 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Centric Unsupervised Node Representation Learning Without Homophily Assumption
Dec 17, 2025Unsupervised node representation learning aims to obtain meaningful node embeddings without relying on node labels. To achieve this, graph convolution, which aggregates information from neighboring nodes, is commonly employed to encode node features and graph topology. However, excessive reliance on graph convolution can be suboptimal-especially in non-homophilic graphs-since it may yield unduly similar embeddings for nodes that differ in their features or topological properties. As a result, adjusting the degree of graph convolution usage has been actively explored in supervised learning settings, whereas such approaches remain underexplored in unsupervised scenarios. To tackle this, we propose FUEL, which adaptively learns the adequate degree of graph convolution usage by aiming to enhance intra-class similarity and inter-class separability in the embedding space. Since classes are unknown, FUEL leverages node features to identify node clusters and treats these clusters as proxies for classes. Through extensive experiments using 15 baseline methods and 14 benchmark datasets, we demonstrate the effectiveness of FUEL in downstream tasks, achieving state-of-the-art performance across graphs with diverse levels of homophily.
'Hello, World!': Making GNNs Talk with LLMs
May 27, 2025While graph neural networks (GNNs) have shown remarkable performance across diverse graph-related tasks, their high-dimensional hidden representations render them black boxes. In this work, we propose Graph Lingual Network (GLN), a GNN built on large language models (LLMs), with hidden representations in the form of human-readable text. Through careful prompt design, GLN incorporates not only the message passing module of GNNs but also advanced GNN techniques, including graph attention and initial residual connection. The comprehensibility of GLN's hidden representations enables an intuitive analysis of how node representations change (1) across layers and (2) under advanced GNN techniques, shedding light on the inner workings of GNNs. Furthermore, we demonstrate that GLN achieves strong zero-shot performance on node classification and link prediction, outperforming existing LLM-based baseline methods.
Emergence of psychopathological computations in large language models
Apr 10, 2025Can large language models (LLMs) implement computations of psychopathology? An effective approach to the question hinges on addressing two factors. First, for conceptual validity, we require a general and computational account of psychopathology that is applicable to computational entities without biological embodiment or subjective experience. Second, mechanisms underlying LLM behaviors need to be studied for better methodological validity. Thus, we establish a computational-theoretical framework to provide an account of psychopathology applicable to LLMs. To ground the theory for empirical analysis, we also propose a novel mechanistic interpretability method alongside a tailored empirical analytic framework. Based on the frameworks, we conduct experiments demonstrating three key claims: first, that distinct dysfunctional and problematic representational states are implemented in LLMs; second, that their activations can spread and self-sustain to trap LLMs; and third, that dynamic, cyclic structural causal models encoded in the LLMs underpin these patterns. In concert, the empirical results corroborate our hypothesis that network-theoretic computations of psychopathology have already emerged in LLMs. This suggests that certain LLM behaviors mirroring psychopathology may not be a superficial mimicry but a feature of their internal processing. Thus, our work alludes to the possibility of AI systems with psychopathological behaviors in the near future.
On Measuring Unnoticeability of Graph Adversarial Attacks: Observations, New Measure, and Applications
Jan 09, 2025



Adversarial attacks are allegedly unnoticeable. Prior studies have designed attack noticeability measures on graphs, primarily using statistical tests to compare the topology of original and (possibly) attacked graphs. However, we observe two critical limitations in the existing measures. First, because the measures rely on simple rules, attackers can readily enhance their attacks to bypass them, reducing their attack "noticeability" and, yet, maintaining their attack performance. Second, because the measures naively leverage global statistics, such as degree distributions, they may entirely overlook attacks until severe perturbations occur, letting the attacks be almost "totally unnoticeable." To address the limitations, we introduce HideNSeek, a learnable measure for graph attack noticeability. First, to mitigate the bypass problem, HideNSeek learns to distinguish the original and (potential) attack edges using a learnable edge scorer (LEO), which scores each edge on its likelihood of being an attack. Second, to mitigate the overlooking problem, HideNSeek conducts imbalance-aware aggregation of all the edge scores to obtain the final noticeability score. Using six real-world graphs, we empirically demonstrate that HideNSeek effectively alleviates the observed limitations, and LEO (i.e., our learnable edge scorer) outperforms eleven competitors in distinguishing attack edges under five different attack methods. For an additional application, we show that LEO boost the performance of robust GNNs by removing attack-like edges.
Rethinking Reconstruction-based Graph-Level Anomaly Detection: Limitations and a Simple Remedy
Oct 27, 2024Graph autoencoders (Graph-AEs) learn representations of given graphs by aiming to accurately reconstruct them. A notable application of Graph-AEs is graph-level anomaly detection (GLAD), whose objective is to identify graphs with anomalous topological structures and/or node features compared to the majority of the graph population. Graph-AEs for GLAD regard a graph with a high mean reconstruction error (i.e. mean of errors from all node pairs and/or nodes) as anomalies. Namely, the methods rest on the assumption that they would better reconstruct graphs with similar characteristics to the majority. We, however, report non-trivial counter-examples, a phenomenon we call reconstruction flip, and highlight the limitations of the existing Graph-AE-based GLAD methods. Specifically, we empirically and theoretically investigate when this assumption holds and when it fails. Through our analyses, we further argue that, while the reconstruction errors for a given graph are effective features for GLAD, leveraging the multifaceted summaries of the reconstruction errors, beyond just mean, can further strengthen the features. Thus, we propose a novel and simple GLAD method, named MUSE. The key innovation of MUSE involves taking multifaceted summaries of reconstruction errors as graph features for GLAD. This surprisingly simple method obtains SOTA performance in GLAD, performing best overall among 14 methods across 10 datasets.
Tackling Prevalent Conditions in Unsupervised Combinatorial Optimization: Cardinality, Minimum, Covering, and More
May 14, 2024
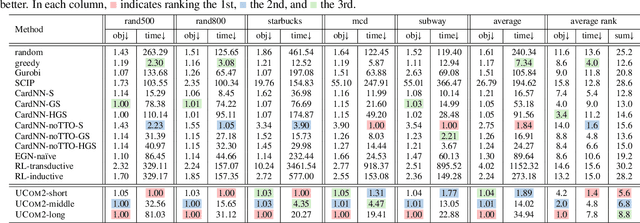
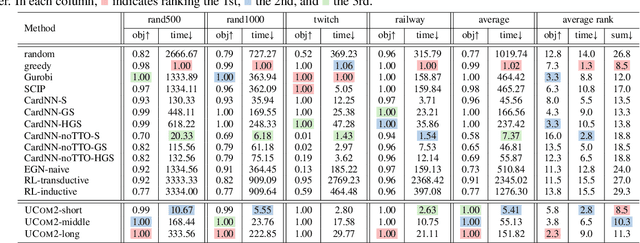

Combinatorial optimization (CO) is naturally discrete, making machine learning based on differentiable optimization inapplicable. Karalias & Loukas (2020) adapted the probabilistic method to incorporate CO into differentiable optimization. Their work ignited the research on unsupervised learning for CO, composed of two main components: probabilistic objectives and derandomization. However, each component confronts unique challenges. First, deriving objectives under various conditions (e.g., cardinality constraints and minimum) is nontrivial. Second, the derandomization process is underexplored, and the existing derandomization methods are either random sampling or naive rounding. In this work, we aim to tackle prevalent (i.e., commonly involved) conditions in unsupervised CO. First, we concretize the targets for objective construction and derandomization with theoretical justification. Then, for various conditions commonly involved in different CO problems, we derive nontrivial objectives and derandomization to meet the targets. Finally, we apply the derivations to various CO problems. Via extensive experiments on synthetic and real-world graphs, we validate the correctness of our derivations and show our empirical superiority w.r.t. both optimization quality and speed.
A Survey on Hypergraph Neural Networks: An In-Depth and Step-By-Step Guide
Apr 01, 2024



Higher-order interactions (HOIs) are ubiquitous in real-world complex systems and applications, and thus investigation of deep learning for HOIs has become a valuable agenda for the data mining and machine learning communities. As networks of HOIs are expressed mathematically as hypergraphs, hypergraph neural networks (HNNs) have emerged as a powerful tool for representation learning on hypergraphs. Given the emerging trend, we present the first survey dedicated to HNNs, with an in-depth and step-by-step guide. Broadly, the present survey overviews HNN architectures, training strategies, and applications. First, we break existing HNNs down into four design components: (i) input features, (ii) input structures, (iii) message-passing schemes, and (iv) training strategies. Second, we examine how HNNs address and learn HOIs with each of their components. Third, we overview the recent applications of HNNs in recommendation, biological and medical science, time series analysis, and computer vision. Lastly, we conclude with a discussion on limitations and future directions.
HypeBoy: Generative Self-Supervised Representation Learning on Hypergraphs
Mar 31, 2024



Hypergraphs are marked by complex topology, expressing higher-order interactions among multiple nodes with hyperedges, and better capturing the topology is essential for effective representation learning. Recent advances in generative self-supervised learning (SSL) suggest that hypergraph neural networks learned from generative self supervision have the potential to effectively encode the complex hypergraph topology. Designing a generative SSL strategy for hypergraphs, however, is not straightforward. Questions remain with regard to its generative SSL task, connection to downstream tasks, and empirical properties of learned representations. In light of the promises and challenges, we propose a novel generative SSL strategy for hypergraphs. We first formulate a generative SSL task on hypergraphs, hyperedge filling, and highlight its theoretical connection to node classification. Based on the generative SSL task, we propose a hypergraph SSL method, HypeBoy. HypeBoy learns effective general-purpose hypergraph representations, outperforming 16 baseline methods across 11 benchmark datasets.
Feature Distribution on Graph Topology Mediates the Effect of Graph Convolution: Homophily Perspective
Feb 07, 2024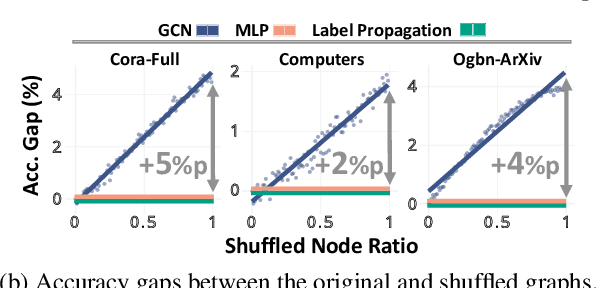
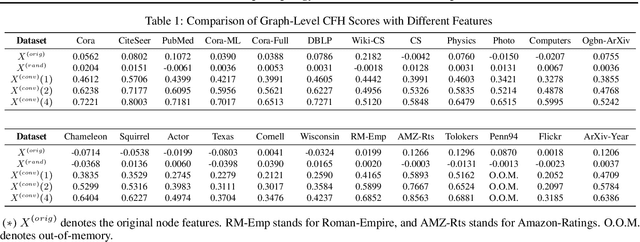
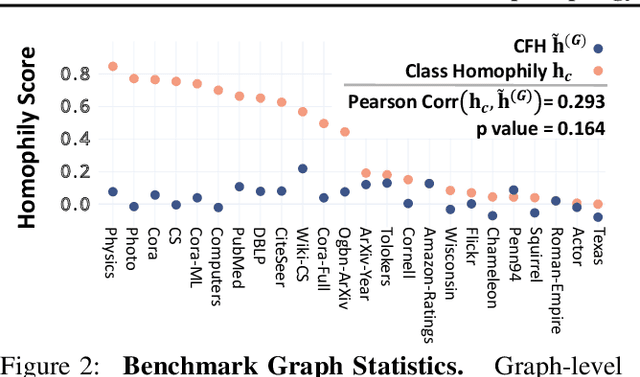
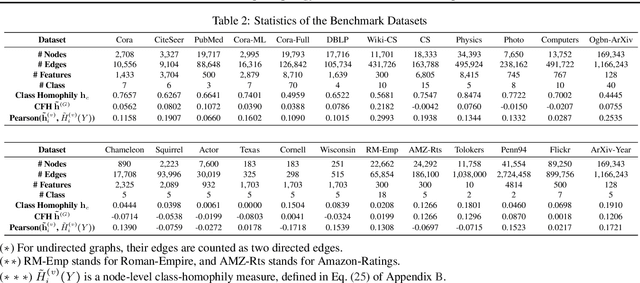
How would randomly shuffling feature vectors among nodes from the same class affect graph neural networks (GNNs)? The feature shuffle, intuitively, perturbs the dependence between graph topology and features (A-X dependence) for GNNs to learn from. Surprisingly, we observe a consistent and significant improvement in GNN performance following the feature shuffle. Having overlooked the impact of A-X dependence on GNNs, the prior literature does not provide a satisfactory understanding of the phenomenon. Thus, we raise two research questions. First, how should A-X dependence be measured, while controlling for potential confounds? Second, how does A-X dependence affect GNNs? In response, we (i) propose a principled measure for A-X dependence, (ii) design a random graph model that controls A-X dependence, (iii) establish a theory on how A-X dependence relates to graph convolution, and (iv) present empirical analysis on real-world graphs that aligns with the theory. We conclude that A-X dependence mediates the effect of graph convolution, such that smaller dependence improves GNN-based node classification.
Towards Deep Attention in Graph Neural Networks: Problems and Remedies
Jun 04, 2023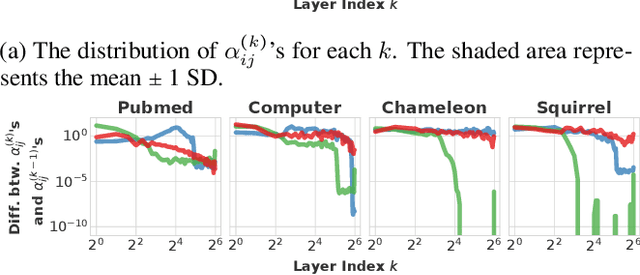

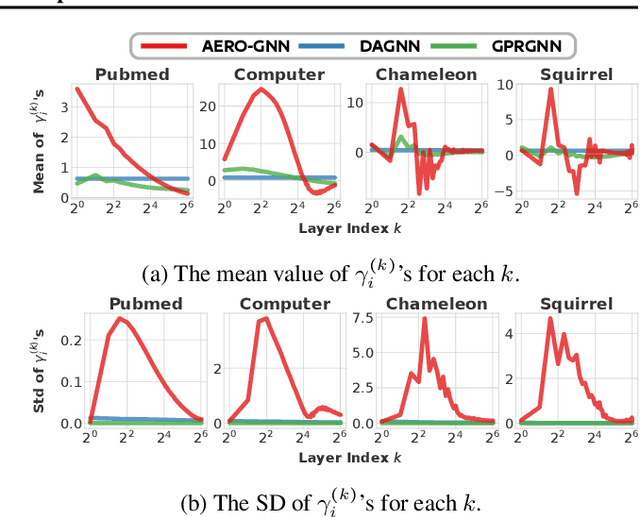
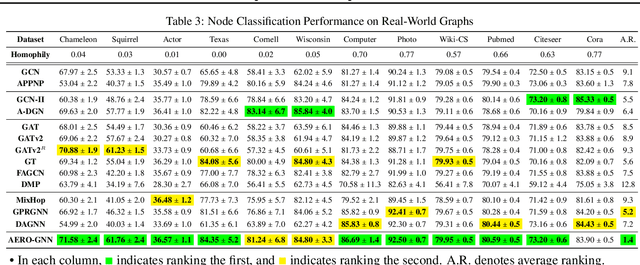
Graph neural networks (GNNs) learn the representation of graph-structured data, and their expressiveness can be further enhanced by inferring node relations for propagation. Attention-based GNNs infer neighbor importance to manipulate the weight of its propagation. Despite their popularity, the discussion on deep graph attention and its unique challenges has been limited. In this work, we investigate some problematic phenomena related to deep graph attention, including vulnerability to over-smoothed features and smooth cumulative attention. Through theoretical and empirical analyses, we show that various attention-based GNNs suffer from these problems. Motivated by our findings, we propose AEROGNN, a novel GNN architecture designed for deep graph attention. AERO-GNN provably mitigates the proposed problems of deep graph attention, which is further empirically demonstrated with (a) its adaptive and less smooth attention functions and (b) higher performance at deep layers (up to 64). On 9 out of 12 node classification benchmarks, AERO-GNN outperforms the baseline GNNs, highlighting the advantages of deep graph attention. Our code is available at https://github.com/syleeheal/AERO-GNN.