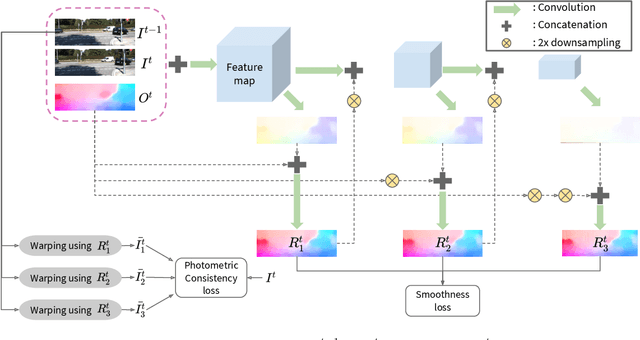
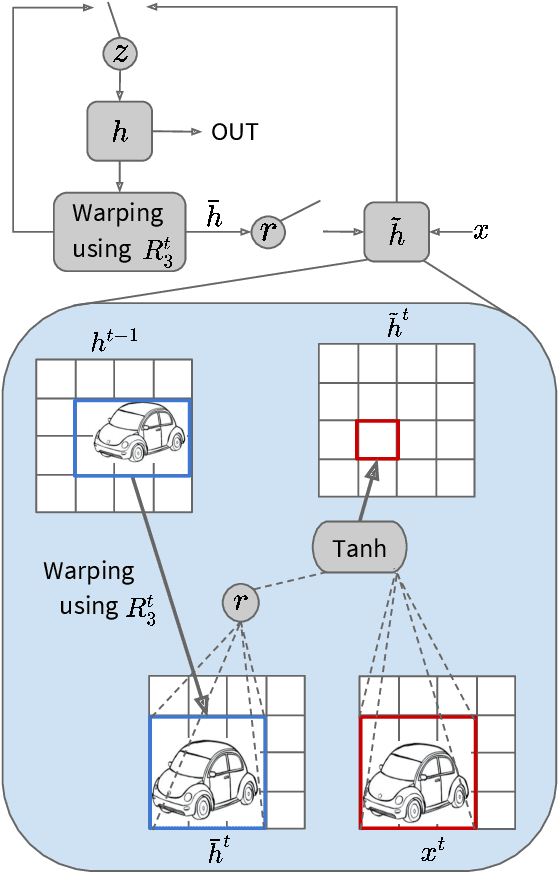
Predicting depth from a monocular video sequence is an important task for autonomous driving. Although it has advanced considerably in the past few years, recent methods based on convolutional neural networks (CNNs) discard temporal coherence in the video sequence and estimate depth independently for each frame, which often leads to undesired inconsistent results over time. To address this problem, we propose to memorize temporal consistency in the video sequence, and leverage it for the task of depth prediction. To this end, we introduce a two-stream CNN with a flow-guided memory module, where each stream encodes visual and temporal features, respectively. The memory module, implemented using convolutional gated recurrent units (ConvGRUs), inputs visual and temporal features sequentially together with optical flow tailored to our task. It memorizes trajectories of individual features selectively and propagates spatial information over time, enforcing a long-term temporal consistency to prediction results. We evaluate our method on the KITTI benchmark dataset in terms of depth prediction accuracy, temporal consistency and runtime, and achieve a new state of the art. We also provide an extensive experimental analysis, clearly demonstrating the effectiveness of our approach to memorizing temporal consistency for depth prediction.