 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Representations for Short-Term and Long-Term Person Re-Identification
Sep 09, 2024
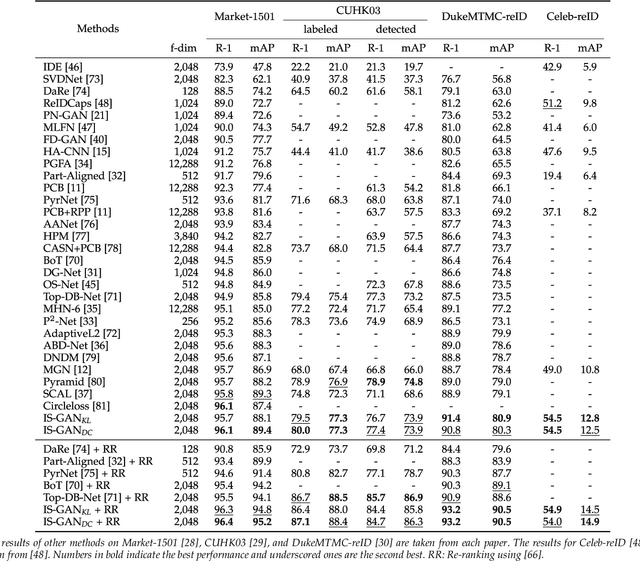

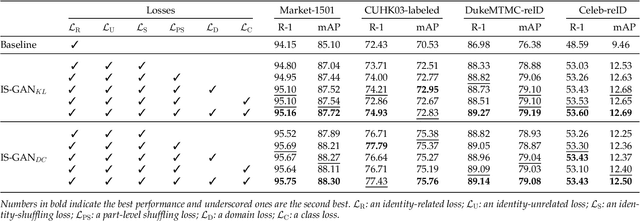
We address the problem of person re-identification (reID), that is, retrieving person images from a large dataset, given a query image of the person of interest. A key challenge is to learn person representations robust to intra-class variations, as different persons could have the same attribute, and persons' appearances look different, e.g., with viewpoint changes. Recent reID methods focus on learning person features discriminative only for a particular factor of variations (e.g., human pose), which also requires corresponding supervisory signals (e.g., pose annotations). To tackle this problem, we propose to factorize person images into identity-related and unrelated features. Identity-related features contain information useful for specifying a particular person (e.g., clothing), while identity-unrelated ones hold other factors (e.g., human pose). To this end, we propose a new generative adversarial network, dubbed identity shuffle GAN (IS-GAN). It disentangles identity-related and unrelated features from person images through an identity-shuffling technique that exploits identification labels alone without any auxiliary supervisory signals. We restrict the distribution of identity-unrelated features or encourage the identity-related and unrelated features to be uncorrelated, facilitating the disentanglement process. Experimental results validate the effectiveness of IS-GAN, showing state-of-the-art performance on standard reID benchmarks, including Market-1501, CUHK03, and DukeMTMC-reID. We further demonstrate the advantages of disentangling person representations on a long-term reID task, setting a new state of the art on a Celeb-reID dataset.
* arXiv admin note: substantial text overlap with arXiv:1910.12003
Rethinking Evaluation Metric for Probability Estimation Models Using Esports Data
Sep 12, 2023Probability estimation models play an important role in various fields, such as weather forecasting, recommendation systems, and sports analysis. Among several models estimating probabilities, it is difficult to evaluate which model gives reliable probabilities since the ground-truth probabilities are not available. The win probability estimation model for esports, which calculates the win probability under a certain game state, is also one of the fields being actively studied in probability estimation. However, most of the previous works evaluated their models using accuracy, a metric that only can measure the performance of discrimination. In this work, we firstly investigate the Brier score and the Expected Calibration Error (ECE) as a replacement of accuracy used as a performance evaluation metric for win probability estimation models in esports field. Based on the analysis, we propose a novel metric called Balance score which is a simple yet effective metric in terms of six good properties that probability estimation metric should have. Under the general condition, we also found that the Balance score can be an effective approximation of the true expected calibration error which has been imperfectly approximated by ECE using the binning technique. Extensive evaluations using simulation studies and real game snapshot data demonstrate the promising potential to adopt the proposed metric not only for the win probability estimation model for esports but also for evaluating general probability estimation models.
Bi-directional Contrastive Learning for Domain Adaptive Semantic Segmentation
Jul 22, 2022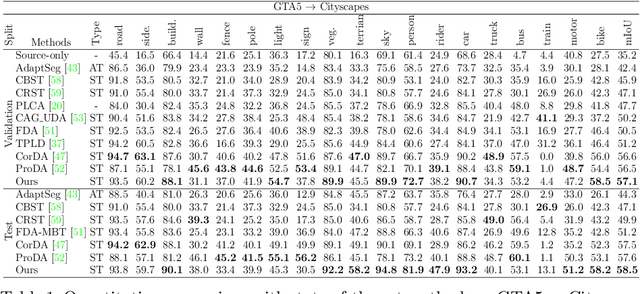
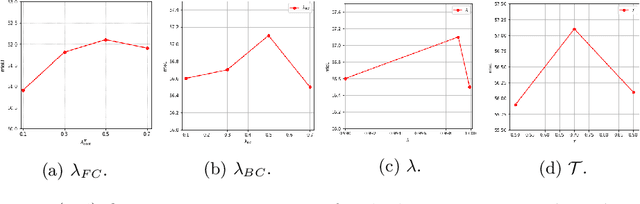
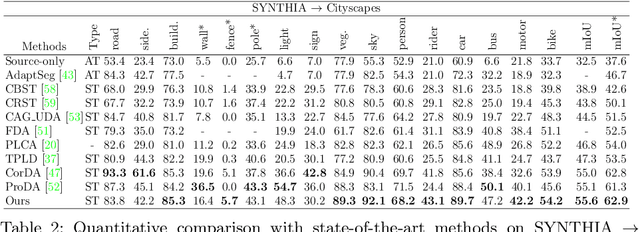

We present a novel unsupervised domain adaptation method for semantic segmentation that generalizes a model trained with source images and corresponding ground-truth labels to a target domain. A key to domain adaptive semantic segmentation is to learn domain-invariant and discriminative features without target ground-truth labels. To this end, we propose a bi-directional pixel-prototype contrastive learning framework that minimizes intra-class variations of features for the same object class, while maximizing inter-class variations for different ones, regardless of domains. Specifically, our framework aligns pixel-level features and a prototype of the same object class in target and source images (i.e., positive pairs), respectively, sets them apart for different classes (i.e., negative pairs), and performs the alignment and separation processes toward the other direction with pixel-level features in the source image and a prototype in the target image. The cross-domain matching encourages domain-invariant feature representations, while the bidirectional pixel-prototype correspondences aggregate features for the same object class, providing discriminative features. To establish training pairs for contrastive learning, we propose to generate dynamic pseudo labels of target images using a non-parametric label transfer, that is, pixel-prototype correspondences across different domains. We also present a calibration method compensating class-wise domain biases of prototypes gradually during training.
Learning with Privileged Information for Efficient Image Super-Resolution
Jul 15, 2020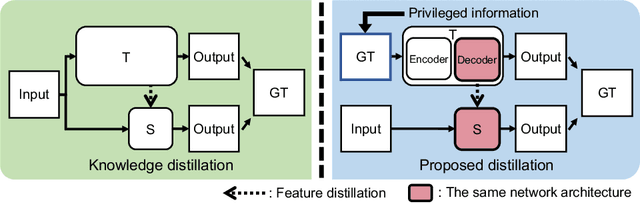
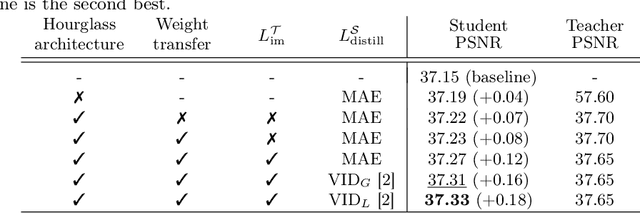


Convolutional neural networks (CNNs) have allowed remarkable advances in single image super-resolution (SISR) over the last decade. Most SR methods based on CNNs have focused on achieving performance gains in terms of quality metrics, such as PSNR and SSIM, over classical approaches. They typically require a large amount of memory and computational units. FSRCNN, consisting of few numbers of convolutional layers, has shown promising results, while using an extremely small number of network parameters. We introduce in this paper a novel distillation framework, consisting of teacher and student networks, that allows to boost the performance of FSRCNN drastically. To this end, we propose to use ground-truth high-resolution (HR) images as privileged information. The encoder in the teacher learns the degradation process, subsampling of HR images, using an imitation loss. The student and the decoder in the teacher, having the same network architecture as FSRCNN, try to reconstruct HR images. Intermediate features in the decoder, affordable for the student to learn, are transferred to the student through feature distillation. Experimental results on standard benchmarks demonstrate the effectiveness and the generalization ability of our framework, which significantly boosts the performance of FSRCNN as well as other SR methods. Our code and model are available online: https://cvlab.yonsei.ac.kr/projects/PISR.
Learning Semantic Correspondence Exploiting an Object-level Prior
Nov 29, 2019



We address the problem of semantic correspondence, that is, establishing a dense flow field between images depicting different instances of the same object or scene category. We propose to use images annotated with binary foreground masks and subjected to synthetic geometric deformations to train a convolutional neural network (CNN) for this task. Using these masks as part of the supervisory signal provides an object-level prior for the semantic correspondence task and offers a good compromise between semantic flow methods, where the amount of training data is limited by the cost of manually selecting point correspondences, and semantic alignment ones, where the regression of a single global geometric transformation between images may be sensitive to image-specific details such as background clutter. We propose a new CNN architecture, dubbed SFNet, which implements this idea. It leverages a new and differentiable version of the argmax function for end-to-end training, with a loss that combines mask and flow consistency with smoothness terms. Experimental results demonstrate the effectiveness of our approach, which significantly outperforms the state of the art on standard benchmarks.