 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Machine Learning Pipeline for Multiple Sclerosis Biomarker Discovery: Comparing explainable AI and Traditional Statistical Approaches
Sep 26, 2025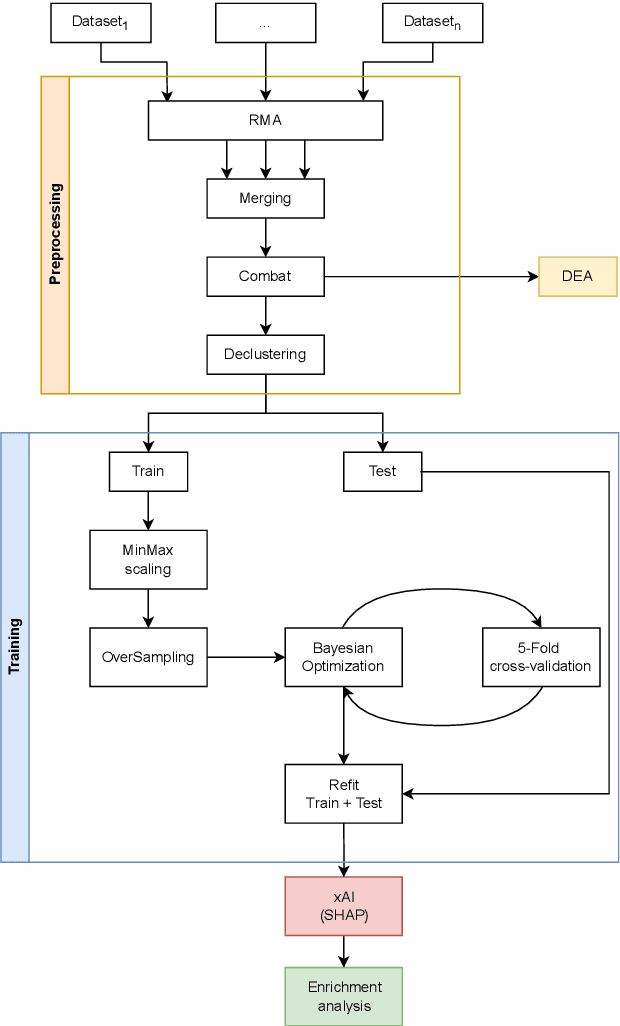

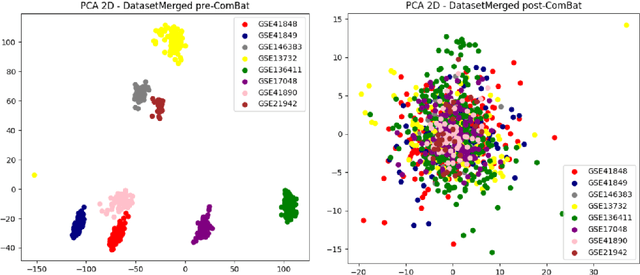
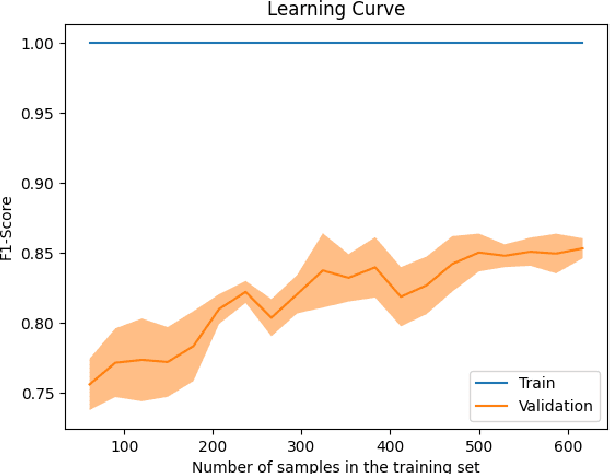
We present a machine learning pipeline for biomarker discovery in Multiple Sclerosis (MS), integrating eight publicly available microarray datasets from Peripheral Blood Mononuclear Cells (PBMC). After robust preprocessing we trained an XGBoost classifier optimized via Bayesian search. SHapley Additive exPlanations (SHAP) were used to identify key features for model prediction, indicating thus possible biomarkers. These were compared with genes identified through classical Differential Expression Analysis (DEA). Our comparison revealed both overlapping and unique biomarkers between SHAP and DEA, suggesting complementary strengths. Enrichment analysis confirmed the biological relevance of SHAP-selected genes, linking them to pathways such as sphingolipid signaling, Th1/Th2/Th17 cell differentiation, and Epstein-Barr virus infection all known to be associated with MS. This study highlights the value of combining explainable AI (xAI) with traditional statistical methods to gain deeper insights into disease mechanism.
PD-L1 Classification of Weakly-Labeled Whole Slide Images of Breast Cancer
Apr 15, 2024



Specific and effective breast cancer therapy relies on the accurate quantification of PD-L1 positivity in tumors, which appears in the form of brown stainings in high resolution whole slide images (WSIs). However, the retrieval and extensive labeling of PD-L1 stained WSIs is a time-consuming and challenging task for pathologists, resulting in low reproducibility, especially for borderline images. This study aims to develop and compare models able to classify PD-L1 positivity of breast cancer samples based on WSI analysis, relying only on WSI-level labels. The task consists of two phases: identifying regions of interest (ROI) and classifying tumors as PD-L1 positive or negative. For the latter, two model categories were developed, with different feature extraction methodologies. The first encodes images based on the colour distance from a base color. The second uses a convolutional autoencoder to obtain embeddings of WSI tiles, and aggregates them into a WSI-level embedding. For both model types, features are fed into downstream ML classifiers. Two datasets from different clinical centers were used in two different training configurations: (1) training on one dataset and testing on the other; (2) combining the datasets. We also tested the performance with or without human preprocessing to remove brown artefacts Colour distance based models achieve the best performances on testing configuration (1) with artefact removal, while autoencoder-based models are superior in the remaining cases, which are prone to greater data variability.
Home and destination attachment: study of cultural integration on Twitter
Feb 22, 2021

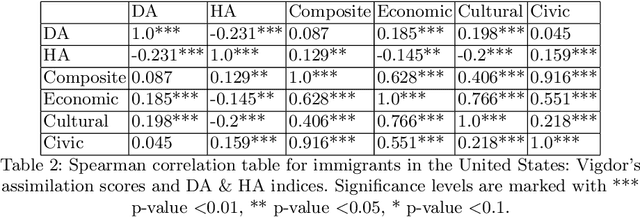

The cultural integration of immigrants conditions their overall socio-economic integration as well as natives' attitudes towards globalisation in general and immigration in particular. At the same time, excessive integration -- or acculturation -- can be detrimental in that it implies forfeiting one's ties to the home country and eventually translates into a loss of diversity (from the viewpoint of host countries) and of global connections (from the viewpoint of both host and home countries). Cultural integration can be described using two dimensions: the preservation of links to the home country and culture, which we call home attachment, and the creation of new links together with the adoption of cultural traits from the new residence country, which we call destination attachment. In this paper we introduce a means to quantify these two aspects based on Twitter data. We build home and destination attachment indexes and analyse their possible determinants (e.g., language proximity, distance between countries), also in relation to Hofstede's cultural dimension scores. The results stress the importance of host language proficiency to explain destination attachment, but also the link between language and home attachment. In particular, the common language between home and destination countries corresponds to increased home attachment, as does low proficiency in the host language. Common geographical borders also seem to increase both home and destination attachment. Regarding cultural dimensions, larger differences among home and destination country in terms of Individualism, Masculinity and Uncertainty appear to correspond to larger destination attachment and lower home attachment.
Towards Data-Driven Autonomics in Data Centers
Jul 06, 2015
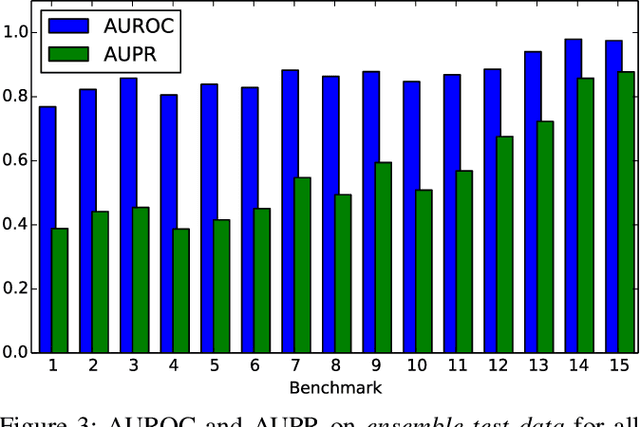

Continued reliance on human operators for managing data centers is a major impediment for them from ever reaching extreme dimensions. Large computer systems in general, and data centers in particular, will ultimately be managed using predictive computational and executable models obtained through data-science tools, and at that point, the intervention of humans will be limited to setting high-level goals and policies rather than performing low-level operations. Data-driven autonomics, where management and control are based on holistic predictive models that are built and updated using generated data, opens one possible path towards limiting the role of operators in data centers. In this paper, we present a data-science study of a public Google dataset collected in a 12K-node cluster with the goal of building and evaluating a predictive model for node failures. We use BigQuery, the big data SQL platform from the Google Cloud suite, to process massive amounts of data and generate a rich feature set characterizing machine state over time. We describe how an ensemble classifier can be built out of many Random Forest classifiers each trained on these features, to predict if machines will fail in a future 24-hour window. Our evaluation reveals that if we limit false positive rates to 5%, we can achieve true positive rates between 27% and 88% with precision varying between 50% and 72%. We discuss the practicality of including our predictive model as the central component of a data-driven autonomic manager and operating it on-line with live data streams (rather than off-line on data logs). All of the scripts used for BigQuery and classification analyses are publicly available from the authors' website.