 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHAOS: A Parallelization Scheme for Training Convolutional Neural Networks on Intel Xeon Phi
Paper and Code
Feb 25, 2017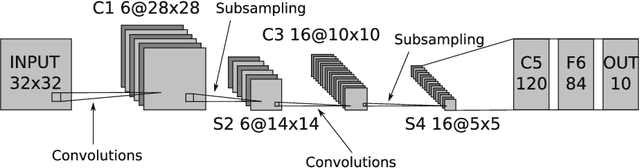

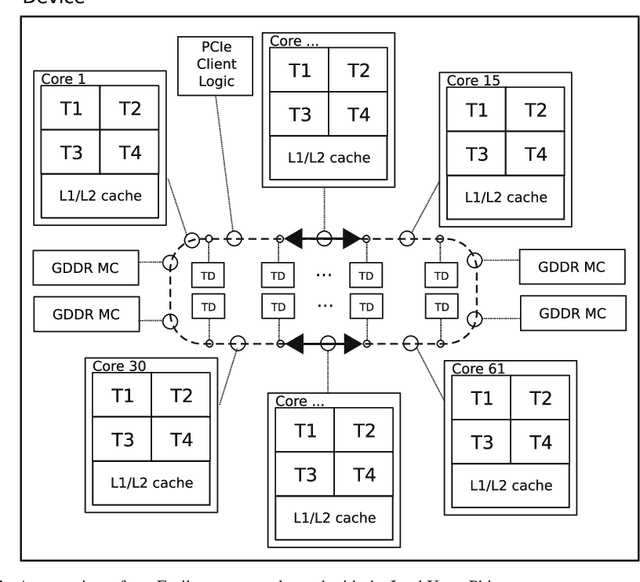
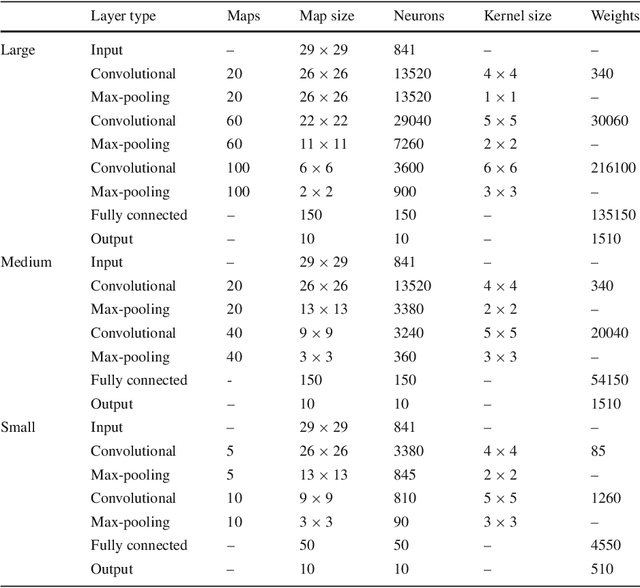
Deep learning is an important component of big-data analytic tools and intelligent applications, such as, self-driving cars, computer vision, speech recognition, or precision medicine. However, the training process is computationally intensive, and often requires a large amount of time if performed sequentially. Modern parallel computing systems provide the capability to reduce the required training time of deep neural networks. In this paper, we present our parallelization scheme for training convolutional neural networks (CNN) named Controlled Hogwild with Arbitrary Order of Synchronization (CHAOS). Major features of CHAOS include the support for thread and vector parallelism, non-instant updates of weight parameters during back-propagation without a significant delay, and implicit synchronization in arbitrary order. CHAOS is tailored for parallel computing systems that are accelerated with the Intel Xeon Phi. We evaluate our parallelization approach empirically using measurement techniques and performance modeling for various numbers of threads and CNN architectures. Experimental results for the MNIST dataset of handwritten digits using the total number of threads on the Xeon Phi show speedups of up to 103x compared to the execution on one thread of the Xeon Phi, 14x compared to the sequential execution on Intel Xeon E5, and 58x compared to the sequential execution on Intel Core i5.