 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiGer: Self-Supervised Purification for Time-evolving Graphs
Mar 11, 2025Time-evolving graphs, such as social and citation networks, often contain noise that distorts structural and temporal patterns, adversely affecting downstream tasks, such as node classification. Existing purification methods focus on static graphs, limiting their ability to account for critical temporal dependencies in dynamic graphs. In this work, we propose TiGer (Time-evolving Graph purifier), a self-supervised method explicitly designed for time-evolving graphs. TiGer assigns two different sub-scores to edges using (1) self-attention for capturing long-term contextual patterns shaped by both adjacent and distant past events of varying significance and (2) statistical distance measures for detecting inconsistency over a short-term period. These sub-scores are used to identify and filter out suspicious (i.e., noise-like) edges through an ensemble strategy, ensuring robustness without requiring noise labels. Our experiments on five real-world datasets show TiGer filters out noise with up to 10.2% higher accuracy and improves node classification performance by up to 5.3%, compared to state-of-the-art methods.
DiffIM: Differentiable Influence Minimization with Surrogate Modeling and Continuous Relaxation
Feb 03, 2025In social networks, people influence each other through social links, which can be represented as propagation among nodes in graphs. Influence minimization (IMIN) is the problem of manipulating the structures of an input graph (e.g., removing edges) to reduce the propagation among nodes. IMIN can represent time-critical real-world applications, such as rumor blocking, but IMIN is theoretically difficult and computationally expensive. Moreover, the discrete nature of IMIN hinders the usage of powerful machine learning techniques, which requires differentiable computation. In this work, we propose DiffIM, a novel method for IMIN with two differentiable schemes for acceleration: (1) surrogate modeling for efficient influence estimation, which avoids time-consuming simulations (e.g., Monte Carlo), and (2) the continuous relaxation of decisions, which avoids the evaluation of individual discrete decisions (e.g., removing an edge). We further propose a third accelerating scheme, gradient-driven selection, that chooses edges instantly based on gradients without optimization (spec., gradient descent iterations) on each test instance. Through extensive experiments on real-world graphs, we show that each proposed scheme significantly improves speed with little (or even no) IMIN performance degradation. Our method is Pareto-optimal (i.e., no baseline is faster and more effective than it) and typically several orders of magnitude (spec., up to 15,160X) faster than the most effective baseline while being more effective.
On Measuring Unnoticeability of Graph Adversarial Attacks: Observations, New Measure, and Applications
Jan 09, 2025



Adversarial attacks are allegedly unnoticeable. Prior studies have designed attack noticeability measures on graphs, primarily using statistical tests to compare the topology of original and (possibly) attacked graphs. However, we observe two critical limitations in the existing measures. First, because the measures rely on simple rules, attackers can readily enhance their attacks to bypass them, reducing their attack "noticeability" and, yet, maintaining their attack performance. Second, because the measures naively leverage global statistics, such as degree distributions, they may entirely overlook attacks until severe perturbations occur, letting the attacks be almost "totally unnoticeable." To address the limitations, we introduce HideNSeek, a learnable measure for graph attack noticeability. First, to mitigate the bypass problem, HideNSeek learns to distinguish the original and (potential) attack edges using a learnable edge scorer (LEO), which scores each edge on its likelihood of being an attack. Second, to mitigate the overlooking problem, HideNSeek conducts imbalance-aware aggregation of all the edge scores to obtain the final noticeability score. Using six real-world graphs, we empirically demonstrate that HideNSeek effectively alleviates the observed limitations, and LEO (i.e., our learnable edge scorer) outperforms eleven competitors in distinguishing attack edges under five different attack methods. For an additional application, we show that LEO boost the performance of robust GNNs by removing attack-like edges.
Rethinking Reconstruction-based Graph-Level Anomaly Detection: Limitations and a Simple Remedy
Oct 27, 2024Graph autoencoders (Graph-AEs) learn representations of given graphs by aiming to accurately reconstruct them. A notable application of Graph-AEs is graph-level anomaly detection (GLAD), whose objective is to identify graphs with anomalous topological structures and/or node features compared to the majority of the graph population. Graph-AEs for GLAD regard a graph with a high mean reconstruction error (i.e. mean of errors from all node pairs and/or nodes) as anomalies. Namely, the methods rest on the assumption that they would better reconstruct graphs with similar characteristics to the majority. We, however, report non-trivial counter-examples, a phenomenon we call reconstruction flip, and highlight the limitations of the existing Graph-AE-based GLAD methods. Specifically, we empirically and theoretically investigate when this assumption holds and when it fails. Through our analyses, we further argue that, while the reconstruction errors for a given graph are effective features for GLAD, leveraging the multifaceted summaries of the reconstruction errors, beyond just mean, can further strengthen the features. Thus, we propose a novel and simple GLAD method, named MUSE. The key innovation of MUSE involves taking multifaceted summaries of reconstruction errors as graph features for GLAD. This surprisingly simple method obtains SOTA performance in GLAD, performing best overall among 14 methods across 10 datasets.
Exploring Edge Probability Graph Models Beyond Edge Independency: Concepts, Analyses, and Algorithms
May 26, 2024Desirable random graph models (RGMs) should (i) be tractable so that we can compute and control graph statistics, and (ii) generate realistic structures such as high clustering (i.e., high subgraph densities). A popular category of RGMs (e.g., Erdos-Renyi and stochastic Kronecker) outputs edge probabilities, and we need to realize (i.e., sample from) the edge probabilities to generate graphs. Typically, each edge (in)existence is assumed to be determined independently. However, with edge independency, RGMs theoretically cannot produce high subgraph densities unless they "replicate" input graphs. In this work, we explore realization beyond edge independence that can produce more realistic structures while ensuring high tractability. Specifically, we propose edge-dependent realization schemes called binding and derive closed-form tractability results on subgraph (e.g., triangle) densities in graphs generated with binding. We propose algorithms for graph generation with binding and parameter fitting of binding. We empirically validate that binding exhibits high tractability and generates realistic graphs with high clustering, significantly improving upon existing RGMs assuming edge independency.
Tackling Prevalent Conditions in Unsupervised Combinatorial Optimization: Cardinality, Minimum, Covering, and More
May 14, 2024
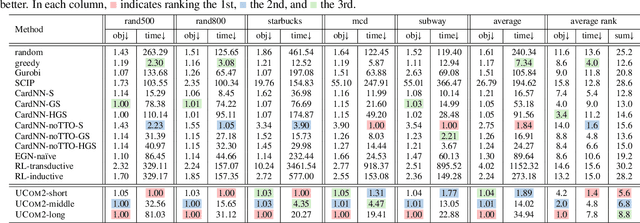
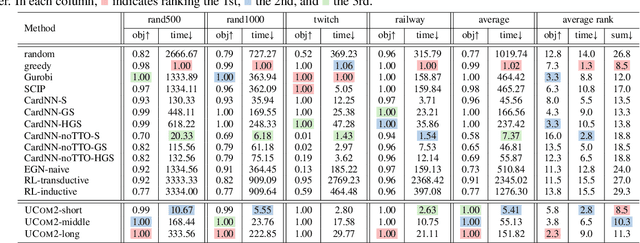

Combinatorial optimization (CO) is naturally discrete, making machine learning based on differentiable optimization inapplicable. Karalias & Loukas (2020) adapted the probabilistic method to incorporate CO into differentiable optimization. Their work ignited the research on unsupervised learning for CO, composed of two main components: probabilistic objectives and derandomization. However, each component confronts unique challenges. First, deriving objectives under various conditions (e.g., cardinality constraints and minimum) is nontrivial. Second, the derandomization process is underexplored, and the existing derandomization methods are either random sampling or naive rounding. In this work, we aim to tackle prevalent (i.e., commonly involved) conditions in unsupervised CO. First, we concretize the targets for objective construction and derandomization with theoretical justification. Then, for various conditions commonly involved in different CO problems, we derive nontrivial objectives and derandomization to meet the targets. Finally, we apply the derivations to various CO problems. Via extensive experiments on synthetic and real-world graphs, we validate the correctness of our derivations and show our empirical superiority w.r.t. both optimization quality and speed.
HypeBoy: Generative Self-Supervised Representation Learning on Hypergraphs
Mar 31, 2024



Hypergraphs are marked by complex topology, expressing higher-order interactions among multiple nodes with hyperedges, and better capturing the topology is essential for effective representation learning. Recent advances in generative self-supervised learning (SSL) suggest that hypergraph neural networks learned from generative self supervision have the potential to effectively encode the complex hypergraph topology. Designing a generative SSL strategy for hypergraphs, however, is not straightforward. Questions remain with regard to its generative SSL task, connection to downstream tasks, and empirical properties of learned representations. In light of the promises and challenges, we propose a novel generative SSL strategy for hypergraphs. We first formulate a generative SSL task on hypergraphs, hyperedge filling, and highlight its theoretical connection to node classification. Based on the generative SSL task, we propose a hypergraph SSL method, HypeBoy. HypeBoy learns effective general-purpose hypergraph representations, outperforming 16 baseline methods across 11 benchmark datasets.
Feature Distribution on Graph Topology Mediates the Effect of Graph Convolution: Homophily Perspective
Feb 07, 2024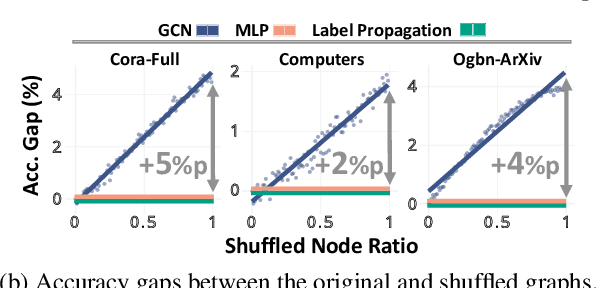
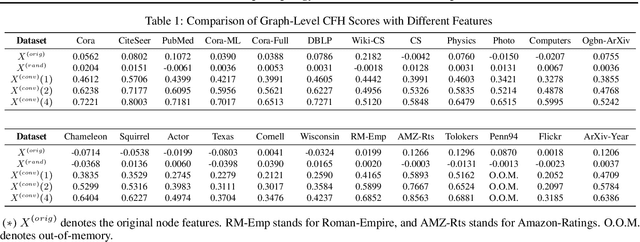
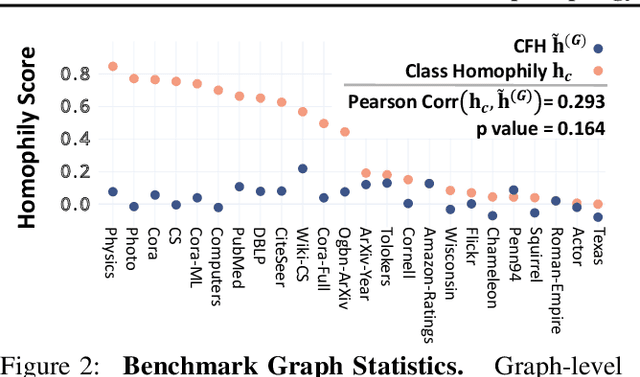
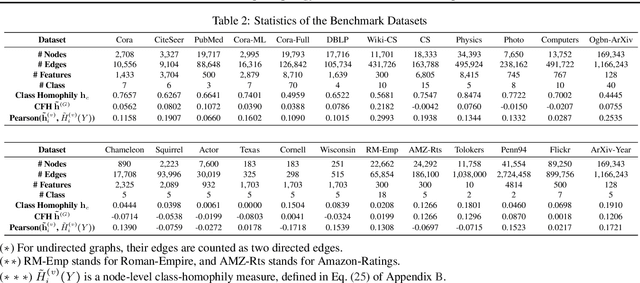
How would randomly shuffling feature vectors among nodes from the same class affect graph neural networks (GNNs)? The feature shuffle, intuitively, perturbs the dependence between graph topology and features (A-X dependence) for GNNs to learn from. Surprisingly, we observe a consistent and significant improvement in GNN performance following the feature shuffle. Having overlooked the impact of A-X dependence on GNNs, the prior literature does not provide a satisfactory understanding of the phenomenon. Thus, we raise two research questions. First, how should A-X dependence be measured, while controlling for potential confounds? Second, how does A-X dependence affect GNNs? In response, we (i) propose a principled measure for A-X dependence, (ii) design a random graph model that controls A-X dependence, (iii) establish a theory on how A-X dependence relates to graph convolution, and (iv) present empirical analysis on real-world graphs that aligns with the theory. We conclude that A-X dependence mediates the effect of graph convolution, such that smaller dependence improves GNN-based node classification.
Robust Graph Clustering via Meta Weighting for Noisy Graphs
Nov 08, 2023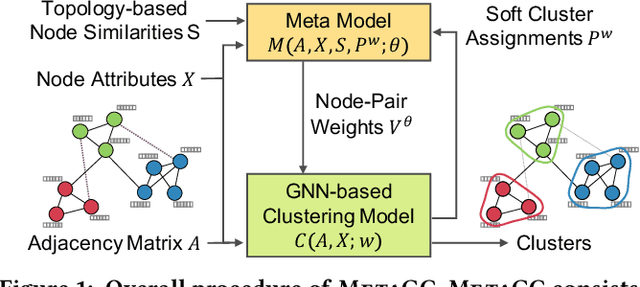
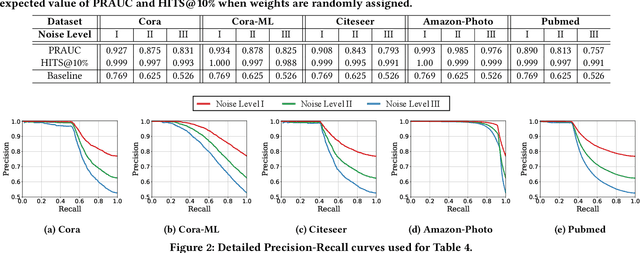
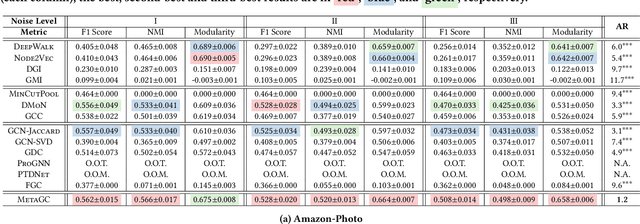
How can we find meaningful clusters in a graph robustly against noise edges? Graph clustering (i.e., dividing nodes into groups of similar ones) is a fundamental problem in graph analysis with applications in various fields. Recent studies have demonstrated that graph neural network (GNN) based approaches yield promising results for graph clustering. However, we observe that their performance degenerates significantly on graphs with noise edges, which are prevalent in practice. In this work, we propose MetaGC for robust GNN-based graph clustering. MetaGC employs a decomposable clustering loss function, which can be rephrased as a sum of losses over node pairs. We add a learnable weight to each node pair, and MetaGC adaptively adjusts the weights of node pairs using meta-weighting so that the weights of meaningful node pairs increase and the weights of less-meaningful ones (e.g., noise edges) decrease. We show empirically that MetaGC learns weights as intended and consequently outperforms the state-of-the-art GNN-based competitors, even when they are equipped with separate denoising schemes, on five real-world graphs under varying levels of noise. Our code and datasets are available at https://github.com/HyeonsooJo/MetaGC.
Towards Deep Attention in Graph Neural Networks: Problems and Remedies
Jun 04, 2023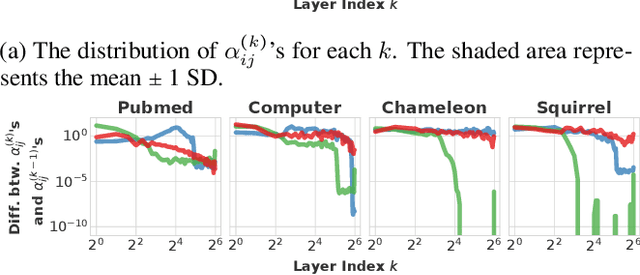

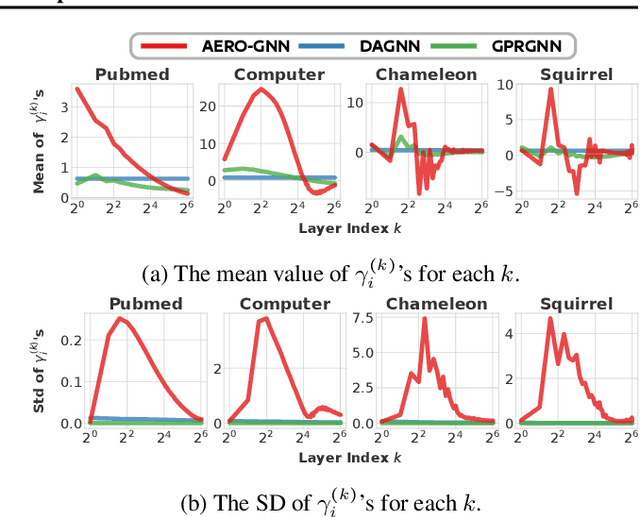
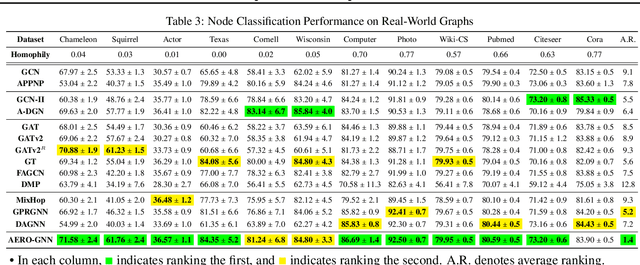
Graph neural networks (GNNs) learn the representation of graph-structured data, and their expressiveness can be further enhanced by inferring node relations for propagation. Attention-based GNNs infer neighbor importance to manipulate the weight of its propagation. Despite their popularity, the discussion on deep graph attention and its unique challenges has been limited. In this work, we investigate some problematic phenomena related to deep graph attention, including vulnerability to over-smoothed features and smooth cumulative attention. Through theoretical and empirical analyses, we show that various attention-based GNNs suffer from these problems. Motivated by our findings, we propose AEROGNN, a novel GNN architecture designed for deep graph attention. AERO-GNN provably mitigates the proposed problems of deep graph attention, which is further empirically demonstrated with (a) its adaptive and less smooth attention functions and (b) higher performance at deep layers (up to 64). On 9 out of 12 node classification benchmarks, AERO-GNN outperforms the baseline GNNs, highlighting the advantages of deep graph attention. Our code is available at https://github.com/syleeheal/AERO-GNN.