 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermining Energy Efficiency Sweet Spots in Production LLM Inference
Feb 05, 2026Large Language Models (LLMs) inference is central in modern AI applications, making it critical to understand their energy footprint. Existing approaches typically estimate energy consumption through simple linear functions of input and output sequence lengths, yet our observations reveal clear Energy Efficiency regimes: peak efficiency occurs with short-to-moderate inputs and medium-length outputs, while efficiency drops sharply for long inputs or very short outputs, indicating a non-linear dependency. In this work, we propose an analytical model derived from the computational and memory-access complexity of the Transformer architecture, capable of accurately characterizing the efficiency curve as a function of input and output lengths. To assess its accuracy, we evaluate energy consumption using TensorRT-LLM on NVIDIA H100 GPUs across a diverse set of LLMs ranging from 1B to 9B parameters, including OPT, LLaMA, Gemma, Falcon, Qwen2, and Granite, tested over input and output lengths from 64 to 4096 tokens, achieving a mean MAPE of 1.79%. Our results show that aligning sequence lengths with these efficiency "Sweet Spots" can substantially reduce energy usage, supporting informed truncation, summarization, and adaptive generation strategies in production systems.
Assessing Tenstorrent's RISC-V MatMul Acceleration Capabilities
May 09, 2025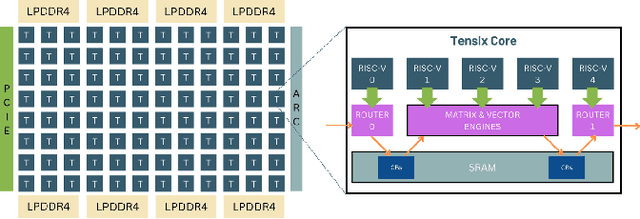

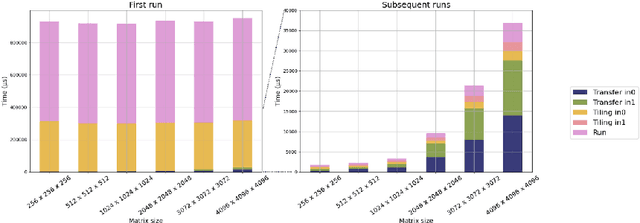
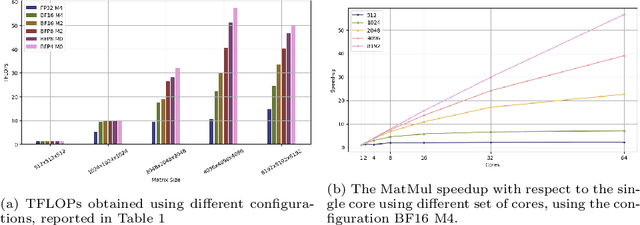
The increasing demand for generative AI as Large Language Models (LLMs) services has driven the need for specialized hardware architectures that optimize computational efficiency and energy consumption. This paper evaluates the performance of the Tenstorrent Grayskull e75 RISC-V accelerator for basic linear algebra kernels at reduced numerical precision, a fundamental operation in LLM computations. We present a detailed characterization of Grayskull's execution model, gridsize, matrix dimensions, data formats, and numerical precision impact computational efficiency. Furthermore, we compare Grayskull's performance against state-of-the-art architectures with tensor acceleration, including Intel Sapphire Rapids processors and two NVIDIA GPUs (V100 and A100). Whilst NVIDIA GPUs dominate raw performance, Grayskull demonstrates a competitive trade-off between power consumption and computational throughput, reaching a peak of 1.55 TFLOPs/Watt with BF16.
Unleashing OpenTitan's Potential: a Silicon-Ready Embedded Secure Element for Root of Trust and Cryptographic Offloading
Jun 17, 2024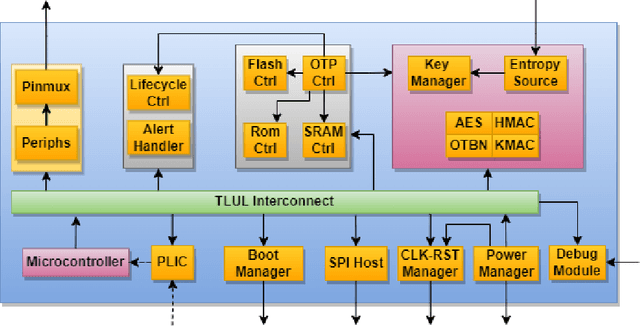

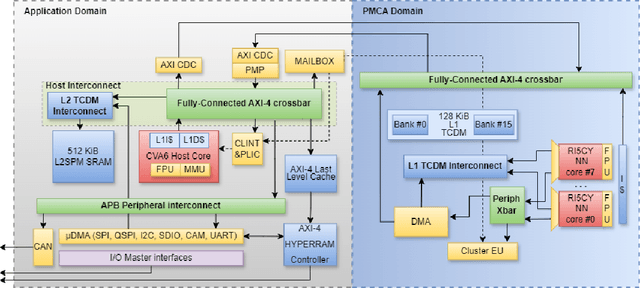
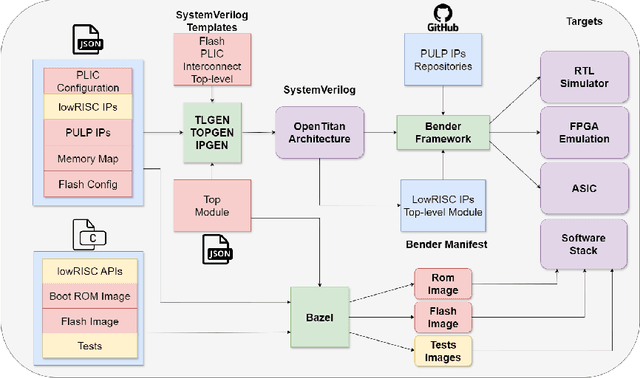
The rapid advancement and exploration of open-hardware RISC-V platforms are driving significant changes in sectors like autonomous vehicles, smart-city infrastructure, and medical devices. OpenTitan stands out as a groundbreaking open-source RISC-V design with a comprehensive security toolkit as a standalone system-on-chip (SoC). OpenTitan includes Earl Grey, a fully implemented and silicon-proven SoC, and Darjeeling, announced but not yet fully implemented. Earl Grey targets standalone SoC implementations, while Darjeeling is for integrable implementations. The literature lacks a silicon-ready embedded implementation of an open-source Root of Trust, despite lowRISC's efforts on Darjeeling. We address the limitations of existing implementations by optimizing data transfer latency between memory and cryptographic accelerators to prevent under-utilization and ensure efficient task acceleration. Our contributions include a comprehensive methodology for integrating custom extensions and IPs into the Earl Grey architecture, architectural enhancements for system-level integration, support for varied boot modes, and improved data movement across the platform. These advancements facilitate deploying OpenTitan in broader SoCs, even without specific technology-dependent IPs, providing a deployment-ready research vehicle for the community. We integrated the extended Earl Grey architecture into a reference architecture in a 22nm FDX technology node, benchmarking the enhanced architecture's performance. The results show significant improvements in cryptographic processing speed, achieving up to 2.7x speedup for SHA-256/HMAC and 1.6x for AES accelerators compared to the baseline Earl Grey architecture.
DECICE: Device-Edge-Cloud Intelligent Collaboration Framework
May 04, 2023



DECICE is a Horizon Europe project that is developing an AI-enabled open and portable management framework for automatic and adaptive optimization and deployment of applications in computing continuum encompassing from IoT sensors on the Edge to large-scale Cloud / HPC computing infrastructures. In this paper, we describe the DECICE framework and architecture. Furthermore, we highlight use-cases for framework evaluation: intelligent traffic intersection, magnetic resonance imaging, and emergency response.
Experimenting with Emerging ARM and RISC-V Systems for Decentralised Machine Learning
Feb 15, 2023



Decentralised Machine Learning (DML) enables collaborative machine learning without centralised input data. Federated Learning (FL) and Edge Inference are examples of DML. While tools for DML (especially FL) are starting to flourish, many are not flexible and portable enough to experiment with novel systems (e.g., RISC-V), non-fully connected topologies, and asynchronous collaboration schemes. We overcome these limitations via a domain-specific language allowing to map DML schemes to an underlying middleware, i.e. the \ff parallel programming library. We experiment with it by generating different working DML schemes on two emerging architectures (ARM-v8, RISC-V) and the x86-64 platform. We characterise the performance and energy efficiency of the presented schemes and systems. As a byproduct, we introduce a RISC-V porting of the PyTorch framework, the first publicly available to our knowledge.
RUAD: unsupervised anomaly detection in HPC systems
Aug 28, 2022
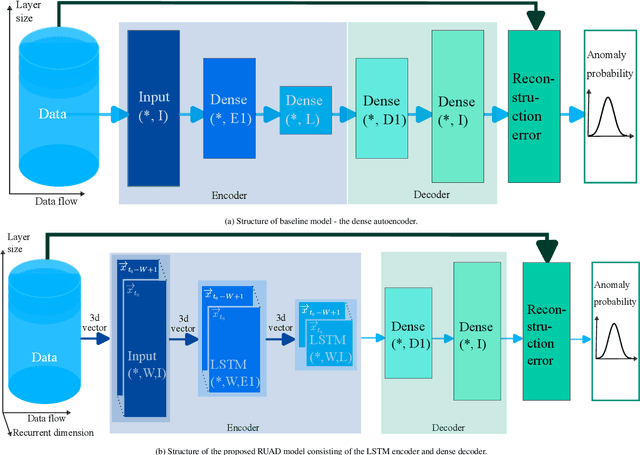


The increasing complexity of modern high-performance computing (HPC) systems necessitates the introduction of automated and data-driven methodologies to support system administrators' effort toward increasing the system's availability. Anomaly detection is an integral part of improving the availability as it eases the system administrator's burden and reduces the time between an anomaly and its resolution. However, current state-of-the-art (SoA) approaches to anomaly detection are supervised and semi-supervised, so they require a human-labelled dataset with anomalies - this is often impractical to collect in production HPC systems. Unsupervised anomaly detection approaches based on clustering, aimed at alleviating the need for accurate anomaly data, have so far shown poor performance. In this work, we overcome these limitations by proposing RUAD, a novel Recurrent Unsupervised Anomaly Detection model. RUAD achieves better results than the current semi-supervised and unsupervised SoA approaches. This is achieved by considering temporal dependencies in the data and including long-short term memory cells in the model architecture. The proposed approach is assessed on a complete ten-month history of a Tier-0 system (Marconi100 from CINECA with 980 nodes). RUAD achieves an area under the curve (AUC) of 0.763 in semi-supervised training and an AUC of 0.767 in unsupervised training, which improves upon the SoA approach that achieves an AUC of 0.747 in semi-supervised training and an AUC of 0.734 in unsupervised training. It also vastly outperforms the current SoA unsupervised anomaly detection approach based on clustering, achieving the AUC of 0.548.
Source Code Classification for Energy Efficiency in Parallel Ultra Low-Power Microcontrollers
Dec 12, 2020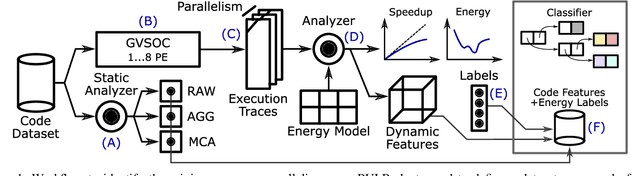
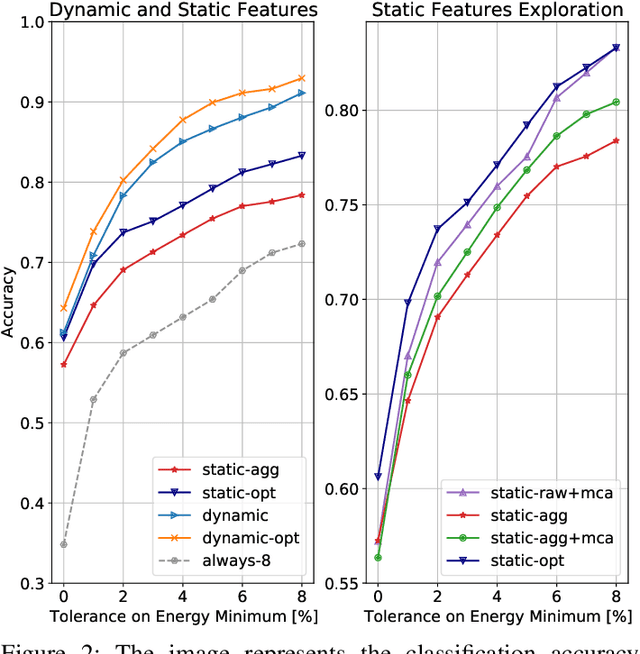
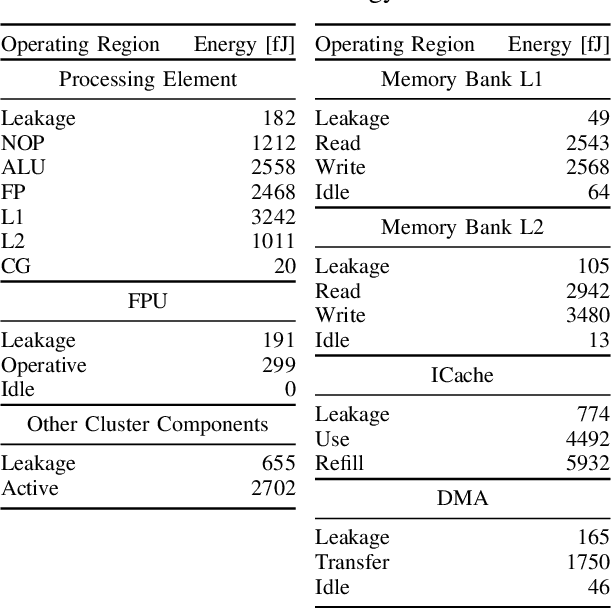

The analysis of source code through machine learning techniques is an increasingly explored research topic aiming at increasing smartness in the software toolchain to exploit modern architectures in the best possible way. In the case of low-power, parallel embedded architectures, this means finding the configuration, for instance in terms of the number of cores, leading to minimum energy consumption. Depending on the kernel to be executed, the energy optimal scaling configuration is not trivial. While recent work has focused on general-purpose systems to learn and predict the best execution target in terms of the execution time of a snippet of code or kernel (e.g. offload OpenCL kernel on multicore CPU or GPU), in this work we focus on static compile-time features to assess if they can be successfully used to predict the minimum energy configuration on PULP, an ultra-low-power architecture featuring an on-chip cluster of RISC-V processors. Experiments show that using machine learning models on the source code to select the best energy scaling configuration automatically is viable and has the potential to be used in the context of automatic system configuration for energy minimisation.
A Machine Learning Approach to Online Fault Classification in HPC Systems
Jul 27, 2020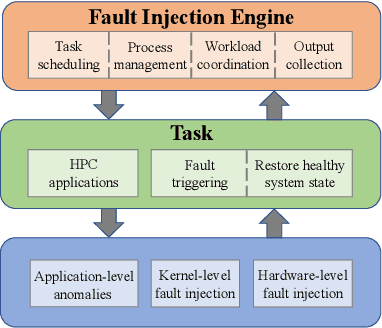
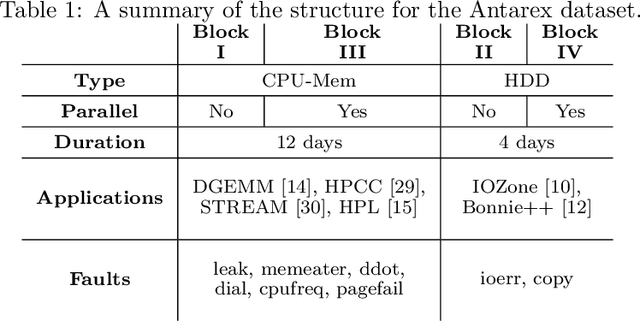
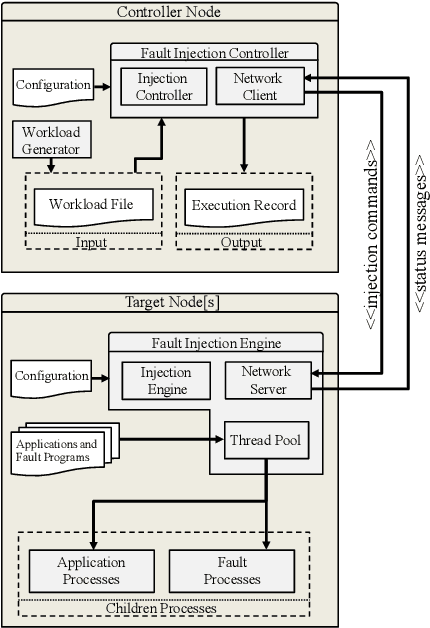

As High-Performance Computing (HPC) systems strive towards the exascale goal, failure rates both at the hardware and software levels will increase significantly. Thus, detecting and classifying faults in HPC systems as they occur and initiating corrective actions before they can transform into failures becomes essential for continued operation. Central to this objective is fault injection, which is the deliberate triggering of faults in a system so as to observe their behavior in a controlled environment. In this paper, we propose a fault classification method for HPC systems based on machine learning. The novelty of our approach rests with the fact that it can be operated on streamed data in an online manner, thus opening the possibility to devise and enact control actions on the target system in real-time. We introduce a high-level, easy-to-use fault injection tool called FINJ, with a focus on the management of complex experiments. In order to train and evaluate our machine learning classifiers, we inject faults to an in-house experimental HPC system using FINJ, and generate a fault dataset which we describe extensively. Both FINJ and the dataset are publicly available to facilitate resiliency research in the HPC systems field. Experimental results demonstrate that our approach allows almost perfect classification accuracy to be reached for different fault types with low computational overhead and minimal delay.
* arXiv admin note: text overlap with arXiv:1807.10056, arXiv:1810.11208
pAElla: Edge-AI based Real-Time Malware Detection in Data Centers
Apr 07, 2020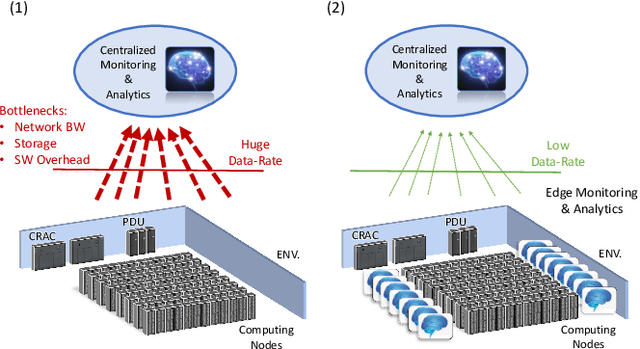
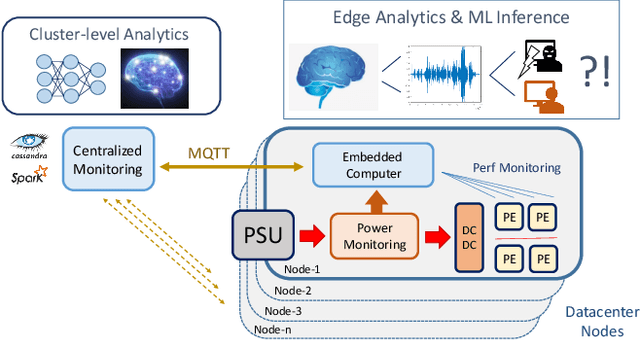
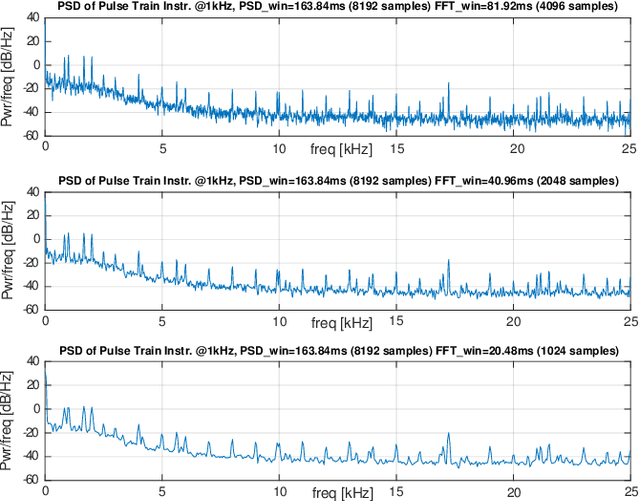
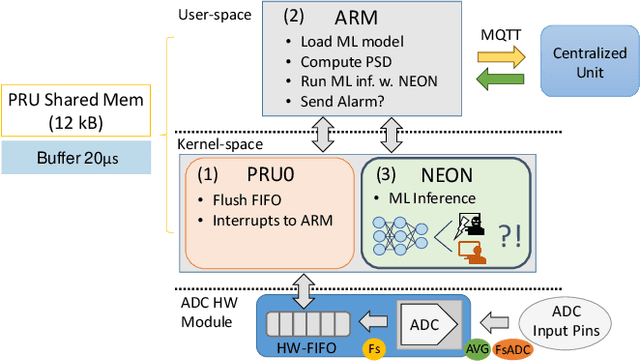
The increasing use of Internet-of-Things (IoT) devices for monitoring a wide spectrum of applications, along with the challenges of "big data" streaming support they often require for data analysis, is nowadays pushing for an increased attention to the emerging edge computing paradigm. In particular, smart approaches to manage and analyze data directly on the network edge, are more and more investigated, and Artificial Intelligence (AI) powered edge computing is envisaged to be a promising direction. In this paper, we focus on Data Centers (DCs) and Supercomputers (SCs), where a new generation of high-resolution monitoring systems is being deployed, opening new opportunities for analysis like anomaly detection and security, but introducing new challenges for handling the vast amount of data it produces. In detail, we report on a novel lightweight and scalable approach to increase the security of DCs/SCs, that involves AI-powered edge computing on high-resolution power consumption. The method -- called pAElla -- targets real-time Malware Detection (MD), it runs on an out-of-band IoT-based monitoring system for DCs/SCs, and involves Power Spectral Density of power measurements, along with AutoEncoders. Results are promising, with an F1-score close to 1, and a False Alarm and Malware Miss rate close to 0%. We compare our method with State-of-the-Art MD techniques and show that, in the context of DCs/SCs, pAElla can cover a wider range of malware, significantly outperforming SoA approaches in terms of accuracy. Moreover, we propose a methodology for online training suitable for DCs/SCs in production, and release open dataset and code.
Anomaly Detection using Autoencoders in High Performance Computing Systems
Nov 13, 2018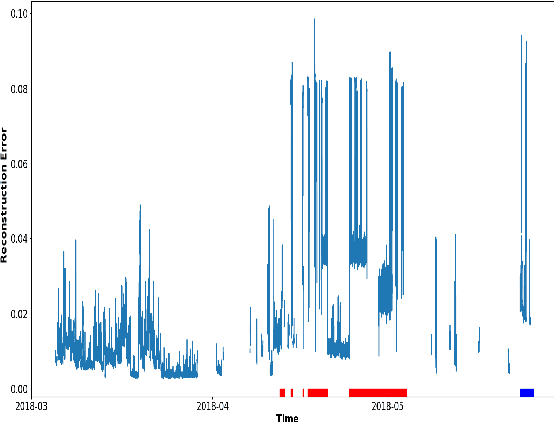
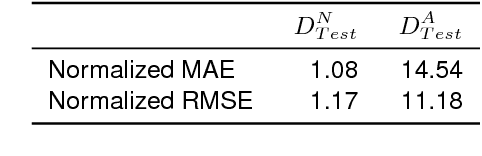
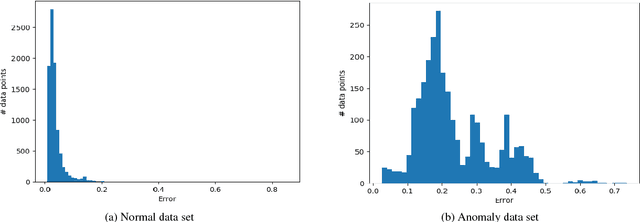
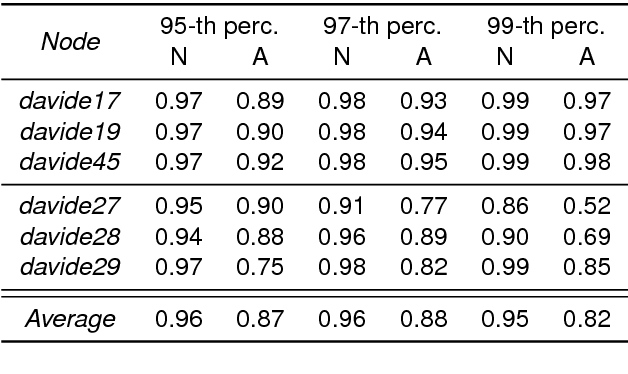
Anomaly detection in supercomputers is a very difficult problem due to the big scale of the systems and the high number of components. The current state of the art for automated anomaly detection employs Machine Learning methods or statistical regression models in a supervised fashion, meaning that the detection tool is trained to distinguish among a fixed set of behaviour classes (healthy and unhealthy states). We propose a novel approach for anomaly detection in High Performance Computing systems based on a Machine (Deep) Learning technique, namely a type of neural network called autoencoder. The key idea is to train a set of autoencoders to learn the normal (healthy) behaviour of the supercomputer nodes and, after training, use them to identify abnormal conditions. This is different from previous approaches which where based on learning the abnormal condition, for which there are much smaller datasets (since it is very hard to identify them to begin with). We test our approach on a real supercomputer equipped with a fine-grained, scalable monitoring infrastructure that can provide large amount of data to characterize the system behaviour. The results are extremely promising: after the training phase to learn the normal system behaviour, our method is capable of detecting anomalies that have never been seen before with a very good accuracy (values ranging between 88% and 96%).