 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECICE: Device-Edge-Cloud Intelligent Collaboration Framework
May 04, 2023



DECICE is a Horizon Europe project that is developing an AI-enabled open and portable management framework for automatic and adaptive optimization and deployment of applications in computing continuum encompassing from IoT sensors on the Edge to large-scale Cloud / HPC computing infrastructures. In this paper, we describe the DECICE framework and architecture. Furthermore, we highlight use-cases for framework evaluation: intelligent traffic intersection, magnetic resonance imaging, and emergency response.
Data-driven Real-time Short-term Prediction of Air Quality: Comparison of ES, ARIMA, and LSTM
Nov 16, 2022Air pollution is a worldwide issue that affects the lives of many people in urban areas. It is considered that the air pollution may lead to heart and lung diseases. A careful and timely forecast of the air quality could help to reduce the exposure risk for affected people. In this paper, we use a data-driven approach to predict air quality based on historical data. We compare three popular methods for time series prediction: Exponential Smoothing (ES), Auto-Regressive Integrated Moving Average (ARIMA) and Long short-term memory (LSTM). Considering prediction accuracy and time complexity, our experiments reveal that for short-term air pollution prediction ES performs better than ARIMA and LSTM.
Optimization of Heterogeneous Systems with AI Planning Heuristics and Machine Learning: A Performance and Energy Aware Approach
Jun 02, 2021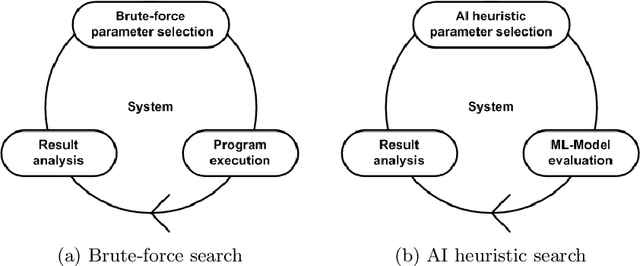

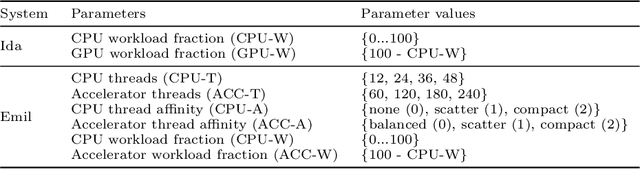
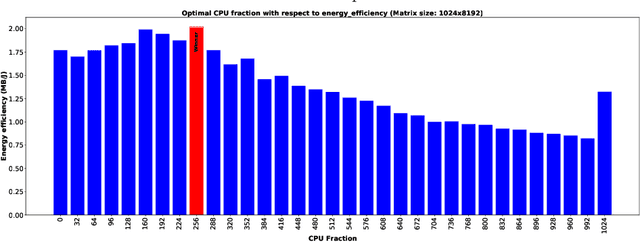
Heterogeneous computing systems provide high performance and energy efficiency. However, to optimally utilize such systems, solutions that distribute the work across host CPUs and accelerating devices are needed. In this paper, we present a performance and energy aware approach that combines AI planning heuristics for parameter space exploration with a machine learning model for performance and energy evaluation to determine a near-optimal system configuration. For data-parallel applications our approach determines a near-optimal host-device distribution of work, number of processing units required and the corresponding scheduling strategy. We evaluate our approach for various heterogeneous systems accelerated with GPU or the Intel Xeon Phi. The experimental results demonstrate that our approach finds a near-optimal system configuration by evaluating only about 7% of reasonable configurations. Furthermore, the performance per Joule estimation of system configurations using our machine learning model is more than 1000x faster compared to the system evaluation by program execution.
Performance Modelling of Deep Learning on Intel Many Integrated Core Architectures
Jun 04, 2019
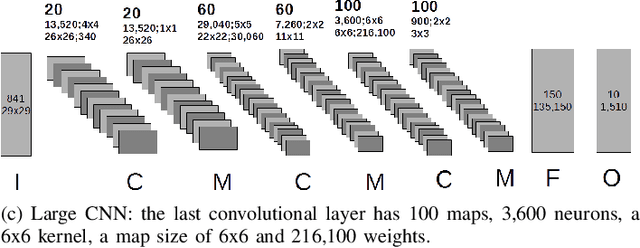
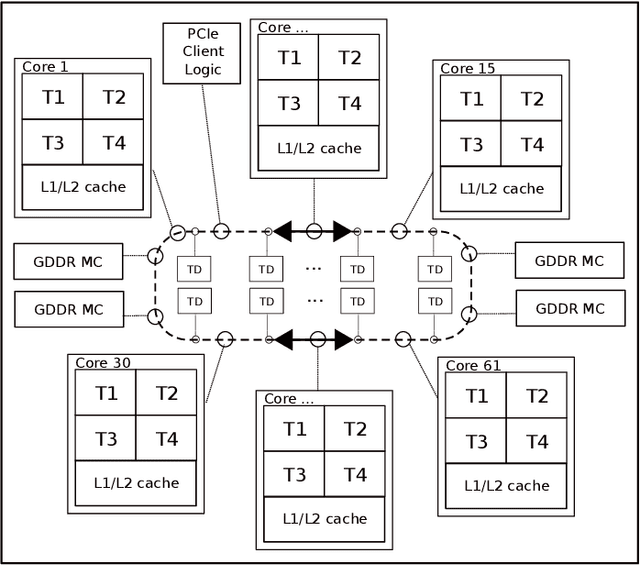
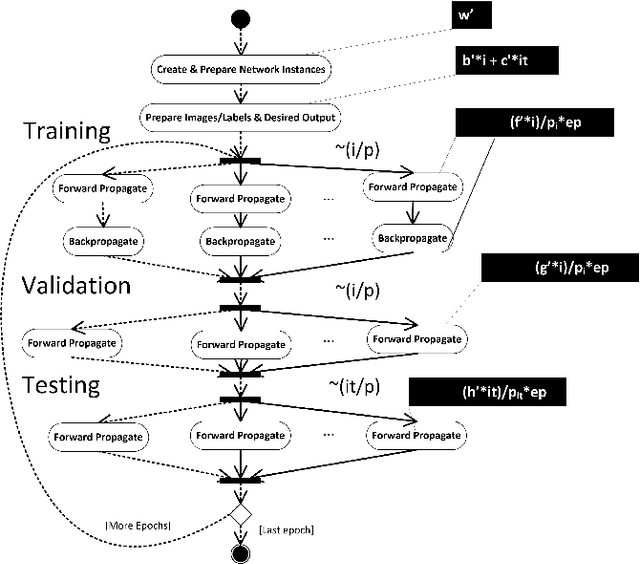
Many complex problems, such as natural language processing or visual object detection, are solved using deep learning. However, efficient training of complex deep convolutional neural networks for large data sets is computationally demanding and requires parallel computing resources. In this paper, we present two parameterized performance models for estimation of execution time of training convolutional neural networks on the Intel many integrated core architecture. While for the first performance model we minimally use measurement techniques for parameter value estimation, in the second model we estimate more parameters based on measurements. We evaluate the prediction accuracy of performance models in the context of training three different convolutional neural network architectures on the Intel Xeon Phi. The achieved average performance prediction accuracy is about 15% for the first model and 11% for second model.
Customizing Pareto Simulated Annealing for Multi-objective Optimization of Control Cabinet Layout
Jun 04, 2019
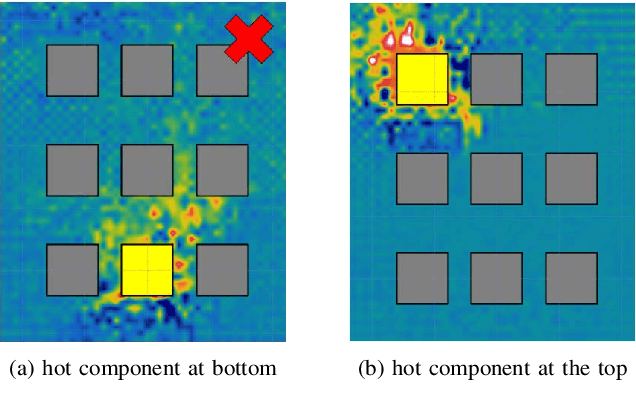
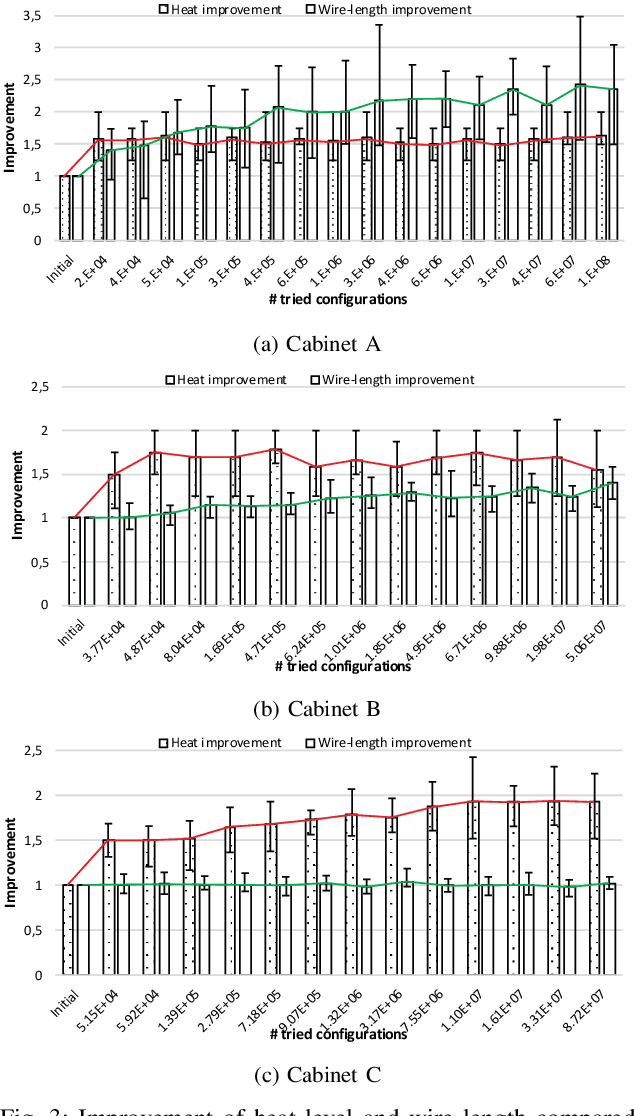
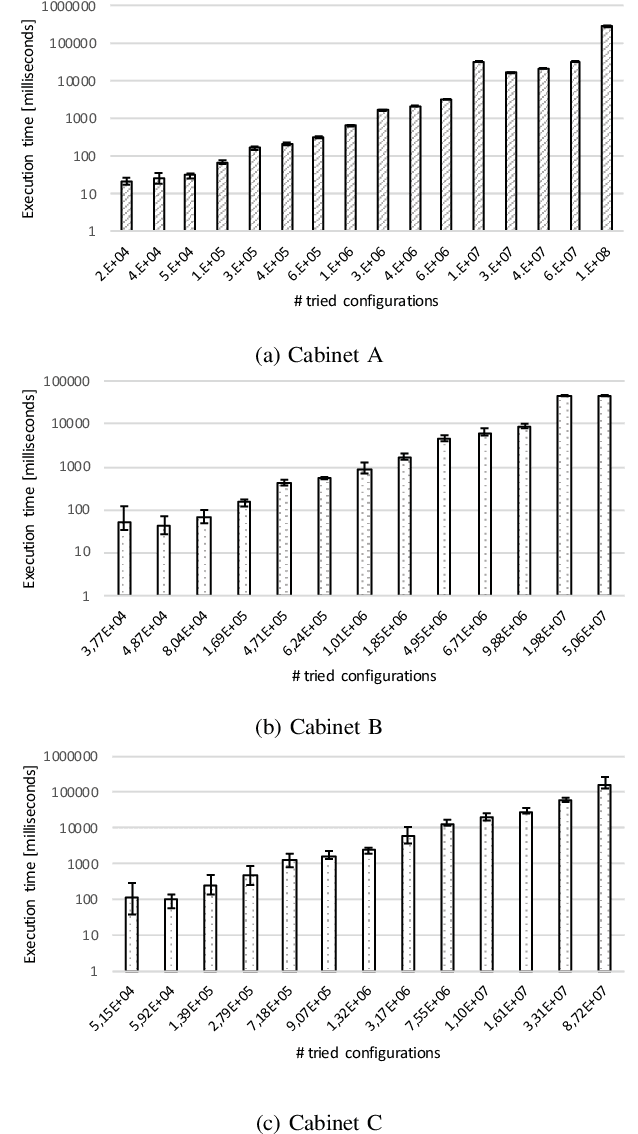
Determining the optimal location of control cabinet components requires the exploration of a large configuration space. For real-world control cabinets it is impractical to evaluate all possible cabinet configurations. Therefore, we need to apply methods for intelligent exploration of cabinet configuration space that enable to find a near-optimal configuration without evaluation of all possible configurations. In this paper, we describe an approach for multi-objective optimization of control cabinet layout that is based on Pareto Simulated Annealing. Optimization aims at minimizing the total wire length used for interconnection of components and the heat convection within the cabinet. We simulate heat convection to study the warm air flow within the control cabinet and determine the optimal position of components that generate heat during the operation. We evaluate and demonstrate the effectiveness of our approach empirically for various control cabinet sizes and usage scenarios.
A Machine Learning Driven IoT Solution for Noise Classification in Smart Cities
Sep 01, 2018
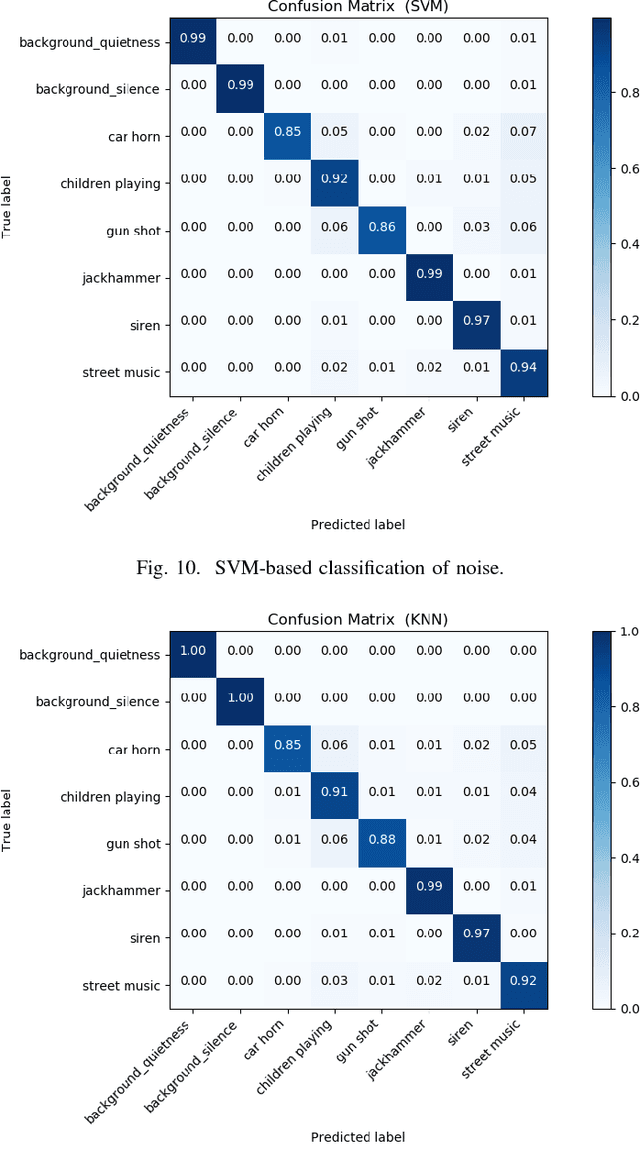
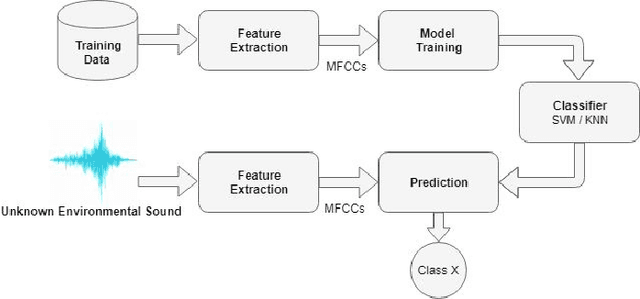
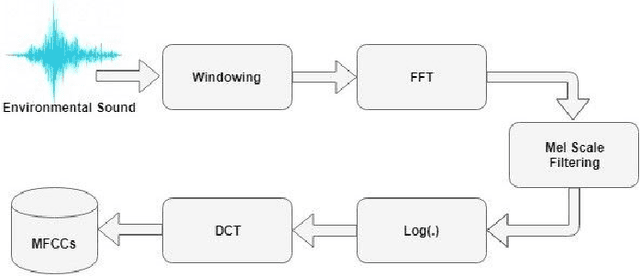
We present a machine learning based method for noise classification using a low-power and inexpensive IoT unit. We use Mel-frequency cepstral coefficients for audio feature extraction and supervised classification algorithms (that is, support vector machine and k-nearest neighbors) for noise classification. We evaluate our approach experimentally with a dataset of about 3000 sound samples grouped in eight sound classes (such as, car horn, jackhammer, or street music). We explore the parameter space of support vector machine and k-nearest neighbors algorithms to estimate the optimal parameter values for classification of sound samples in the dataset under study. We achieve a noise classification accuracy in the range 85% -- 100%. Training and testing of our k-nearest neighbors (k = 1) implementation on Raspberry Pi Zero W is less than a second for a dataset with features of more than 3000 sound samples.
CHAOS: A Parallelization Scheme for Training Convolutional Neural Networks on Intel Xeon Phi
Feb 25, 2017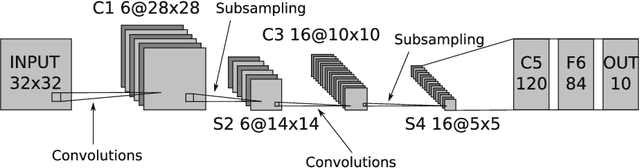

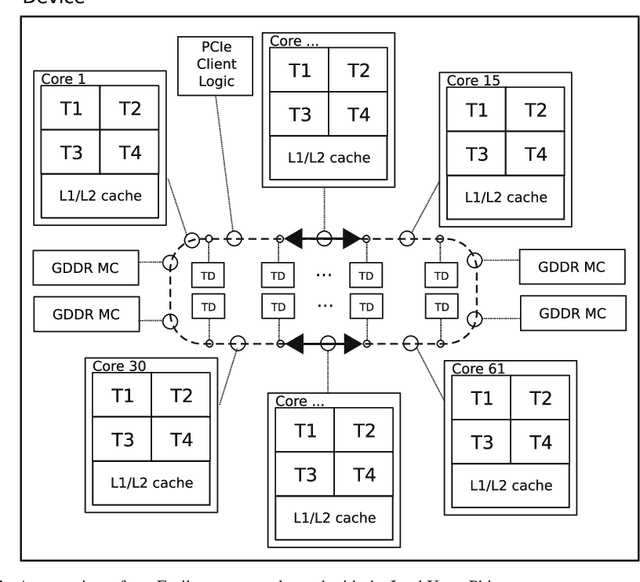
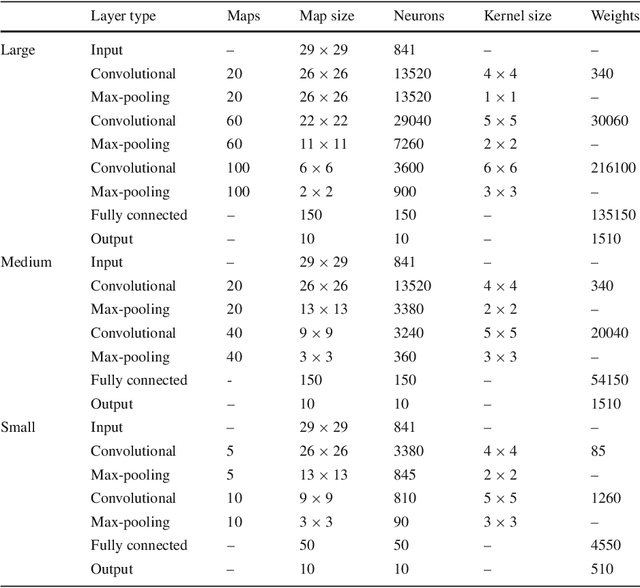
Deep learning is an important component of big-data analytic tools and intelligent applications, such as, self-driving cars, computer vision, speech recognition, or precision medicine. However, the training process is computationally intensive, and often requires a large amount of time if performed sequentially. Modern parallel computing systems provide the capability to reduce the required training time of deep neural networks. In this paper, we present our parallelization scheme for training convolutional neural networks (CNN) named Controlled Hogwild with Arbitrary Order of Synchronization (CHAOS). Major features of CHAOS include the support for thread and vector parallelism, non-instant updates of weight parameters during back-propagation without a significant delay, and implicit synchronization in arbitrary order. CHAOS is tailored for parallel computing systems that are accelerated with the Intel Xeon Phi. We evaluate our parallelization approach empirically using measurement techniques and performance modeling for various numbers of threads and CNN architectures. Experimental results for the MNIST dataset of handwritten digits using the total number of threads on the Xeon Phi show speedups of up to 103x compared to the execution on one thread of the Xeon Phi, 14x compared to the sequential execution on Intel Xeon E5, and 58x compared to the sequential execution on Intel Core i5.