 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Hierarchical Consistency and Unbiased Objectness for Open-Vocabulary Object Detection
Apr 25, 2026Conventional object detectors typically operate under a closed-set assumption, limiting recognition to a predefined set of base classes seen during training. Open-vocabulary object detection (OVD) addresses this limitation by leveraging vision-language models (VLMs) to generate pseudo labels for novel object classes. However, existing OVD methods suffer from two critical drawbacks: (1) inaccurate class label assignments, as VLMs are optimized for image-level predictions rather than the region-level predictions required for pseudo labeling, and (2) unreliable objectness scores from region proposal networks (RPNs) trained exclusively on base object classes. To address these issues, we propose a novel pseudo labeling framework for OVD. Our approach introduces a hierarchical confidence calibration (HCC) technique, which ensures reliable class label estimation by assessing consistency across hierarchical semantic levels (class, super- and sub-category). We also present LoCLIP, a parameter-efficient adaptation of CLIP that incorporates an objectness token to mitigate base class bias problem of RPNs and provide reliable objectness estimations for novel object classes. Extensive experiments on standard OVD benchmarks, including COCO and LVIS, demonstrate that our approach clearly sets a new state of the art, validating the effectiveness of our approach. Project site: https://cvlab.yonsei.ac.kr/projects/HCC
ACLS: Adaptive and Conditional Label Smoothing for Network Calibration
Aug 24, 2023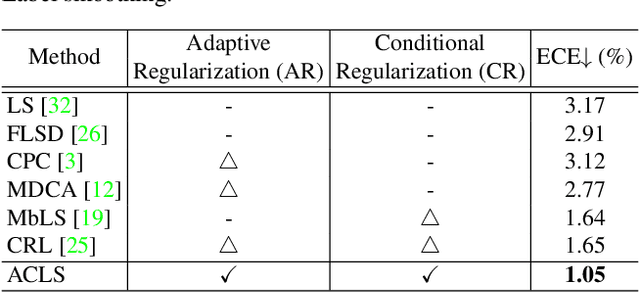
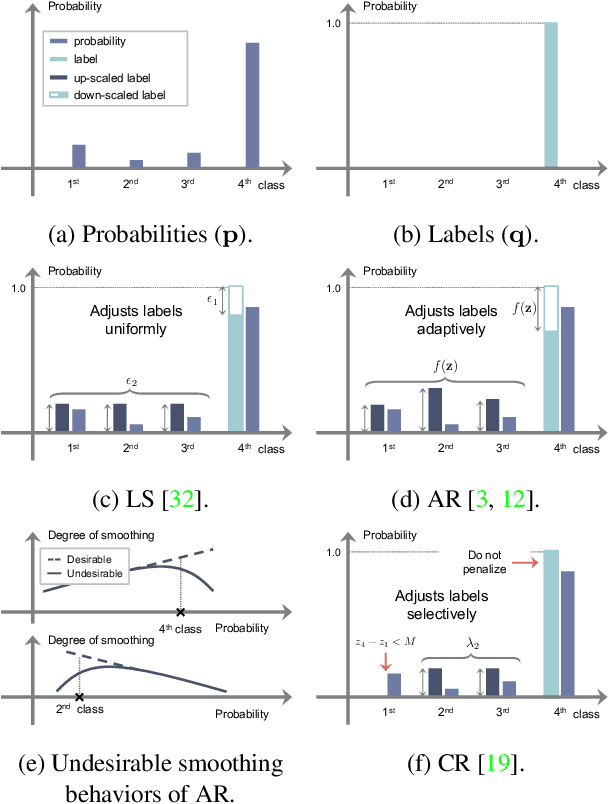
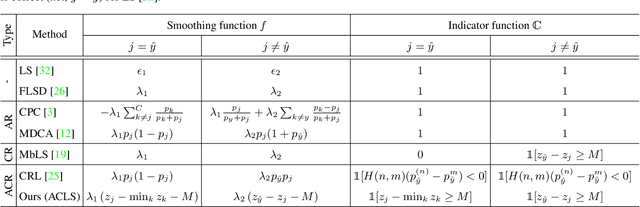
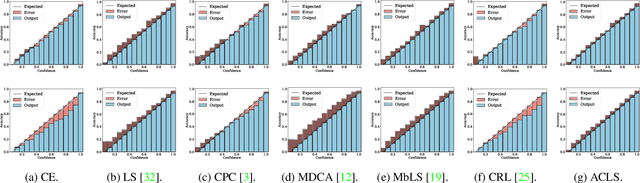
We address the problem of network calibration adjusting miscalibrated confidences of deep neural networks. Many approaches to network calibration adopt a regularization-based method that exploits a regularization term to smooth the miscalibrated confidences. Although these approaches have shown the effectiveness on calibrating the networks, there is still a lack of understanding on the underlying principles of regularization in terms of network calibration. We present in this paper an in-depth analysis of existing regularization-based methods, providing a better understanding on how they affect to network calibration. Specifically, we have observed that 1) the regularization-based methods can be interpreted as variants of label smoothing, and 2) they do not always behave desirably. Based on the analysis, we introduce a novel loss function, dubbed ACLS, that unifies the merits of existing regularization methods, while avoiding the limitations. We show extensive experimental results for image classification and semantic segmentation on standard benchmarks, including CIFAR10, Tiny-ImageNet, ImageNet, and PASCAL VOC, demonstrating the effectiveness of our loss function.
RankMixup: Ranking-Based Mixup Training for Network Calibration
Aug 23, 2023
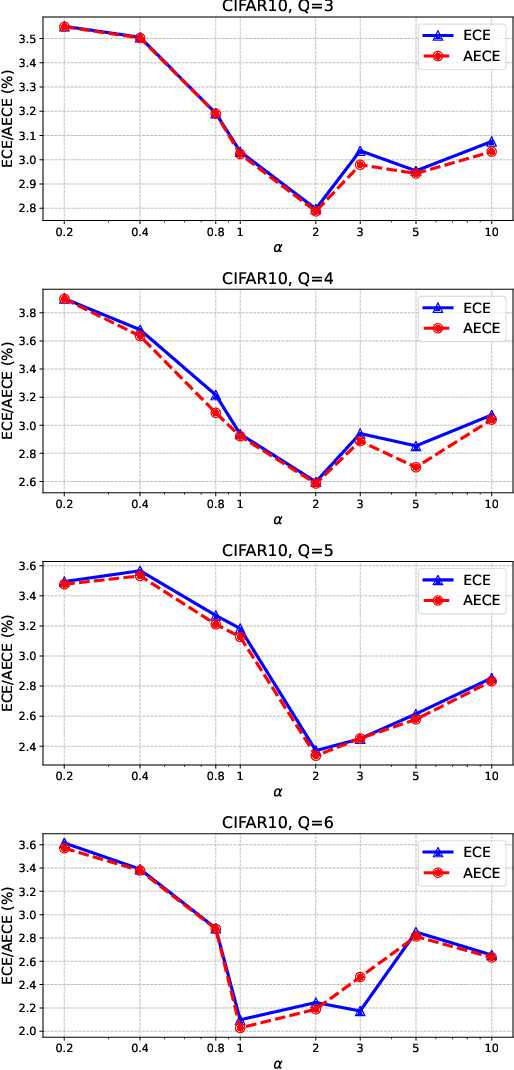
Network calibration aims to accurately estimate the level of confidences, which is particularly important for employing deep neural networks in real-world systems. Recent approaches leverage mixup to calibrate the network's predictions during training. However, they do not consider the problem that mixtures of labels in mixup may not accurately represent the actual distribution of augmented samples. In this paper, we present RankMixup, a novel mixup-based framework alleviating the problem of the mixture of labels for network calibration. To this end, we propose to use an ordinal ranking relationship between raw and mixup-augmented samples as an alternative supervisory signal to the label mixtures for network calibration. We hypothesize that the network should estimate a higher level of confidence for the raw samples than the augmented ones (Fig.1). To implement this idea, we introduce a mixup-based ranking loss (MRL) that encourages lower confidences for augmented samples compared to raw ones, maintaining the ranking relationship. We also propose to leverage the ranking relationship among multiple mixup-augmented samples to further improve the calibration capability. Augmented samples with larger mixing coefficients are expected to have higher confidences and vice versa (Fig.1). That is, the order of confidences should be aligned with that of mixing coefficients. To this end, we introduce a novel loss, M-NDCG, in order to reduce the number of misaligned pairs of the coefficients and confidences. Extensive experimental results on standard benchmarks for network calibration demonstrate the effectiveness of RankMixup.
Bi-directional Contrastive Learning for Domain Adaptive Semantic Segmentation
Jul 22, 2022
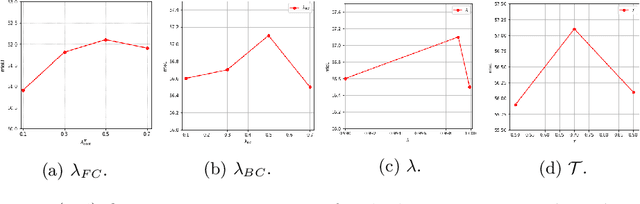
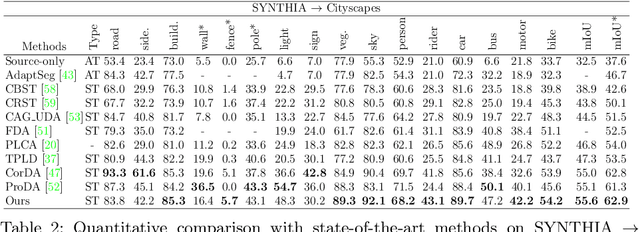

We present a novel unsupervised domain adaptation method for semantic segmentation that generalizes a model trained with source images and corresponding ground-truth labels to a target domain. A key to domain adaptive semantic segmentation is to learn domain-invariant and discriminative features without target ground-truth labels. To this end, we propose a bi-directional pixel-prototype contrastive learning framework that minimizes intra-class variations of features for the same object class, while maximizing inter-class variations for different ones, regardless of domains. Specifically, our framework aligns pixel-level features and a prototype of the same object class in target and source images (i.e., positive pairs), respectively, sets them apart for different classes (i.e., negative pairs), and performs the alignment and separation processes toward the other direction with pixel-level features in the source image and a prototype in the target image. The cross-domain matching encourages domain-invariant feature representations, while the bidirectional pixel-prototype correspondences aggregate features for the same object class, providing discriminative features. To establish training pairs for contrastive learning, we propose to generate dynamic pseudo labels of target images using a non-parametric label transfer, that is, pixel-prototype correspondences across different domains. We also present a calibration method compensating class-wise domain biases of prototypes gradually during training.