 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefluke: Federated Learning Utility frameworK for Experimentation and research
Dec 20, 2024

Since its inception in 2016, Federated Learning (FL) has been gaining tremendous popularity in the machine learning community. Several frameworks have been proposed to facilitate the development of FL algorithms, but researchers often resort to implementing their algorithms from scratch, including all baselines and experiments. This is because existing frameworks are not flexible enough to support their needs or the learning curve to extend them is too steep. In this paper, we present \fluke, a Python package designed to simplify the development of new FL algorithms. fluke is specifically designed for prototyping purposes and is meant for researchers or practitioners focusing on the learning components of a federated system. fluke is open-source, and it can be either used out of the box or extended with new algorithms with minimal overhead.
A Survey on Hypergraph Neural Networks: An In-Depth and Step-By-Step Guide
Apr 01, 2024



Higher-order interactions (HOIs) are ubiquitous in real-world complex systems and applications, and thus investigation of deep learning for HOIs has become a valuable agenda for the data mining and machine learning communities. As networks of HOIs are expressed mathematically as hypergraphs, hypergraph neural networks (HNNs) have emerged as a powerful tool for representation learning on hypergraphs. Given the emerging trend, we present the first survey dedicated to HNNs, with an in-depth and step-by-step guide. Broadly, the present survey overviews HNN architectures, training strategies, and applications. First, we break existing HNNs down into four design components: (i) input features, (ii) input structures, (iii) message-passing schemes, and (iv) training strategies. Second, we examine how HNNs address and learn HOIs with each of their components. Third, we overview the recent applications of HNNs in recommendation, biological and medical science, time series analysis, and computer vision. Lastly, we conclude with a discussion on limitations and future directions.
Experimenting with Emerging ARM and RISC-V Systems for Decentralised Machine Learning
Feb 15, 2023



Decentralised Machine Learning (DML) enables collaborative machine learning without centralised input data. Federated Learning (FL) and Edge Inference are examples of DML. While tools for DML (especially FL) are starting to flourish, many are not flexible and portable enough to experiment with novel systems (e.g., RISC-V), non-fully connected topologies, and asynchronous collaboration schemes. We overcome these limitations via a domain-specific language allowing to map DML schemes to an underlying middleware, i.e. the \ff parallel programming library. We experiment with it by generating different working DML schemes on two emerging architectures (ARM-v8, RISC-V) and the x86-64 platform. We characterise the performance and energy efficiency of the presented schemes and systems. As a byproduct, we introduce a RISC-V porting of the PyTorch framework, the first publicly available to our knowledge.
Novel Applications for VAE-based Anomaly Detection Systems
Apr 26, 2022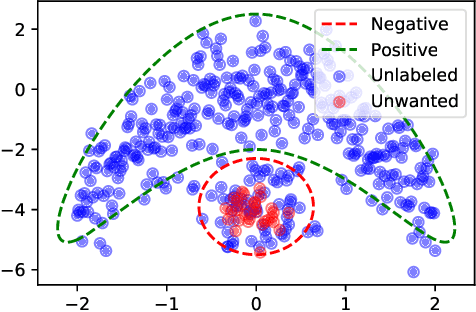
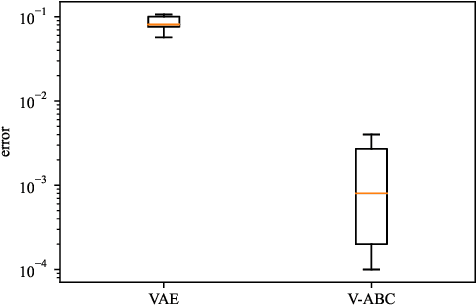
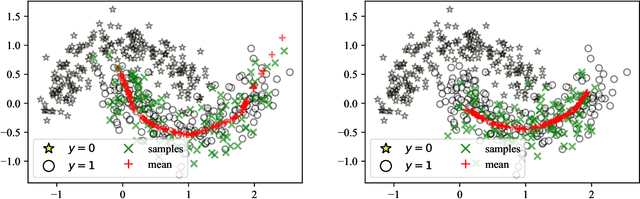
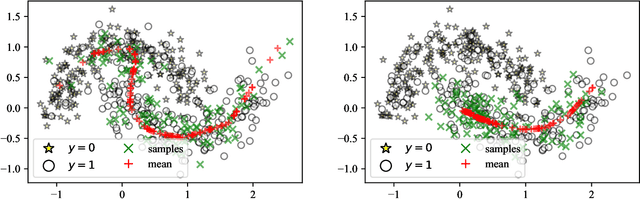
The recent rise in deep learning technologies fueled innovation and boosted scientific research. Their achievements enabled new research directions for deep generative modeling (DGM), an increasingly popular approach that can create novel and unseen data, starting from a given data set. As the technology shows promising applications, many ethical issues also arise. For example, their misuse can enable disinformation campaigns and powerful phishing attempts. Research also indicates different biases affect deep learning models, leading to social issues such as misrepresentation. In this work, we formulate a novel setting to deal with similar problems, showing that a repurposed anomaly detection system effectively generates novel data, avoiding generating specified unwanted data. We propose Variational Auto-encoding Binary Classifiers (V-ABC): a novel model that repurposes and extends the Auto-encoding Binary Classifier (ABC) anomaly detector, using the Variational Auto-encoder (VAE). We survey the limitations of existing approaches and explore many tools to show the model's inner workings in an interpretable way. This proposal has excellent potential for generative applications: models that rely on user-generated data could automatically filter out unwanted content, such as offensive language, obscene images, and misleading information.
Bayes Point Rule Set Learning
Apr 11, 2022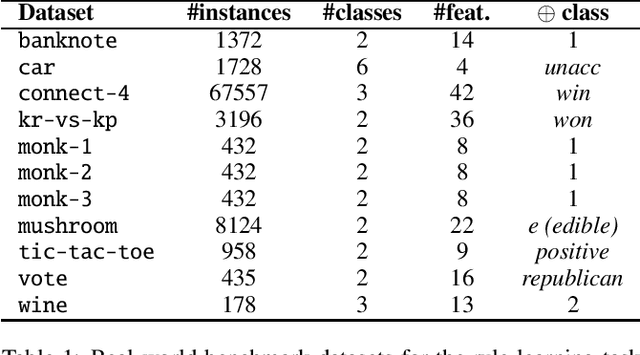
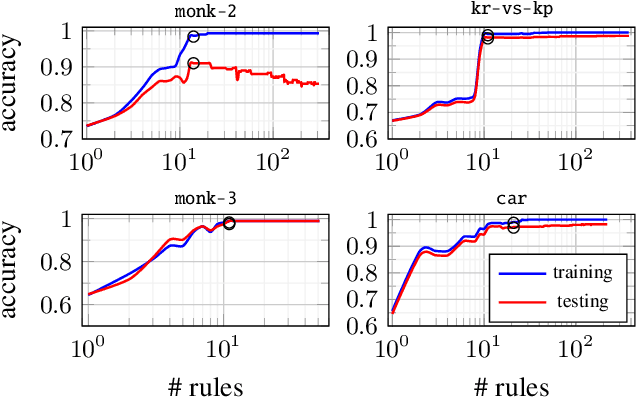

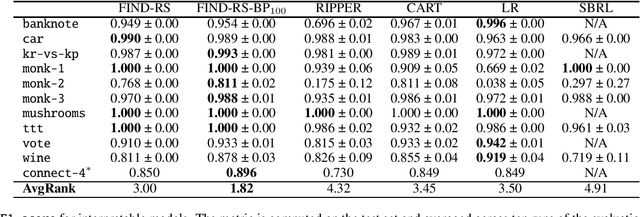
Interpretability is having an increasingly important role in the design of machine learning algorithms. However, interpretable methods tend to be less accurate than their black-box counterparts. Among others, DNFs (Disjunctive Normal Forms) are arguably the most interpretable way to express a set of rules. In this paper, we propose an effective bottom-up extension of the popular FIND-S algorithm to learn DNF-type rulesets. The algorithm greedily finds a partition of the positive examples. The produced DNF is a set of conjunctive rules, each corresponding to the most specific rule consistent with a part of positive and all negative examples. We also propose two principled extensions of this method, approximating the Bayes Optimal Classifier by aggregating DNF decision rules. Finally, we provide a methodology to significantly improve the explainability of the learned rules while retaining their generalization capabilities. An extensive comparison with state-of-the-art symbolic and statistical methods on several benchmark data sets shows that our proposal provides an excellent balance between explainability and accuracy.
Conditioned Variational Autoencoder for top-N item recommendation
May 04, 2020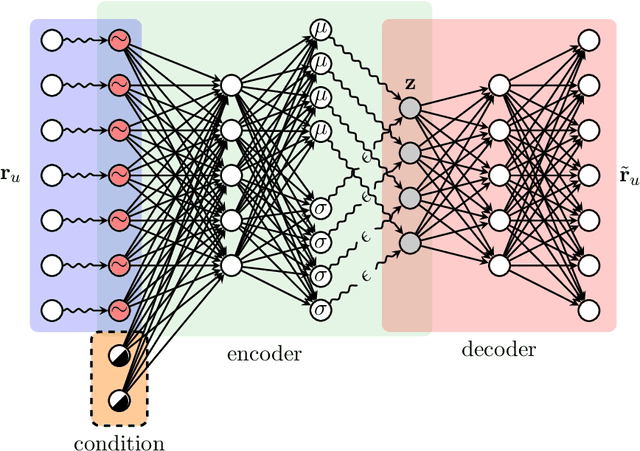
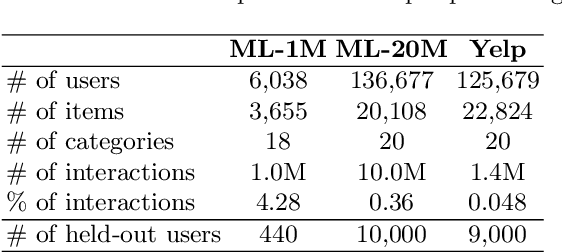


In this paper, we propose a Conditioned Variational Autoencoder (C-VAE) for constrained top-N item recommendation where the recommended items must satisfy a given condition. The proposed model architecture is similar to a standard VAE in which the condition vector is fed into the encoder. The constrained ranking is learned during training thanks to a new reconstruction loss that takes the input condition into account. We show that our model generalizes the state-of-the-art Mult-VAE collaborative filtering model. Moreover, we provide insights on what C-VAE learns in the latent space, providing a human-friendly interpretation. Experimental results underline the potential of C-VAE in providing accurate recommendations under constraints. Finally, the performed analyses suggest that C-VAE can be used in other recommendation scenarios, such as context-aware recommendation.
Interpretable preference learning: a game theoretic framework for large margin on-line feature and rule learning
Dec 19, 2018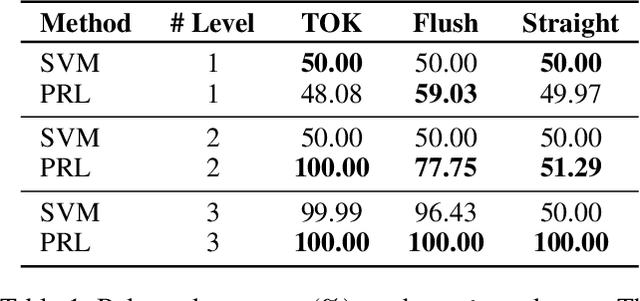
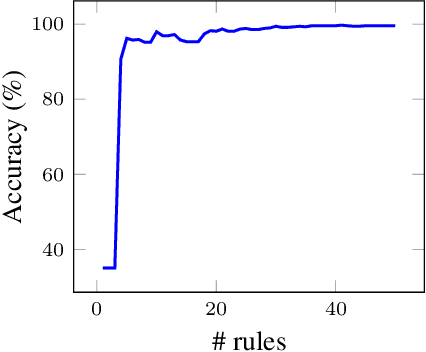
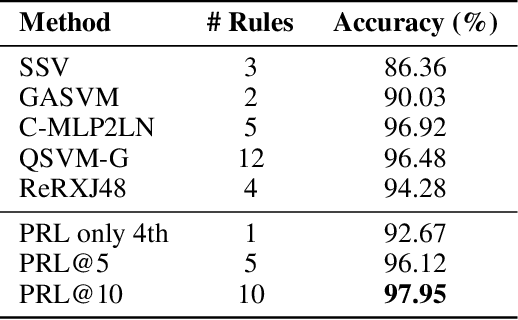
A large body of research is currently investigating on the connection between machine learning and game theory. In this work, game theory notions are injected into a preference learning framework. Specifically, a preference learning problem is seen as a two-players zero-sum game. An algorithm is proposed to incrementally include new useful features into the hypothesis. This can be particularly important when dealing with a very large number of potential features like, for instance, in relational learning and rule extraction. A game theoretical analysis is used to demonstrate the convergence of the algorithm. Furthermore, leveraging on the natural analogy between features and rules, the resulting models can be easily interpreted by humans. An extensive set of experiments on classification tasks shows the effectiveness of the proposed method in terms of interpretability and feature selection quality, with accuracy at the state-of-the-art.
LSTM Networks for Data-Aware Remaining Time Prediction of Business Process Instances
Nov 10, 2017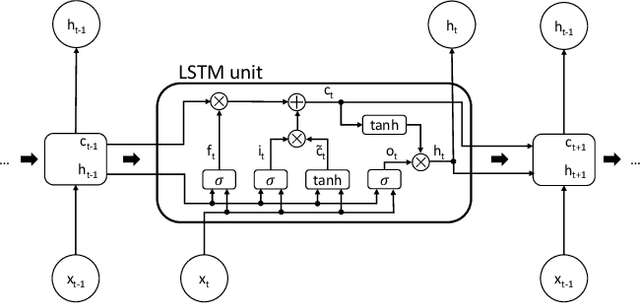
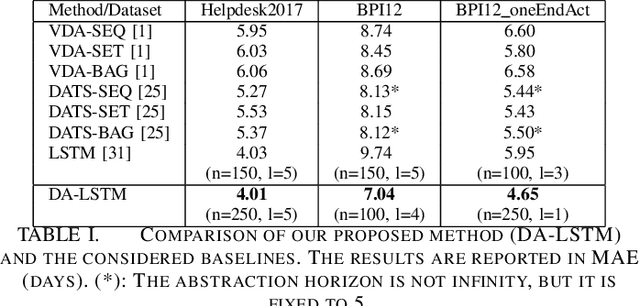
Predicting the completion time of business process instances would be a very helpful aid when managing processes under service level agreement constraints. The ability to know in advance the trend of running process instances would allow business managers to react in time, in order to prevent delays or undesirable situations. However, making such accurate forecasts is not easy: many factors may influence the required time to complete a process instance. In this paper, we propose an approach based on deep Recurrent Neural Networks (specifically LSTMs) that is able to exploit arbitrary information associated to single events, in order to produce an as-accurate-as-possible prediction of the completion time of running instances. Experiments on real-world datasets confirm the quality of our proposal.
Boolean kernels for collaborative filtering in top-N item recommendation
Jul 18, 2017
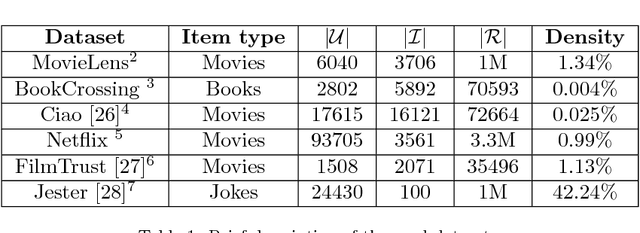
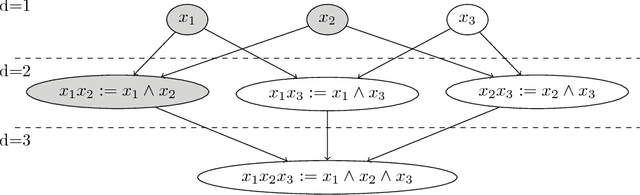
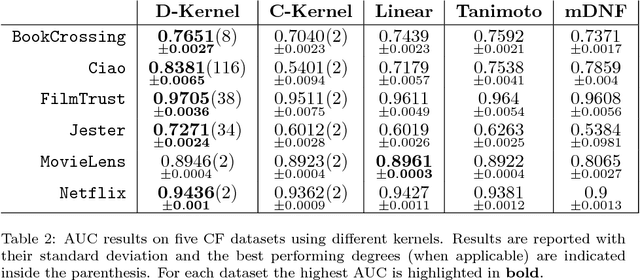
In many personalized recommendation problems available data consists only of positive interactions (implicit feedback) between users and items. This problem is also known as One-Class Collaborative Filtering (OC-CF). Linear models usually achieve state-of-the-art performances on OC-CF problems and many efforts have been devoted to build more expressive and complex representations able to improve the recommendations. Recent analysis show that collaborative filtering (CF) datasets have peculiar characteristics such as high sparsity and a long tailed distribution of the ratings. In this paper we propose a boolean kernel, called Disjunctive kernel, which is less expressive than the linear one but it is able to alleviate the sparsity issue in CF contexts. The embedding of this kernel is composed by all the combinations of a certain arity d of the input variables, and these combined features are semantically interpreted as disjunctions of the input variables. Experiments on several CF datasets show the effectiveness and the efficiency of the proposed kernel.
Exploiting sparsity to build efficient kernel based collaborative filtering for top-N item recommendation
Dec 17, 2016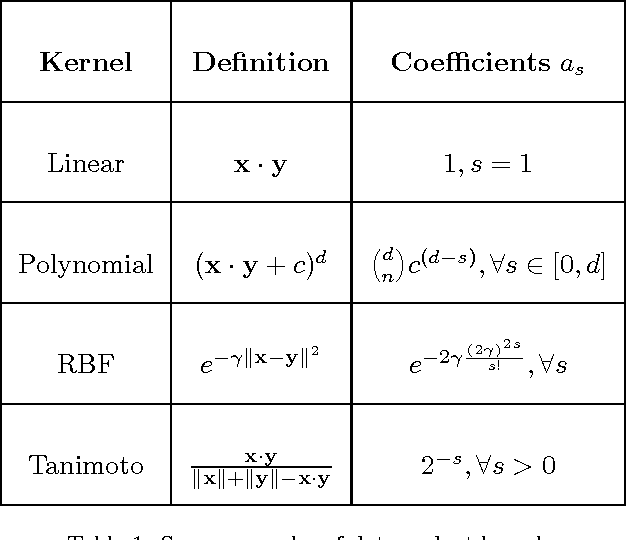
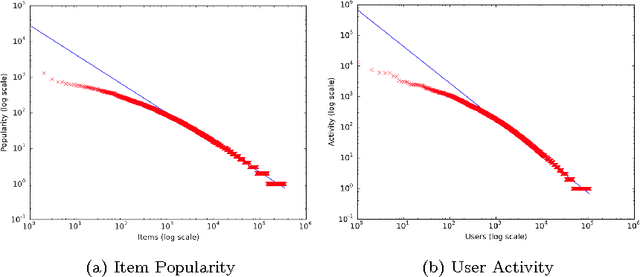
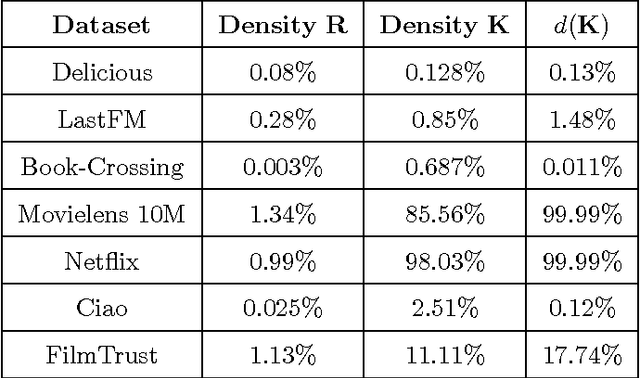
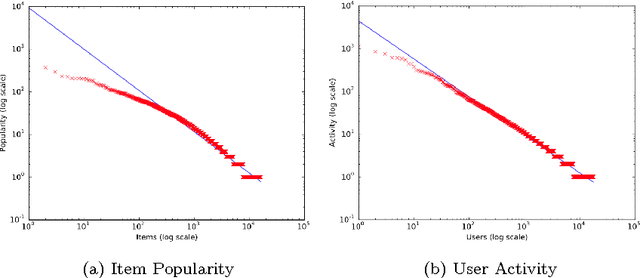
The increasing availability of implicit feedback datasets has raised the interest in developing effective collaborative filtering techniques able to deal asymmetrically with unambiguous positive feedback and ambiguous negative feedback. In this paper, we propose a principled kernel-based collaborative filtering method for top-N item recommendation with implicit feedback. We present an efficient implementation using the linear kernel, and we show how to generalize it to kernels of the dot product family preserving the efficiency. We also investigate on the elements which influence the sparsity of a standard cosine kernel. This analysis shows that the sparsity of the kernel strongly depends on the properties of the dataset, in particular on the long tail distribution. We compare our method with state-of-the-art algorithms achieving good results both in terms of efficiency and effectiveness.