 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrelation-wise Smoothing: Lightweight Knowledge Extraction for HPC Monitoring Data
Oct 13, 2020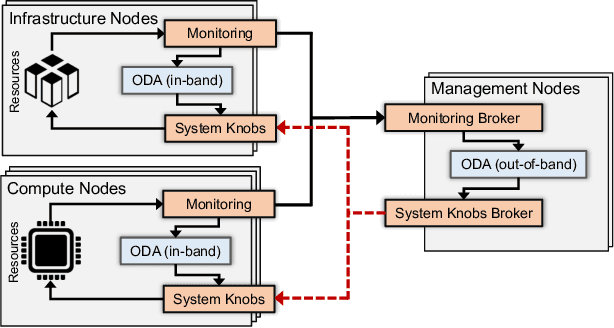
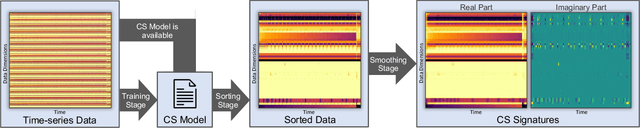
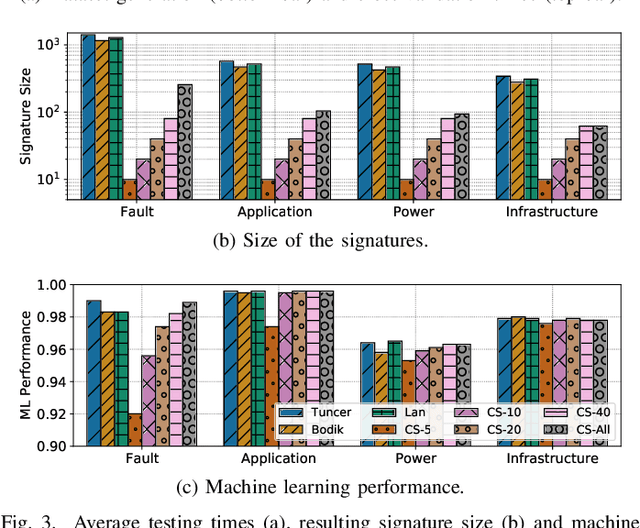
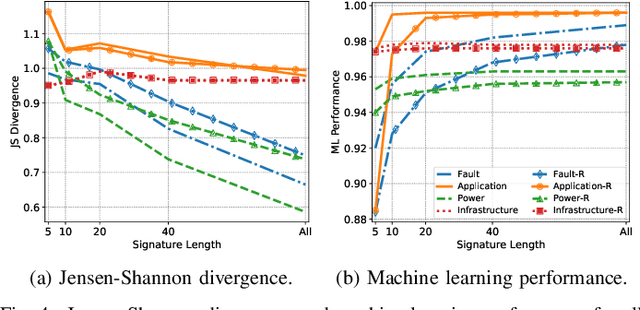
Modern High-Performance Computing (HPC) and data center operators rely more and more on data analytics techniques to improve the efficiency and reliability of their operations. They employ models that ingest time-series monitoring sensor data and transform it into actionable knowledge for system tuning: a process known as Operational Data Analytics (ODA). However, monitoring data has a high dimensionality, is hardware-dependent and difficult to interpret. This, coupled with the strict requirements of ODA, makes most traditional data mining methods impractical and in turn renders this type of data cumbersome to process. Most current ODA solutions use ad-hoc processing methods that are not generic, are sensible to the sensors' features and are not fit for visualization. In this paper we propose a novel method, called Correlation-wise Smoothing (CS), to extract descriptive signatures from time-series monitoring data in a generic and lightweight way. Our CS method exploits correlations between data dimensions to form groups and produces image-like signatures that can be easily manipulated, visualized and compared. We evaluate the CS method on HPC-ODA, a collection of datasets that we release with this work, and show that it leads to the same performance as most state-of-the-art methods while producing signatures that are up to ten times smaller and up to ten times faster, while gaining visualizability, portability across systems and clear scaling properties.
A Machine Learning Approach to Online Fault Classification in HPC Systems
Jul 27, 2020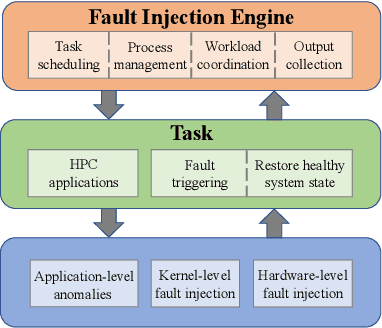
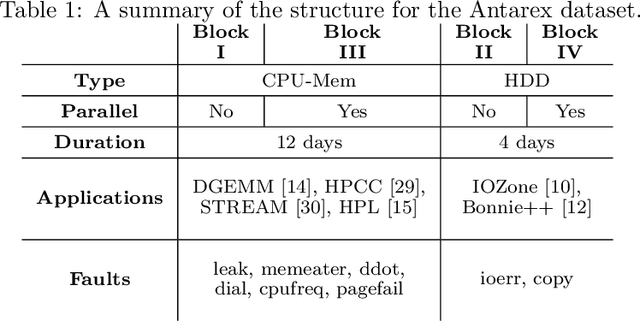
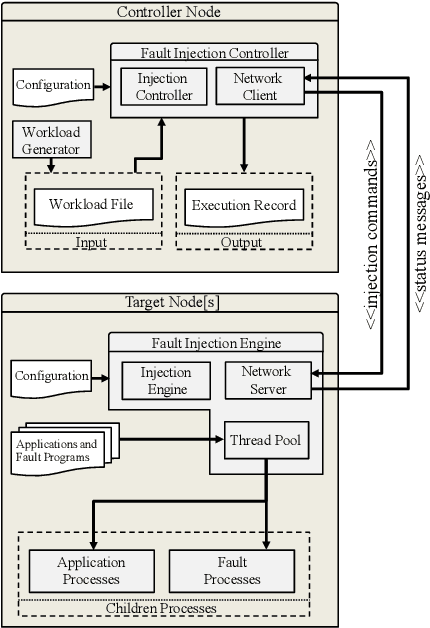

As High-Performance Computing (HPC) systems strive towards the exascale goal, failure rates both at the hardware and software levels will increase significantly. Thus, detecting and classifying faults in HPC systems as they occur and initiating corrective actions before they can transform into failures becomes essential for continued operation. Central to this objective is fault injection, which is the deliberate triggering of faults in a system so as to observe their behavior in a controlled environment. In this paper, we propose a fault classification method for HPC systems based on machine learning. The novelty of our approach rests with the fact that it can be operated on streamed data in an online manner, thus opening the possibility to devise and enact control actions on the target system in real-time. We introduce a high-level, easy-to-use fault injection tool called FINJ, with a focus on the management of complex experiments. In order to train and evaluate our machine learning classifiers, we inject faults to an in-house experimental HPC system using FINJ, and generate a fault dataset which we describe extensively. Both FINJ and the dataset are publicly available to facilitate resiliency research in the HPC systems field. Experimental results demonstrate that our approach allows almost perfect classification accuracy to be reached for different fault types with low computational overhead and minimal delay.
* arXiv admin note: text overlap with arXiv:1807.10056, arXiv:1810.11208
DCDB Wintermute: Enabling Online and Holistic Operational Data Analytics on HPC Systems
Oct 14, 2019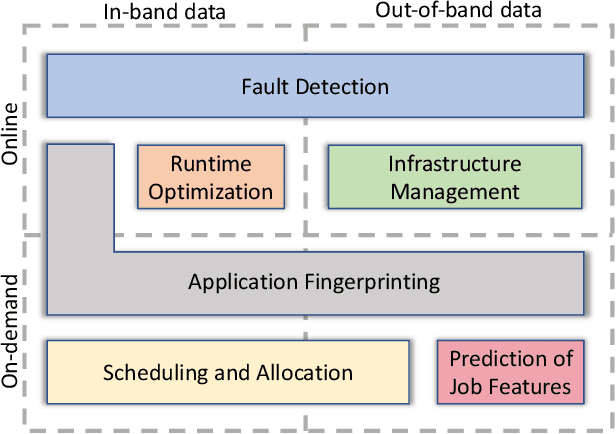
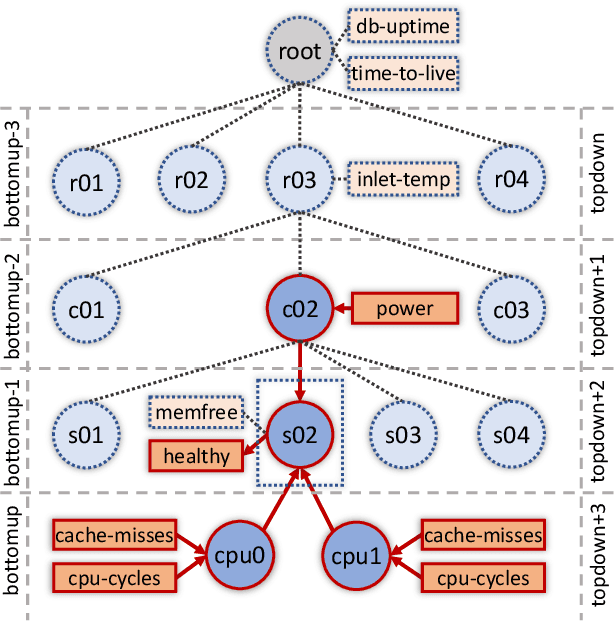
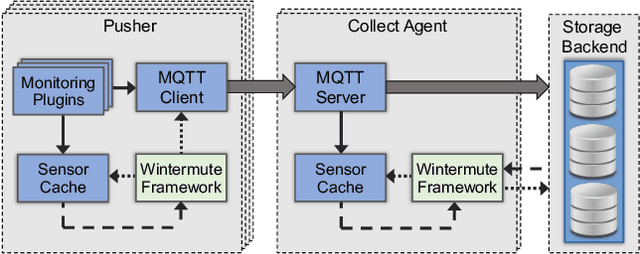
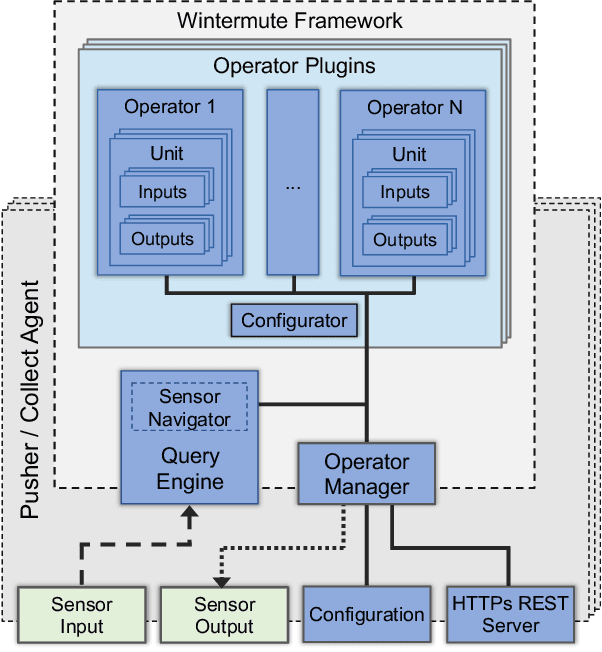
The complexity of today's HPC systems increases as we move closer to the exascale goal, raising concerns about their sustainability. In an effort to improve their efficiency and effectiveness, more and more HPC installations are experimenting with fine-grained monitoring coupled with Operational Data Analytics (ODA) to drive resource management decisions. However, while monitoring is an established reality in HPC, no generic framework exists to enable holistic and online operational data analytics, leading to insular ad-hoc solutions each addressing only specific aspects of the problem. In this paper we propose Wintermute, a novel operational data analytics framework for HPC installations, built upon the holistic DCDB monitoring system. Wintermute is designed following a survey of common operational requirements, and as such offers a large variety of configuration options to accommodate these varying requirements. Moreover, Wintermute is based on a set of logical abstractions to ease the configuration of models at a large scale and maximize code re-use. We highlight Wintermute's flexibility through a series of case studies, each targeting a different aspect of the management of HPC systems, and demonstrate its small resource footprint.