 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARIOH: Multiplicity-Aware Hypergraph Reconstruction
Apr 01, 2025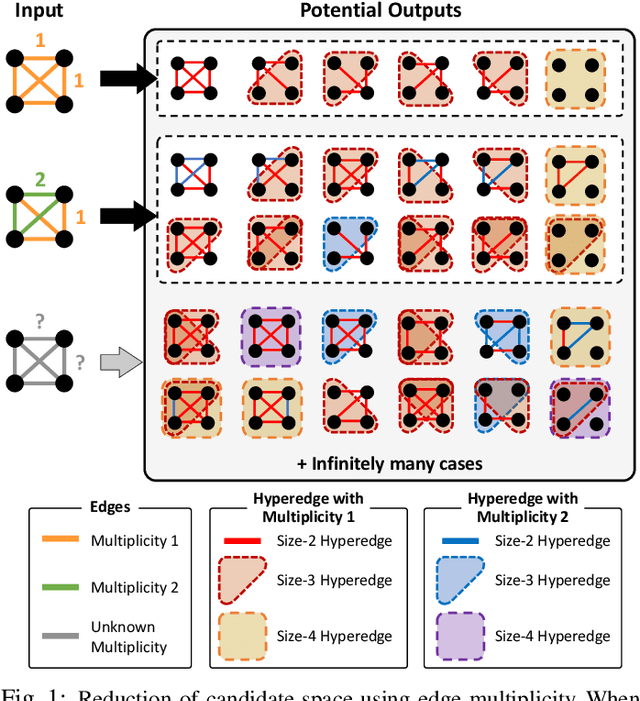
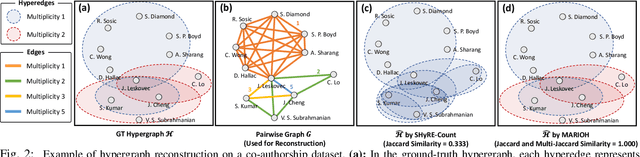
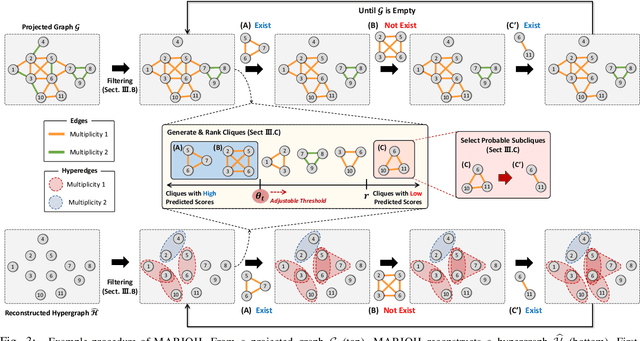
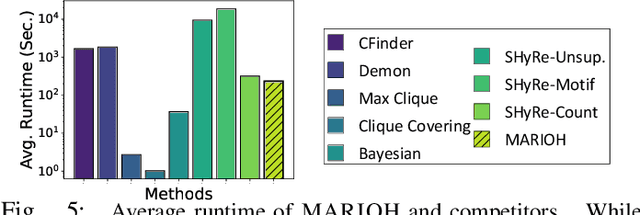
Hypergraphs offer a powerful framework for modeling higher-order interactions that traditional pairwise graphs cannot fully capture. However, practical constraints often lead to their simplification into projected graphs, resulting in substantial information loss and ambiguity in representing higher-order relationships. In this work, we propose MARIOH, a supervised approach for reconstructing the original hypergraph from its projected graph by leveraging edge multiplicity. To overcome the difficulties posed by the large search space, MARIOH integrates several key ideas: (a) identifying provable size-2 hyperedges, which reduces the candidate search space, (b) predicting the likelihood of candidates being hyperedges by utilizing both structural and multiplicity-related features, and (c) not only targeting promising hyperedge candidates but also examining less confident ones to explore alternative possibilities. Together, these ideas enable MARIOH to efficiently and effectively explore the search space. In our experiments using 10 real-world datasets, MARIOH achieves up to 74.51% higher reconstruction accuracy compared to state-of-the-art methods.
Effective Training Strategies for Deep-learning-based Precipitation Nowcasting and Estimation
Feb 17, 2022
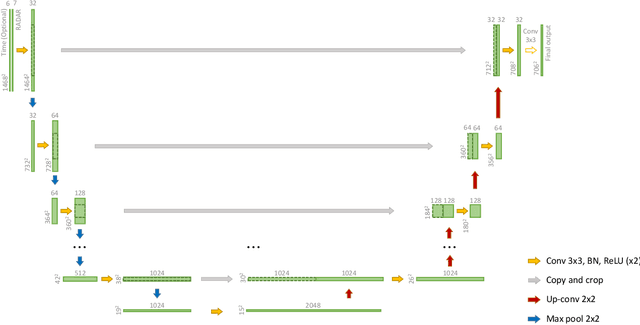
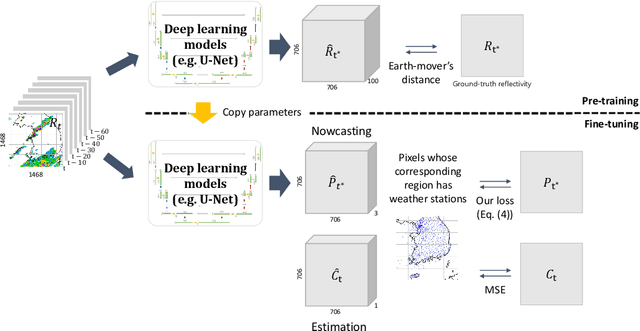
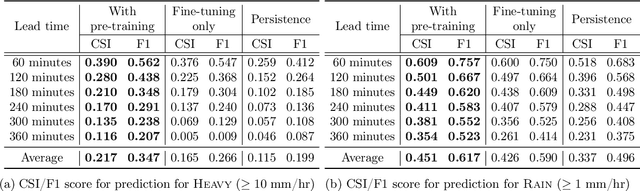
Deep learning has been successfully applied to precipitation nowcasting. In this work, we propose a pre-training scheme and a new loss function for improving deep-learning-based nowcasting. First, we adapt U-Net, a widely-used deep-learning model, for the two problems of interest here: precipitation nowcasting and precipitation estimation from radar images. We formulate the former as a classification problem with three precipitation intervals and the latter as a regression problem. For these tasks, we propose to pre-train the model to predict radar images in the near future without requiring ground-truth precipitation, and we also propose the use of a new loss function for fine-tuning to mitigate the class imbalance problem. We demonstrate the effectiveness of our approach using radar images and precipitation datasets collected from South Korea over seven years. It is highlighted that our pre-training scheme and new loss function improve the critical success index (CSI) of nowcasting of heavy rainfall (at least 10 mm/hr) by up to 95.7% and 43.6%, respectively, at a 5-hr lead time. We also demonstrate that our approach reduces the precipitation estimation error by up to 10.7%, compared to the conventional approach, for light rainfall (between 1 and 10 mm/hr). Lastly, we report the sensitivity of our approach to different resolutions and a detailed analysis of four cases of heavy rainfall.
MONSTOR: An Inductive Approach for Estimating and Maximizing Influence over Unseen Social Networks
Jan 24, 2020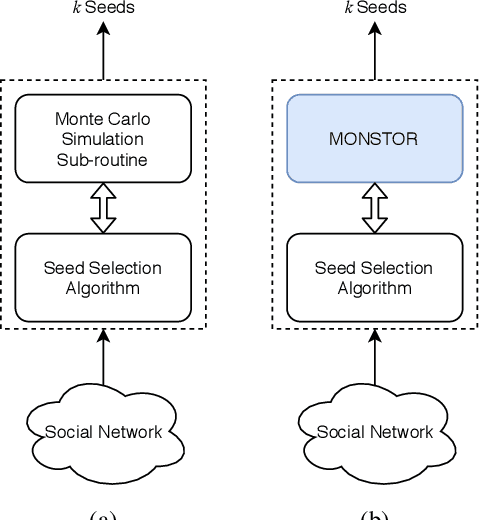
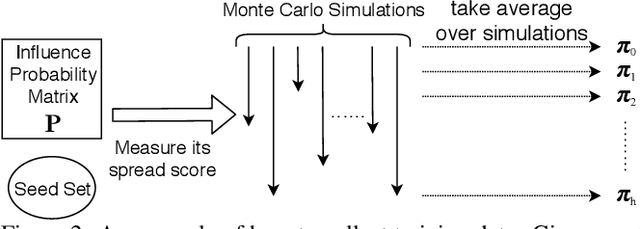

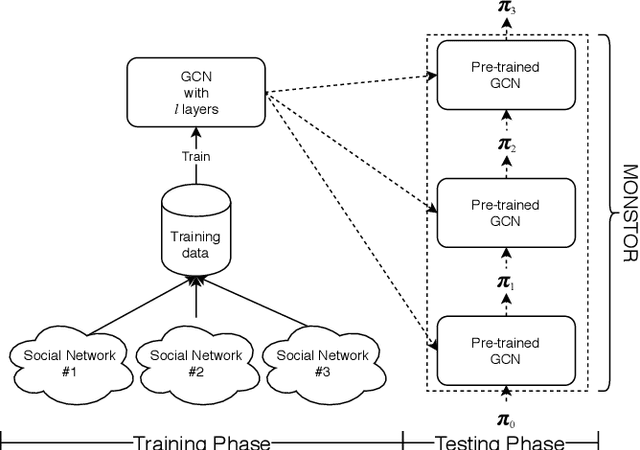
Influence maximization (IM) is one of the most important problems in social network analysis. Its objective is to find a given number of seed nodes who maximize the spread of information through a social network. Since it is an NP-hard problem, many approximate/heuristic methods have been developed, and a number of them repeats Monte Carlo (MC) simulations over and over, specifically tens of thousands of times or more per potential seed set, to reliably estimate the influence. In this work, we present an inductive machine learning method, called Monte Carlo Simulator (MONSTOR), to predict the results of MC simulations on networks unseen during training. MONSTOR can greatly accelerate existing IM methods by replacing repeated MC simulations. In our experiments, MONSTOR achieves near-perfect accuracy on unseen real social networks with little sacrifice of accuracy in IM use cases.