 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Approach to Online Fault Classification in HPC Systems
Jul 27, 2020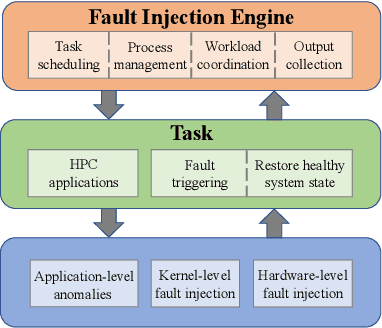
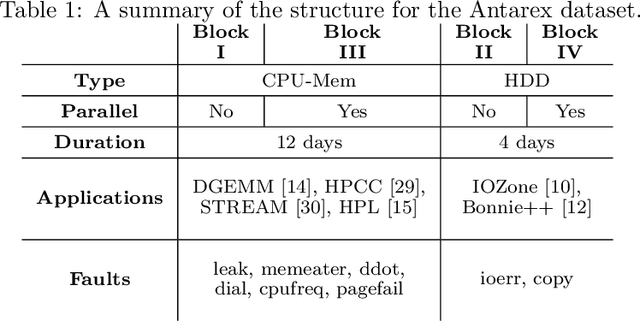
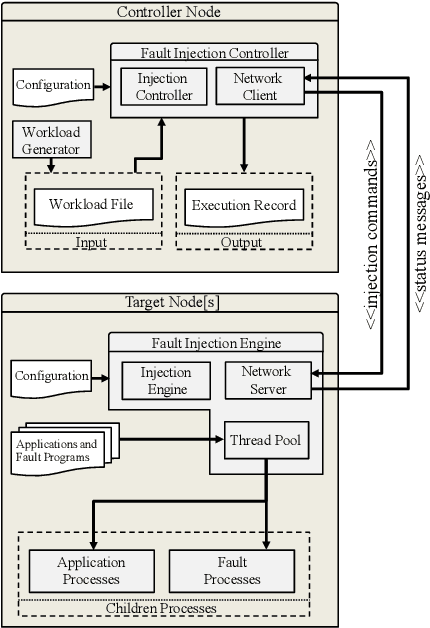

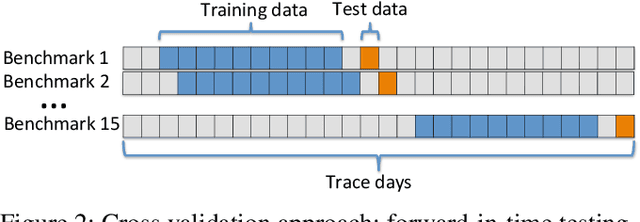
As High-Performance Computing (HPC) systems strive towards the exascale goal, failure rates both at the hardware and software levels will increase significantly. Thus, detecting and classifying faults in HPC systems as they occur and initiating corrective actions before they can transform into failures becomes essential for continued operation. Central to this objective is fault injection, which is the deliberate triggering of faults in a system so as to observe their behavior in a controlled environment. In this paper, we propose a fault classification method for HPC systems based on machine learning. The novelty of our approach rests with the fact that it can be operated on streamed data in an online manner, thus opening the possibility to devise and enact control actions on the target system in real-time. We introduce a high-level, easy-to-use fault injection tool called FINJ, with a focus on the management of complex experiments. In order to train and evaluate our machine learning classifiers, we inject faults to an in-house experimental HPC system using FINJ, and generate a fault dataset which we describe extensively. Both FINJ and the dataset are publicly available to facilitate resiliency research in the HPC systems field. Experimental results demonstrate that our approach allows almost perfect classification accuracy to be reached for different fault types with low computational overhead and minimal delay.
* arXiv admin note: text overlap with arXiv:1807.10056, arXiv:1810.11208
Towards Data-Driven Autonomics in Data Centers
Jul 06, 2015
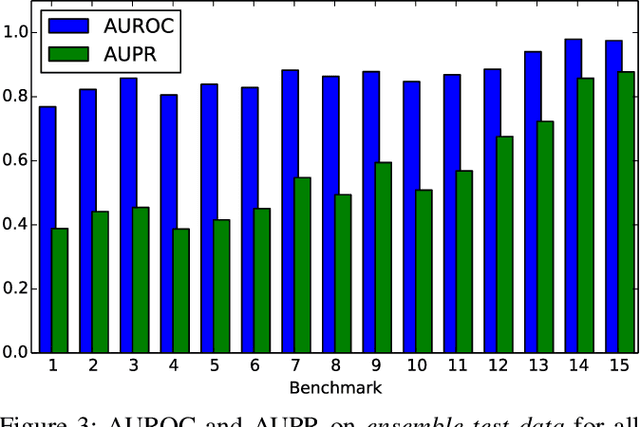

Continued reliance on human operators for managing data centers is a major impediment for them from ever reaching extreme dimensions. Large computer systems in general, and data centers in particular, will ultimately be managed using predictive computational and executable models obtained through data-science tools, and at that point, the intervention of humans will be limited to setting high-level goals and policies rather than performing low-level operations. Data-driven autonomics, where management and control are based on holistic predictive models that are built and updated using generated data, opens one possible path towards limiting the role of operators in data centers. In this paper, we present a data-science study of a public Google dataset collected in a 12K-node cluster with the goal of building and evaluating a predictive model for node failures. We use BigQuery, the big data SQL platform from the Google Cloud suite, to process massive amounts of data and generate a rich feature set characterizing machine state over time. We describe how an ensemble classifier can be built out of many Random Forest classifiers each trained on these features, to predict if machines will fail in a future 24-hour window. Our evaluation reveals that if we limit false positive rates to 5%, we can achieve true positive rates between 27% and 88% with precision varying between 50% and 72%. We discuss the practicality of including our predictive model as the central component of a data-driven autonomic manager and operating it on-line with live data streams (rather than off-line on data logs). All of the scripts used for BigQuery and classification analyses are publicly available from the authors' website.