 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMaMa: Mask-Guided Video Matting via Generative Prior
Jan 20, 2026Generalizing video matting models to real-world videos remains a significant challenge due to the scarcity of labeled data. To address this, we present Video Mask-to-Matte Model (VideoMaMa) that converts coarse segmentation masks into pixel accurate alpha mattes, by leveraging pretrained video diffusion models. VideoMaMa demonstrates strong zero-shot generalization to real-world footage, even though it is trained solely on synthetic data. Building on this capability, we develop a scalable pseudo-labeling pipeline for large-scale video matting and construct the Matting Anything in Video (MA-V) dataset, which offers high-quality matting annotations for more than 50K real-world videos spanning diverse scenes and motions. To validate the effectiveness of this dataset, we fine-tune the SAM2 model on MA-V to obtain SAM2-Matte, which outperforms the same model trained on existing matting datasets in terms of robustness on in-the-wild videos. These findings emphasize the importance of large-scale pseudo-labeled video matting and showcase how generative priors and accessible segmentation cues can drive scalable progress in video matting research.
Visual Representation Alignment for Multimodal Large Language Models
Sep 09, 2025Multimodal large language models (MLLMs) trained with visual instruction tuning have achieved strong performance across diverse tasks, yet they remain limited in vision-centric tasks such as object counting or spatial reasoning. We attribute this gap to the prevailing text-only supervision paradigm, which provides only indirect guidance for the visual pathway and often leads MLLMs to discard fine-grained visual details during training. In this paper, we present VIsual Representation ALignment (VIRAL), a simple yet effective regularization strategy that aligns the internal visual representations of MLLMs with those of pre-trained vision foundation models (VFMs). By explicitly enforcing this alignment, VIRAL enables the model not only to retain critical visual details from the input vision encoder but also to complement additional visual knowledge from VFMs, thereby enhancing its ability to reason over complex visual inputs. Our experiments demonstrate consistent improvements across all tasks on widely adopted multimodal benchmarks. Furthermore, we conduct comprehensive ablation studies to validate the key design choices underlying our framework. We believe this simple finding opens up an important direction for the effective integration of visual information in training MLLMs.
S^4M: Boosting Semi-Supervised Instance Segmentation with SAM
Apr 07, 2025Semi-supervised instance segmentation poses challenges due to limited labeled data, causing difficulties in accurately localizing distinct object instances. Current teacher-student frameworks still suffer from performance constraints due to unreliable pseudo-label quality stemming from limited labeled data. While the Segment Anything Model (SAM) offers robust segmentation capabilities at various granularities, directly applying SAM to this task introduces challenges such as class-agnostic predictions and potential over-segmentation. To address these complexities, we carefully integrate SAM into the semi-supervised instance segmentation framework, developing a novel distillation method that effectively captures the precise localization capabilities of SAM without compromising semantic recognition. Furthermore, we incorporate pseudo-label refinement as well as a specialized data augmentation with the refined pseudo-labels, resulting in superior performance. We establish state-of-the-art performance, and provide comprehensive experiments and ablation studies to validate the effectiveness of our proposed approach.
URECA: Unique Region Caption Anything
Apr 07, 2025
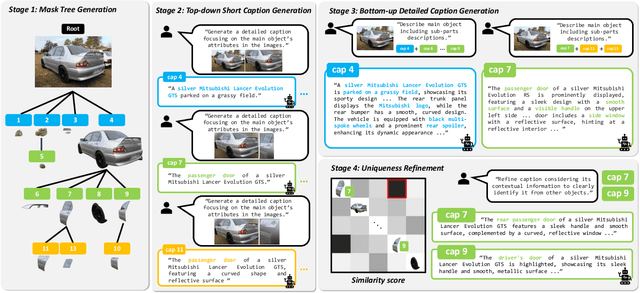
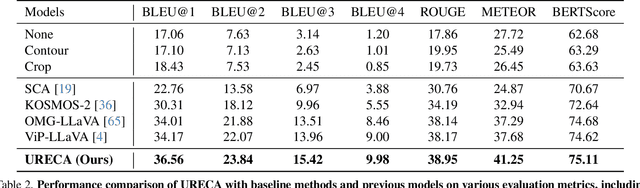
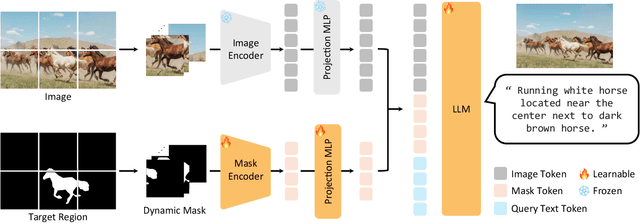
Region-level captioning aims to generate natural language descriptions for specific image regions while highlighting their distinguishing features. However, existing methods struggle to produce unique captions across multi-granularity, limiting their real-world applicability. To address the need for detailed region-level understanding, we introduce URECA dataset, a large-scale dataset tailored for multi-granularity region captioning. Unlike prior datasets that focus primarily on salient objects, URECA dataset ensures a unique and consistent mapping between regions and captions by incorporating a diverse set of objects, parts, and background elements. Central to this is a stage-wise data curation pipeline, where each stage incrementally refines region selection and caption generation. By leveraging Multimodal Large Language Models (MLLMs) at each stage, our pipeline produces distinctive and contextually grounded captions with improved accuracy and semantic diversity. Building upon this dataset, we present URECA, a novel captioning model designed to effectively encode multi-granularity regions. URECA maintains essential spatial properties such as position and shape through simple yet impactful modifications to existing MLLMs, enabling fine-grained and semantically rich region descriptions. Our approach introduces dynamic mask modeling and a high-resolution mask encoder to enhance caption uniqueness. Experiments show that URECA achieves state-of-the-art performance on URECA dataset and generalizes well to existing region-level captioning benchmarks.
Referring Video Object Segmentation via Language-aligned Track Selection
Dec 02, 2024Referring Video Object Segmentation (RVOS) seeks to segment objects throughout a video based on natural language expressions. While existing methods have made strides in vision-language alignment, they often overlook the importance of robust video object tracking, where inconsistent mask tracks can disrupt vision-language alignment, leading to suboptimal performance. In this work, we present Selection by Object Language Alignment (SOLA), a novel framework that reformulates RVOS into two sub-problems, track generation and track selection. In track generation, we leverage a vision foundation model, Segment Anything Model 2 (SAM2), which generates consistent mask tracks across frames, producing reliable candidates for both foreground and background objects. For track selection, we propose a light yet effective selection module that aligns visual and textual features while modeling object appearance and motion within video sequences. This design enables precise motion modeling and alignment of the vision language. Our approach achieves state-of-the-art performance on the challenging MeViS dataset and demonstrates superior results in zero-shot settings on the Ref-Youtube-VOS and Ref-DAVIS datasets. Furthermore, SOLA exhibits strong generalization and robustness in corrupted settings, such as those with added Gaussian noise or motion blur. Our project page is available at https://cvlab-kaist.github.io/SOLA
GaussianTalker: Real-Time High-Fidelity Talking Head Synthesis with Audio-Driven 3D Gaussian Splatting
Apr 25, 2024



We propose GaussianTalker, a novel framework for real-time generation of pose-controllable talking heads. It leverages the fast rendering capabilities of 3D Gaussian Splatting (3DGS) while addressing the challenges of directly controlling 3DGS with speech audio. GaussianTalker constructs a canonical 3DGS representation of the head and deforms it in sync with the audio. A key insight is to encode the 3D Gaussian attributes into a shared implicit feature representation, where it is merged with audio features to manipulate each Gaussian attribute. This design exploits the spatial-aware features and enforces interactions between neighboring points. The feature embeddings are then fed to a spatial-audio attention module, which predicts frame-wise offsets for the attributes of each Gaussian. It is more stable than previous concatenation or multiplication approaches for manipulating the numerous Gaussians and their intricate parameters. Experimental results showcase GaussianTalker's superiority in facial fidelity, lip synchronization accuracy, and rendering speed compared to previous methods. Specifically, GaussianTalker achieves a remarkable rendering speed up to 120 FPS, surpassing previous benchmarks. Our code is made available at https://github.com/KU-CVLAB/GaussianTalker/ .
Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Mar 29, 2024Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.